function [x,esq,j] = kmeans(d,k,x0)的分析
时间: 2024-05-18 17:12:07 浏览: 14
该函数是一个实现了 K-Means 算法的 MATLAB 函数,用于将数据集分成 k 个簇,每个簇包含最接近其质心的数据点。K-Means 算法是一种简单而有效的聚类算法,被广泛应用于数据分析、机器学习等领域。
K-Means 算法的基本思路如下:
1. 随机选择 k 个数据点作为初始质心。
2. 将每个数据点分配到距其最近的质心所在的簇中。
3. 计算每个簇的质心。
4. 重复执行步骤 2 和步骤 3,直到质心不再发生变化或达到最大迭代次数。
在该函数中,输入参数包括数据集 d、需要分成的簇的数量 k,以及每个簇的初始质心 x0。该函数的输出包括每个簇的最终质心、每个数据点到其所属簇的质心的平方距离的总和,以及每次迭代后得到的目标函数值(即 SSE)的变化量。
该函数的优点是实现简单,易于理解和使用。缺点是对于大规模数据集,K-Means 算法的时间复杂度较高,收敛速度慢且易陷入局部最优解。因此,在处理大规模数据集时,需要采用一些改进的算法或者数据降维等技术来提高聚类效率和准确性。
相关问题
给下列代码注释:1. function [x,esq,j] = kmeanlbg(d,k) nc=size(d,2); [x,esq,j]=kmeans(d,1); m=1; while m<k n=min(m,k-m); m=m+n; e=1e-4*sqrt(esq)*rand(1,nc); [x,esq,j]=kmeans(d,m,[x(1:n,:)+e(ones(n,1),:); x(1:n,:)-e(ones(n,1),:); x(n+1:m-n,:)]); end 2. [n,p] = size(d); if nargin<3 x = d(ceil(rand(1,k)*n),:); else x=x0; end y = x+1; while any(x(:) ~= y(:)) z = disteusq(d,x,'x'); [m,j] = min(z,[],2); y = x; for i=1:k s = j==i; if any(s) x(i,:) = mean(d(s,:),1); else q=find(m~=0); if isempty(q) break; end r=q(ceil(rand*length(q))); x(i,:) = d(r,:); m(r)=0; y=x+1; end end end esq=mean(m,1);
以下是对下列代码的注释:
1.
```
function [x,esq,j] = kmeanlbg(d,k)
nc=size(d,2);
[x,esq,j]=kmeans(d,1);
m=1;
while m<k
n=min(m,k-m);
m=m+n;
e=1e-4*sqrt(esq)*rand(1,nc);
[x,esq,j]=kmeans(d,m,[x(1:n,:)+e(ones(n,1),:); x(1:n,:)-e(ones(n,1),:); x(n+1:m-n,:)]);
end
```
上述代码实现了一个K均值聚类算法,使用Linde-Buzo-Gray (LBG) 算法来初始化聚类中心,并不断迭代优化聚类结果,其具体注释如下所示:
- `function [x,esq,j] = kmeanlbg(d,k)`:定义一个名为"kmeanlbg"的函数,接受两个参数d和k,返回三个值x,esq和j。
- `nc=size(d,2);`:计算数据矩阵d的列数,即特征数量。
- `[x,esq,j]=kmeans(d,1);`:使用K均值算法初始化聚类中心,将结果存储在变量x,esq和j中。
- `m=1;`:初始化聚类中心数量为1。
- `while m<k`:循环直到聚类中心数量达到k。
- `n=min(m,k-m);`:计算要添加或删除的聚类中心数量。
- `m=m+n;`:更新聚类中心数量。
- `e=1e-4*sqrt(esq)*rand(1,nc);`:生成一个随机扰动,用于初始化新的聚类中心。
- `[x,esq,j]=kmeans(d,m,[x(1:n,:)+e(ones(n,1),:); x(1:n,:)-e(ones(n,1),:); x(n+1:m-n,:)]);`:使用K均值算法进行聚类,将结果存储在变量x,esq和j中。此处使用Linde-Buzo-Gray (LBG) 算法初始化聚类中心。
- `end`:循环结束。
- `esq=mean(m,1);`:计算平均误差,并将其存储在变量esq中。
2.
```
[n,p] = size(d);
if nargin<3
x = d(ceil(rand(1,k)*n),:);
else
x=x0;
end
y = x+1;
while any(x(:) ~= y(:))
z = disteusq(d,x,'x');
[m,j] = min(z,[],2);
y = x;
for i=1:k
s = j==i;
if any(s)
x(i,:) = mean(d(s,:),1);
else
q=find(m~=0);
if isempty(q) break; end
r=q(ceil(rand*length(q)));
x(i,:) = d(r,:);
m(r)=0;
y=x+1;
end
end
end
esq=mean(m,1);
```
上述代码实现了一个K均值聚类算法,使用随机初始化聚类中心,并不断迭代优化聚类结果,其具体注释如下所示:
- `[n,p] = size(d);`:计算数据矩阵d的行数n和列数p。
- `if nargin<3`:如果输入参数小于3。
- `x = d(ceil(rand(1,k)*n),:);`:随机选择k个样本作为聚类中心,并将其存储在变量x中。
- `else`:否则。
- `x=x0;`:将输入的聚类中心初始化为变量x。
- `y = x+1;`:将变量y初始化为x+1,用于迭代终止条件。
- `while any(x(:) ~= y(:))`:循环直到聚类中心不再改变。
- `z = disteusq(d,x,'x');`:计算数据矩阵d中每个样本到聚类中心的欧氏距离,并将其存储在变量z中。
- `[m,j] = min(z,[],2);`:计算每个样本到最近聚类中心的距离,并将其存储在变量m中,同时记录每个样本所属的聚类编号,将其存储在变量j中。
- `y = x;`:将变量x的值复制给变量y,用于迭代终止条件。
- `for i=1:k`:循环遍历每个聚类。
- `s = j==i;`:找到属于当前聚类的所有样本。
- `if any(s)`:如果当前聚类非空。
- `x(i,:) = mean(d(s,:),1);`:计算当前聚类的新中心,并更新变量x中的值。
- `else`:否则。
- `q=find(m~=0);`:找到所有不属于任何聚类的样本。
- `if isempty(q) break; end`:如果没有找到可用的样本,则跳出循环。
- `r=q(ceil(rand*length(q)));`:从可用的样本中随机选择一个作为当前聚类的新中心。
- `x(i,:) = d(r,:);`:更新变量x中的值。
- `m(r)=0;`:将该样本从可用样本中删除。
- `y=x+1;`:将变量y的值更新为x+1,用于迭代终止条件。
- `end`:循环结束。
- `esq=mean(m,1);`:计算平均误差,并将其存储在变量esq中。
nc=size(d,2); [x,esq,j]=kmeans(d,1); m=1; while m<k n=min(m,k-m); m=m+n; e=1e-4*sqrt(esq)*rand(1,nc); [x,esq,j]=kmeans(d,m,[x(1:n,:)+e(ones(n,1),:); x(1:n,:)-e(ones(n,1),:); x(n+1:m-n,:)]); end 这段代码解析
这段代码使用了k-means++算法生成初始聚类中心,并且实现了k-means算法的聚类过程,下面是对代码的解析:
```matlab
nc=size(d,2);
[x,esq,j]=kmeans(d,1);
```
获取数据矩阵d的特征数量,将数据矩阵d聚为一个簇,并将聚类中心赋值给变量x,计算聚类结果的误差平方和esq和迭代次数j。
```matlab
m=1;
while m<k
n=min(m,k-m);
m=m+n;
e=1e-4*sqrt(esq)*rand(1,nc);
[x,esq,j]=kmeans(d,m,[x(1:n,:)+e(ones(n,1),:); x(1:n,:)-e(ones(n,1),:); x(n+1:m-n,:)]);
end
```
进入k-means++算法的主循环,循环次数为所需的聚类数量k减去已经聚类的簇的数量m。
根据当前的聚类中心x,计算误差平方和的平方根的1e-4倍作为标准差,生成一个服从正态分布的随机向量e。
根据k-means++算法的初始聚类中心选择规则,将当前聚类中心向量x分为已经聚类的前n个簇和待聚类的后m-n个簇,对后m-n个簇进行初始化。
将当前聚类中心x中前n个簇的每个聚类中心分别加上e和减去e,得到2n个备选聚类中心。将这些备选聚类中心和后m-n个簇的聚类中心合并,作为新的聚类中心矩阵传入k-means算法进行聚类。
重复以上步骤,直到所有簇都已经聚类完成。
总之,这段代码实现了k-means++算法的主要计算过程,将数据矩阵划分到所需的k个簇中,并生成初始的聚类中心矩阵。
相关推荐
最新推荐
Oracel Proc开发
Oracle Proc 是一种嵌入式C语言的编程方式,它允许开发者在C程序中直接执行SQL语句,类似于Informix的ESQ/C。这种方式使得开发者能够利用C语言的强大功能结合Oracle数据库的操作,提高程序效率和灵活性。 1. **数组...
分布式电网动态电压恢复器模拟装置设计与实现.doc
本装置采用DC-AC及AC-DC-AC双重结构,前级采用功率因数校正(PFC)电路完成AC-DC变换,改善输入端电网电能质量。后级采用单相全桥逆变加变压器输出的拓扑结构,输出功率50W。整个系统以TI公司的浮点数字信号控制器TMS320F28335为控制电路核心,采用规则采样法和DSP片内ePWM模块功能实现SPWM波,采用DSP片内12位A/D对各模拟信号进行采集检测,简化了系统设计和成本。本装置具有良好的数字显示功能,采用CPLD自行设计驱动的4.3英寸彩色液晶TFT-LCD非常直观地完成了输出信号波形、频谱特性的在线实时显示,以及输入电压、电流、功率,输出电压、电流、功率,效率,频率,相位差,失真度参数的正确显示。本装置具有开机自检、输入电压欠压及输出过流保护,在过流、欠压故障排除后能自动恢复。
【无人机通信】基于matlab Stackelberg算法无人机边缘计算抗干扰信道分配【含Matlab源码 4957期】.mp4
Matlab研究室上传的视频均有对应的完整代码,皆可运行,亲测可用,适合小白;
1、代码压缩包内容
主函数:main.m;
调用函数:其他m文件;无需运行
运行结果效果图;
2、代码运行版本
Matlab 2019b;若运行有误,根据提示修改;若不会,私信博主;
3、运行操作步骤
步骤一:将所有文件放到Matlab的当前文件夹中;
步骤二:双击打开main.m文件;
步骤三:点击运行,等程序运行完得到结果;
4、仿真咨询
如需其他服务,可私信博主或扫描视频QQ名片;
4.1 博客或资源的完整代码提供
4.2 期刊或参考文献复现
4.3 Matlab程序定制
4.4 科研合作
电网公司数字化转型规划与实践两个文件.pptx
电网公司数字化转型规划与实践两个文件.pptx
React Native Ruby 前后端分离系统案例介绍文档
React Native Ruby 前后端分离系统案例介绍文档
图书馆管理系统数据库设计与功能详解
"图书馆管理系统数据库设计.pdf"
图书馆管理系统数据库设计是一项至关重要的任务,它涉及到图书信息、读者信息、图书流通等多个方面。在这个系统中,数据库的设计需要满足各种功能需求,以确保图书馆的日常运营顺畅。
首先,系统的核心是安全性管理。为了保护数据的安全,系统需要设立权限控制,允许管理员通过用户名和密码登录。管理员具有全面的操作权限,包括添加、删除、查询和修改图书信息、读者信息,处理图书的借出、归还、逾期还书和图书注销等事务。而普通读者则只能进行查询操作,查看个人信息和图书信息,但不能进行修改。
读者信息管理模块是另一个关键部分,它包括读者类型设定和读者档案管理。读者类型设定允许管理员定义不同类型的读者,比如学生、教师,设定他们可借阅的册数和续借次数。读者档案管理则存储读者的基本信息,如编号、姓名、性别、联系方式、注册日期、有效期限、违规次数和当前借阅图书的数量。此外,系统还包括了借书证的挂失与恢复功能,以防止丢失后图书的不当借用。
图书管理模块则涉及图书的整个生命周期,从基本信息设置、档案管理到征订、注销和盘点。图书基本信息设置包括了ISBN、书名、版次、类型、作者、出版社、价格、现存量和库存总量等详细信息。图书档案管理记录图书的入库时间,而图书征订用于订购新的图书,需要输入征订编号、ISBN、订购数量和日期。图书注销功能处理不再流通的图书,这些图书的信息会被更新,不再可供借阅。图书查看功能允许用户快速查找特定图书的状态,而图书盘点则是为了定期核对库存,确保数据准确。
图书流通管理模块是系统中最活跃的部分,它处理图书的借出和归还流程,包括借阅、续借、逾期处理等功能。这个模块确保了图书的流通有序,同时通过记录借阅历史,方便读者查询自己的借阅情况和超期还书警告。
图书馆管理系统数据库设计是一个综合性的项目,涵盖了用户认证、信息管理、图书操作和流通跟踪等多个层面,旨在提供高效、安全的图书服务。设计时需要考虑到系统的扩展性、数据的一致性和安全性,以满足不同图书馆的具体需求。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
表锁问题全解析:深度解读,轻松解决
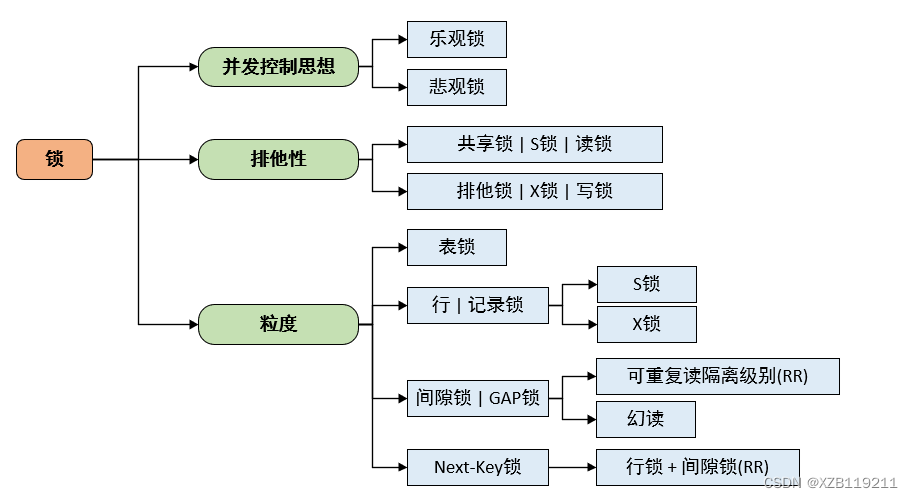
# 1. 表锁基础**
表锁是一种数据库并发控制机制,用于防止多个事务同时修改同一行或表,从而保证数据的一致性和完整性。表锁的工作原理是通过在表或行上设置锁,当一个事务需要访问被锁定的数据时,它必须等待锁被释放。
表锁分为两种类型:行锁和表锁。行锁只锁定被访问的行,而表锁锁定整个表。行锁的粒度更细,可以提高并发性,但开销也更大。表锁的粒度更粗,开销较小,但并发性较低。
表锁还分为共享锁和排他锁。共享锁允许多个事务同时
麻雀搜索算法SSA优化卷积神经网络CNN
麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种生物启发式的优化算法,它模拟了麻雀觅食的行为,用于解决复杂的优化问题,包括在深度学习中调整神经网络参数以提高性能。在卷积神经网络(Convolutional Neural Networks, CNN)中,SSA作为一种全局优化方法,可以应用于网络架构搜索、超参数调优等领域。
在CNN的优化中,SSA通常会:
1. **构建种群**:初始化一组随机的CNN结构或参数作为“麻雀”个体。
2. **评估适应度**:根据每个网络在特定数据集上的性能(如验证集上的精度或损失)来评估其适应度。
3. **觅食行为**:模仿
***物流有限公司仓储配送业务SOP详解
"该文档是***物流有限公司的仓储配送业务SOP管理程序,包含了工作职责、操作流程、各个流程的详细步骤,旨在规范公司的仓储配送管理工作,提高效率和准确性。"
在物流行业中,标准操作程序(SOP)是确保业务流程高效、一致和合规的关键。以下是对文件中涉及的主要知识点的详细解释:
1. **工作职责**:明确各岗位人员的工作职责和责任范围,是确保业务流程顺畅的基础。例如,配送中心主管负责日常业务管理、费用控制、流程监督和改进;发运管理员处理运输调配、计划制定、5S管理;仓管员负责货物的收发存管理、质量控制和5S执行;客户服务员则处理客户指令、运营单据和物流数据管理。
2. **操作流程**:文件详细列出了各项操作流程,包括**入库及出库配送流程**,强调了从接收到发货的完整过程,包括验收、登记、存储、拣选、包装、出库等环节,确保货物的安全和准确性。
3. **仓库装卸作业流程**:详细规定了货物装卸的操作步骤,包括使用设备、安全措施、作业标准,以防止货物损坏并提高作业效率。
4. **货物在途跟踪及异常情况处理流程**:描述了如何监控货物在运输途中的状态,以及遇到异常如延误、丢失或损坏时的应对措施,确保货物安全并及时处理问题。
5. **单据流转及保管流程**:规定了从订单创建到完成的单据处理流程,包括记录、审核、传递和存档,以保持信息的准确性和可追溯性。
6. **存货管理**:涵盖了库存控制策略,如先进先出(FIFO)、定期盘点、库存水平的优化,以避免过度库存或缺货。
7. **仓库标志流程**:明确了仓库内的标识系统,帮助员工快速定位货物,提高作业效率。
8. **仓库5S管理及巡检流程**:5S(整理、整顿、清扫、清洁、素养)是提高仓库环境和工作效率的重要工具,巡检流程则确保了5S的持续实施。
9. **仓库建筑设备设施的维护流程**:强调了设备设施的定期检查、保养和维修,以保证其正常运行,避免因设备故障导致的运营中断。
10. **附件清单**:列出所有相关的附件和表格,便于员工参考和执行。
通过这些详尽的SOP,***物流有限公司能够系统化地管理仓储配送业务,确保服务质量,减少错误,提升客户满意度,并为公司的持续改进提供基础。