根据提示,在右侧编辑器Begin-End区间补充代码,实现将file_1和file_2文件中的数字,按从小到大的顺序排序,并将结果写入file_3文件中。 提示:可以新建空列表,将读取的文件内容通过extend方法,添加到空列表,通过sort排序,然后将列表写入file_3文件。
时间: 2023-12-05 18:06:36 浏览: 324
```python
with open("file_1.txt", "r") as f1, open("file_2.txt", "r") as f2, open("file_3.txt", "w") as f3:
# 读取文件内容并添加到空列表中
lst = []
lst.extend(f1.read().split())
lst.extend(f2.read().split())
# 将列表中的元素转换成整数类型并排序
lst = sorted([int(x) for x in lst])
# 将排序后的结果写入file_3文件中
for i in lst:
f3.write(str(i) + "\n")
```
注:假设file_1.txt和file_2.txt中每行都只包含一个数字。
相关问题
根据提示以及示例,在右侧编辑器 Begin-End 区间补充代码,完善函数 get_data(),批量爬取古诗词作者。src/step1/test.html 为爬取网页的效果代码,可以使用开发者工具审查元素,获取 XPath 的路径信息
为了帮助您完成这个任务,我们需要先了解一下HTML结构和XPath的选择器。在这个场景中,我们假设 `test.html` 文件包含了一个列表,其中包含古诗词作者的信息,每个作者的信息都存储在一个类似 `<li>` 的元素内。以下是一个简单的代码框架,展示了如何使用Python的BeautifulSoup库来抓取这些数据:
```python
import requests
from bs4 import BeautifulSoup
def get_data():
# 发送请求获取页面内容
url = "file:///path/to/src/step1/test.html" # 将这里的URL替换为实际文件路径
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 使用XPath选择器找到所有包含作者信息的元素
authors_xpath = ".//li[contains(@class, 'author')]"
# 找到并存储作者列表
authors_list = soup.select(authors_xpath)
# 定义一个空列表来保存结果
authors = []
# 遍历每个作者元素
for author_element in authors_list:
# 提取作者名称
author_name = author_element.find('span', class_='name').text
# 添加到结果列表
authors.append(author_name)
return authors
else:
print("Failed to fetch the data.")
return None
# 调用函数并打印结果
authors = get_data()
if authors:
for i, author in enumerate(authors, start=1):
print(f"{i}. {author}")
请在右侧编辑器Begin-End处补充代码,读取def studen(file_name)函数中file_name文件的内容,将其转换为结构化数组并筛选年龄在10岁之上的平均score,要求结果保留一位小数位即可。 file_name文件的 格式如下(数据并非下表中展示数据): name age score Emma 11 70 Edith 12 80
好的,您可以使用如下Python代码实现:
```python
import numpy as np
def student(file_name):
data = np.genfromtxt(file_name, delimiter='\t', dtype=[('name', 'U10'), ('age', int), ('score', float)])
mask = data['age'] >= 10
avg_score = round(np.mean(data['score'][mask]), 1)
return avg_score
```
首先,我们使用NumPy库中的`genfromtxt()`函数读取文件`file_name`,并指定分隔符为制表符`\t`,数据类型为一个由三个元素组成的元组,分别是姓名(字符串类型)、年龄(整数类型)和分数(浮点数类型)。然后,我们使用布尔掩码`mask`筛选出年龄在10岁及以上的学生,并使用NumPy库中的`mean()`函数计算这些学生的平均分数,并通过`round()`函数保留一位小数。最后,我们将平均分数作为函数的返回值。
阅读全文
相关推荐
大家在看
dmx512无线舞台灯光系统
DMX512协议是由美国舞台灯光协会(USITT)提出了一种数据调光协议,它给出了一种灯光控制器与灯具设备之间通信的协议标准,因其在1990年提出,所以协议的全称是USITTDMX512(1990)。该协议的提出为使用数字信号控制灯光设备提供了一个良好的标准。
传统dmx512控制器使用rs-485有线协议通信,此方案使用无线2.4G替代rs485,有无需布线的优点并且可以在手机或者电脑上设置预设的灯光效果
SIMATIC S71200和1500安全编程指南
SIMATIC S71200和1500安全编程指南
INCA用的A2L文件生成脚本
INCA用的A2L文件生成脚本
计算机组成原理课程设计复杂模型机设计实现冒泡排序
本项目基于计算机组成原理课程实现课程设计,使用复杂模型机,任选题目进行。
本资源选择的是实现冒泡排序算法,报告含有项目任务,总体思路,技术路线,可行性分析,复杂模型机,项目内容,项目实施,项目成果,项目总结,参考文献。本报告可以直接使用,格式已经调好。
项目成果含有线路连接图,机器码展示和项目结果。
CMOS反相器的掩膜版图-集成电路版图设计
CMOS反相器的掩膜版图
场SiO2
栅SiO2
栅SiO2
最新推荐
rip宣告网段选择版本
rip宣告网段选择版本
基于springboot+vue的学生选课系统(Java毕业设计,附源码,部署教程).zip
该项目包含完整的前后端代码、数据库脚本和相关工具,简单部署即可运行。功能完善、界面美观、操作简单,具有很高的实际应用价值,非常适合作为Java毕业设计或Java课程设计使用。
所有项目均经过严格调试,确保可运行!下载后即可快速部署和使用。
1 适用场景:
毕业设计
期末大作业
课程设计
2 项目特点:
代码完整:详细代码注释,适合新手学习和使用
功能强大:涵盖常见的核心功能,满足大部分课程设计需求
部署简单:有基础的人,只需按照教程操作,轻松完成本地或服务器部署
高质量代码:经过严格测试,确保无错误,稳定运行
3 技术栈和工具
前端:HTML + Vue.js
后端框架:Spring Boot
开发环境:IntelliJ IDEA
数据库:MySQL(建议使用 5.7 版本,更稳定)
数据库可视化工具:Navicat
部署环境:Tomcat(推荐 7.x 或 8.x 版本),Maven
探索zinoucha-master中的0101000101奥秘
资源摘要信息:"zinoucha:101000101"
根据提供的文件信息,我们可以推断出以下几个知识点:
1. 文件标题 "zinoucha:101000101" 中的 "zinoucha" 可能是某种特定内容的标识符或是某个项目的名称。"101000101" 则可能是该项目或内容的特定代码、版本号、序列号或其他重要标识。鉴于标题的特殊性,"zinoucha" 可能是一个与数字序列相关联的术语或项目代号。
2. 描述中提供的 "日诺扎 101000101" 可能是标题的注释或者补充说明。"日诺扎" 的含义并不清晰,可能是人名、地名、特殊术语或是一种加密/编码信息。然而,由于描述与标题几乎一致,这可能表明 "日诺扎" 和 "101000101" 是紧密相关联的。如果 "日诺扎" 是一个密码或者编码,那么 "101000101" 可能是其二进制编码形式或经过某种特定算法转换的结果。
3. 标签部分为空,意味着没有提供额外的分类或关键词信息,这使得我们无法通过标签来获取更多关于该文件或项目的信息。
4. 文件名称列表中只有一个文件名 "zinoucha-master"。从这个文件名我们可以推测出一些信息。首先,它表明了这个项目或文件属于一个更大的项目体系。在软件开发中,通常会将主分支或主线版本命名为 "master"。所以,"zinoucha-master" 可能指的是这个项目或文件的主版本或主分支。此外,由于文件名中同样包含了 "zinoucha",这进一步确认了 "zinoucha" 对该项目的重要性。
结合以上信息,我们可以构建以下几个可能的假设场景:
- 假设 "zinoucha" 是一个项目名称,那么 "101000101" 可能是该项目的某种特定标识,例如版本号或代码。"zinoucha-master" 作为主分支,意味着它包含了项目的最稳定版本,或者是开发的主干代码。
- 假设 "101000101" 是某种加密或编码,"zinoucha" 和 "日诺扎" 都可能是对其进行解码或解密的钥匙。在这种情况下,"zinoucha-master" 可能包含了用于解码或解密的主算法或主程序。
- 假设 "zinoucha" 和 "101000101" 代表了某种特定的数据格式或标准。"zinoucha-master" 作为文件名,可能意味着这是遵循该标准或格式的最核心文件或参考实现。
由于文件信息非常有限,我们无法确定具体的领域或背景。"zinoucha" 和 "日诺扎" 可能是任意领域的术语,而 "101000101" 作为二进制编码,可能在通信、加密、数据存储等多种IT应用场景中出现。为了获得更精确的知识点,我们需要更多的上下文信息和具体的领域知识。
【Qt与OpenGL集成】:提升框选功能图形性能,OpenGL的高效应用案例
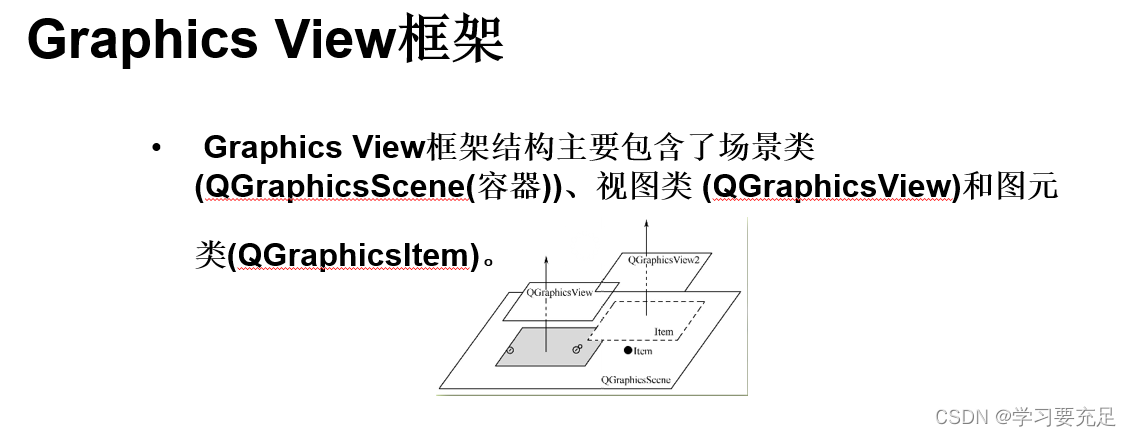
# 摘要
本文旨在探讨Qt与OpenGL集成的实现细节及其在图形性能优化方面的重要性。文章首先介绍了Qt与OpenGL集成的基础知识,然后深入探讨了在Qt环境中实现OpenGL高效渲染的技术,如优化渲染管线、图形数据处理和渲染性能提升策略。接着,文章着重分析了框选功能的图形性能优化,包括图形学原理、高效算法实现以及交互设计。第四章通过高级案例分析,比较了不同的框选技术,并探讨了构
ffmpeg 指定屏幕输出
ffmpeg 是一个强大的多媒体处理工具,可以用来处理视频、音频和字幕等。要使用 ffmpeg 指定屏幕输出,可以使用以下命令:
```sh
ffmpeg -f x11grab -s <width>x<height> -r <fps> -i :<display>.<screen>+<x_offset>,<y_offset> output_file
```
其中:
- `-f x11grab` 指定使用 X11 屏幕抓取输入。
- `-s <width>x<height>` 指定抓取屏幕的分辨率,例如 `1920x1080`。
- `-r <fps>` 指定帧率,例如 `25`。
- `-i
个人网站技术深度解析:Haskell构建、黑暗主题、并行化等
资源摘要信息:"个人网站构建与开发"
### 网站构建与部署工具
1. **Nix-shell**
- Nix-shell 是 Nix 包管理器的一个功能,允许用户在一个隔离的环境中安装和运行特定版本的软件。这在需要特定库版本或者不同开发环境的场景下非常有用。
- 使用示例:`nix-shell --attr env release.nix` 指定了一个 Nix 环境配置文件 `release.nix`,从而启动一个专门的 shell 环境来构建项目。
2. **Nix-env**
- Nix-env 是 Nix 包管理器中的一个命令,用于环境管理和软件包安装。它可以用来安装、更新、删除和切换软件包的环境。
- 使用示例:`nix-env -if release.nix` 表示根据 `release.nix` 文件中定义的环境和依赖,安装或更新环境。
3. **Haskell**
- Haskell 是一种纯函数式编程语言,以其强大的类型系统和懒惰求值机制而著称。它支持高级抽象,并且广泛应用于领域如研究、教育和金融行业。
- 标签信息表明该项目可能使用了 Haskell 语言进行开发。
### 网站功能与技术实现
1. **黑暗主题(Dark Theme)**
- 黑暗主题是一种界面设计,使用较暗的颜色作为背景,以减少对用户眼睛的压力,特别在夜间或低光环境下使用。
- 实现黑暗主题通常涉及CSS中深色背景和浅色文字的设计。
2. **使用openCV生成缩略图**
- openCV 是一个开源的计算机视觉和机器学习软件库,它提供了许多常用的图像处理功能。
- 使用 openCV 可以更快地生成缩略图,通过调用库中的图像处理功能,比如缩放和颜色转换。
3. **通用提要生成(Syndication Feed)**
- 通用提要是 RSS、Atom 等格式的集合,用于发布网站内容更新,以便用户可以通过订阅的方式获取最新动态。
- 实现提要生成通常需要根据网站内容的更新来动态生成相应的 XML 文件。
4. **IndieWeb 互动**
- IndieWeb 是一个鼓励人们使用自己的个人网站来发布内容,而不是使用第三方平台的运动。
- 网络提及(Webmentions)是 IndieWeb 的一部分,它允许网站之间相互提及,类似于社交媒体中的评论和提及功能。
5. **垃圾箱包装/网格系统**
- 垃圾箱包装可能指的是一个用于暂存草稿或未发布内容的功能,类似于垃圾箱回收站。
- 网格系统是一种布局方式,常用于网页设计中,以更灵活的方式组织内容。
6. **画廊/相册/媒体类型/布局**
- 这些关键词可能指向网站上的图片展示功能,包括但不限于相册、网络杂志、不同的媒体展示类型和布局设计。
7. **标签/类别/搜索引擎**
- 这表明网站具有内容分类功能,用户可以通过标签和类别来筛选内容,并且可能内置了简易的搜索引擎来帮助用户快速找到相关内容。
8. **并行化(Parallelization)**
- 并行化在网站开发中通常涉及将任务分散到多个处理单元或线程中执行,以提高效率和性能。
- 这可能意味着网站的某些功能被设计成可以同时处理多个请求,比如后台任务、数据处理等。
9. **草稿版本+实时服务器**
- 草稿版本功能允许用户保存草稿并能在需要时编辑和发布。
- 实时服务器可能是指网站采用了实时数据同步的技术,如 WebSockets,使用户能够看到内容的实时更新。
### 总结
上述信息展示了一个人在个人网站开发过程中所涉及到的技术和功能实现,包括了环境配置、主题设计、内容管理和用户体验优化。从使用Nix-shell进行环境隔离和依赖管理到实现一个具有高级功能和良好用户体验的个人网站,每个技术点都是现代Web开发中的关键组成部分。
Qt框选功能的国际化实践:支持多语言界面的核心技术解析

# 摘要
本文系统地探讨了Qt框架下多语言界面设计与国际化的实现原理和技术细节。首先介绍了Qt国际化框架的基础知识和多语言界面设计的基本原理,包括文本处理、资源文件管理、核心API的应用等。随后,文章详细阐述了设计可翻译用户界面、动态语言切换和界面更新以及测试和调试多语言界面的实践技巧。深入理解
内网如何运行docker pull mysql:5.7
要在内网中运行Docker的pull命令来获取MySQL 5.7镜像,可以按照以下步骤进行操作:
1. 确保在内网中的计算机上安装了Docker。
2. 打开终端或命令提示符,并使用以下命令登录到Docker镜像仓库:
```shell
docker login <repository>
```
将`<repository>`替换为MySQL镜像仓库的地址,例如`mysql`或`docker.io/mysql`。
3. 输入用户名和密码以登录到镜像仓库。
4. 使用以下命令从镜像仓库拉取MySQL 5.7镜像:
```shell
docker pull <repository>/my
ImgToString开源工具:图像转字符串轻松实现
资源摘要信息:"ImgToString是一款开源软件,其主要功能是将图像文件转换为字符串。这种转换方式使得图像文件可以被复制并粘贴到任何支持文本输入的地方,比如文本编辑器、聊天窗口或者网页代码中。通过这种方式,用户无需附加文件即可分享图像信息,尤其适用于在文本模式的通信环境中传输图像数据。"
在技术实现层面,ImgToString可能采用了一种特定的编码算法,将图像文件的二进制数据转换为Base64编码或其他编码格式的字符串。Base64是一种基于64个可打印字符来表示二进制数据的编码方法。由于ASCII字符集只有128个字符,而Base64使用64个字符,因此可以确保转换后的字符串在大多数文本处理环境中能够安全传输,不会因为特殊字符而被破坏。
对于jpg或png等常见的图像文件格式,ImgToString软件需要能够解析这些格式的文件结构,提取图像数据,并进行相应的编码处理。这个过程通常包括读取文件头信息、确定图像尺寸、颜色深度、压缩方式等关键参数,然后根据这些参数将图像的像素数据转换为字符串形式。对于jpg文件,可能还需要处理压缩算法(如JPEG算法)对图像数据的处理。
使用开源软件的好处在于其源代码的开放性,允许开发者查看、修改和分发软件。这为社区提供了改进和定制软件的机会,同时也使得软件更加透明,用户可以对软件的工作方式更加放心。对于ImgToString这样的工具而言,开放源代码意味着可以由社区进行扩展,比如增加对其他图像格式的支持、优化转换速度、提高编码效率或者增加用户界面等。
在使用ImgToString或类似的工具时,需要注意的一点是编码后的字符串可能会变得非常长,尤其是对于高分辨率的图像。这可能会导致在某些场合下使用不便,例如在社交媒体或者限制字符数的平台上分享。此外,由于字符串中的数据是图像的直接表示,它们可能会包含非打印字符或特定格式的字符串,这在某些情况下可能会导致兼容性问题。
对于开发者而言,ImgToString这类工具在自动化测试、数据备份、跨平台共享图像资源等多种场景中非常有用。在Web开发中,可以利用此类工具将图像数据嵌入到HTML或CSS文件中,或者通过RESTful API传输图像数据时使用字符串形式。在自动化测试中,可以将预期的图像输出以字符串形式保存在测试脚本中,用于比对生成的图像字符串,以此验证图像内容的正确性。
综上所述,ImgToString作为一款开源软件,提供了一种将图像文件转换为字符串的实用方法。这不仅为图像的传输和分享提供了便利,也为开发者提供了在不同应用场景中集成图像数据的新思路。同时,其开源的特性也为社区贡献和软件改进提供了可能,使得软件本身能够更加完善,满足更多的需求。
Qt框选功能安全性增强指南:防止恶意操作的有效策略
# 摘要
本文聚焦于Qt框架中框选功能的安全性问题。首先介绍了Qt框选功能的基础概念和安全性基础,包括Qt的安全架构、安全编码标准和安全设计原则。接着,分析了框选功能中权限管理的必要性和实现方法。随后,探讨了如何通过多种防御策略,如输入验证、事件监听和安全审计,来识别和防御恶意操作。文章进一步详述了进行安全测试与验证的重要性,以及如何模拟攻击以修复安全漏洞。最后,通过案例研究,本