“Receive physical documents from students, forward documents to committee, notify students service of outcomes of academic admissibility” are classified as ____________ step." (1分) Non-Value Adding (NVA) Data-driven decision making (DDDM) Value Adding (VA) Business Value Adding (BVA)
时间: 2024-04-05 21:30:01 浏览: 81
“Receive physical documents from students, forward documents to committee, notify students service of outcomes of academic admissibility”可以被归类为“非价值增加(Non-Value Adding, NVA)”步骤。这是因为这些步骤不会直接增加产品或服务的价值,而只是为了确保申请材料的完整性、准确性和合规性,并将这些材料传递给决策委员会进行评估。通知学生该决策的结果也是一个必要的步骤,但它并没有直接增加产品或服务的价值。
相关问题
用代码解决这个问题The program committee of the school programming contests, which are often held at the Ural State University, is a big, joyful, and united team. In fact, they are so united that the time spent together at the university is not enough for them, so they often visit each other at their homes. In addition, they are quite athletic and like walking. Once the guardian of the traditions of the sports programming at the Ural State University decided that the members of the program committee spent too much time walking from home to home. They could have spent that time inventing and preparing new problems instead. To prove that, he wanted to calculate the average distance that the members of the program committee walked when they visited each other. The guardian took a map of Yekaterinburg, marked the houses of all the members of the program committee there, and wrote down their coordinates. However, there were so many coordinates that he wasn't able to solve that problem and asked for your help. The city of Yekaterinburg is a rectangle with the sides parallel to the coordinate axes. All the streets stretch from east to west or from north to south through the whole city, from one end to the other. The house of each member of the program committee is located strictly at the intersection of two orthogonal streets. It is known that all the members of the program committee walk only along the streets, because it is more pleasant to walk on sidewalks than on small courtyard paths. Of course, when walking from one house to another, they always choose the shortest way. All the members of the program committee visit each other equally often. Input The first line contains the number n of members of the program committee (2 ≤ n ≤ 105). The i-th of the following n lines contains space-separated coordinates xi, yi of the house of the i-th member of the program committee (1 ≤ xi, yi ≤ 106). All coordinates are integers. Output Output the average distance, rounded down to an integer, that a member of the program committee walks from his house to the house of his colleague.
Sure, I can help you with that. Here's one possible solution in Python:
```python
import math
n = int(input())
x_coords = []
y_coords = []
for i in range(n):
x, y = map(int, input().split())
x_coords.append(x)
y_coords.append(y)
x_coords.sort()
y_coords.sort()
x_median = x_coords[n // 2]
y_median = y_coords[n // 2]
total_distance = 0
for i in range(n):
total_distance += abs(x_coords[i] - x_median) + abs(y_coords[i] - y_median)
average_distance = total_distance // n
print(average_distance)
```
The idea here is to find the median x-coordinate and the median y-coordinate of all the houses, since these will be the coordinates of the "center" of the city. Then, we calculate the total distance each member of the program committee will have to walk to get to their colleague's house, by adding up the Manhattan distances between their own coordinate and the median coordinates. Finally, we divide the total distance by the number of committee members to get the average distance, rounded down to an integer. Note that we don't actually need to calculate the square root of the distances, since we only care about the integer value.
I hope this helps! Let me know if you have any questions.
he file athlete_events.csv contains 271116 rows and 15 columns. This is a historical dataset on the modern Olympic Games, including all the Games from Athens 1896 to Rio 2016. Each row corresponds to an athlete competing in an Olympic event (athlete events). The columns are explained in the following table: ID: Unique number for each athlete Name: Athlete's name Sex: M or F Age: Integer Height: in centimeters Weight: In kilograms Team: Team name NOC: National Olympic Committee 3-letter code Games: Year and season Year: integer Season: Summer or Winter City: Host city Sport: Sport Event: detailed event Medal: Gold, Silver, Bronze, or NA Please pick any column(s) in the data set to draw a figure from which you can draw meaningful conclusions. Download the athlete_events.csv file
I suggest we draw a histogram to analyze the distribution of age among athletes in the dataset.
To do so, we can use the `matplotlib` library in Python. Here's the code to read the data from the CSV file and plot the histogram:
```python
import pandas as pd
import matplotlib.pyplot as plt
# Read the data from the CSV file
data = pd.read_csv("athlete_events.csv")
# Filter out rows with missing age values
data = data[data['Age'].notna()]
# Plot the histogram
plt.hist(data['Age'], bins=20, edgecolor='black')
# Add labels and title
plt.xlabel('Age')
plt.ylabel('Number of Athletes')
plt.title('Distribution of Age Among Olympic Athletes')
# Show the plot
plt.show()
```
This code reads the data from the CSV file and filters out rows where the age value is missing. It then plots a histogram of the age values using 20 bins and adds labels and a title. Finally, it shows the plot.
The resulting histogram will show us the distribution of age among athletes in the dataset, which can help us draw meaningful conclusions about the demographics of Olympic athletes over time.
阅读全文
相关推荐
大家在看
一种基于SLA的业务管理模型
一种基于SLA的业务管理模型,夏虹,李增智,提出了一种业务级协议(Service Level Agreement,SLA)驱动的业务管理模型,用于将业务使用者和提供者达成的SLA参数转化成设备属性参数。�
Windows_server_2008_R2安装金蝶K3WISE中间层安装与配置。
Windows_server_2008R2安装金蝶K3 WISE中间层安装配置的详细教程讲解。
轻量级xml 解析工具 xml-paras-foxe-CHS.exe
xml_paras_foxe_CHS.exe 轻量级xml 解析工具
信息化综合运维体系.doc
信息化综合运维体系.doc
IMX214_RegisterMap_2.0.0
IMX214_RegisterMap_2.0.0
最新推荐
SystemVerilog IEEE_Std1800-2017
SystemVerilog IEEE Std 1800-2017是设计自动化标准委员会(Design Automation Standards Committee)由IEEE计算机学会和IEEE标准协会企业咨询小组共同赞助制定的一项标准。这个标准在2017年进行了修订,对之前的...
Wi-Fi P2P Technical Specification v1.7翻译(中文版)_2019.docx
Wi-Fi P2P(Peer-to-Peer)技术规范是 Wi-Fi 设备之间的连接解决方案,旨在提供一个体系结构和一组协议,以促进 Wi-Fi P2P 操作。这份技术规范定义了 Wi-Fi P2P 的技术需求和实现方法,涵盖了设备发现、配对、连接、...
Posix标准接口文档(英文版).pdf
这个标准由IEEE(电气和电子工程师协会)和The Open Group共同制定,并由Portable Applications Standards Committee(IEEE计算机学会的便携式应用程序标准委员会)赞助。 "Posix标准接口文档(英文版).pdf" 是一份...
IEEE verilog 1364-2005.pdf
这个标准由IEEE Computer Society的Design Automation Standards Committee赞助发布,适用于从概念到实现的电子系统开发全过程。 Verilog HDL的核心功能包括: 1. **设计建模**:Verilog允许用户以模块化的方式...
ELF中文手册——ELF中文手册
TIS(Tool Interface Standard Committee)进一步推动了ELF的标准化,使其成为跨平台的目标文件格式。 **2. 目标文件** 目标文件是编译器和链接器工作的产物,包含了编译后的机器码和其他辅助信息。它们可以是未...
易语言例程:用易核心支持库打造功能丰富的IE浏览框
资源摘要信息:"易语言-易核心支持库实现功能完善的IE浏览框"
易语言是一种简单易学的编程语言,主要面向中文用户。它提供了大量的库和组件,使得开发者能够快速开发各种应用程序。在易语言中,通过调用易核心支持库,可以实现功能完善的IE浏览框。IE浏览框,顾名思义,就是能够在一个应用程序窗口内嵌入一个Internet Explorer浏览器控件,从而实现网页浏览的功能。
易核心支持库是易语言中的一个重要组件,它提供了对IE浏览器核心的调用接口,使得开发者能够在易语言环境下使用IE浏览器的功能。通过这种方式,开发者可以创建一个具有完整功能的IE浏览器实例,它不仅能够显示网页,还能够支持各种浏览器操作,如前进、后退、刷新、停止等,并且还能够响应各种事件,如页面加载完成、链接点击等。
在易语言中实现IE浏览框,通常需要以下几个步骤:
1. 引入易核心支持库:首先需要在易语言的开发环境中引入易核心支持库,这样才能在程序中使用库提供的功能。
2. 创建浏览器控件:使用易核心支持库提供的API,创建一个浏览器控件实例。在这个过程中,可以设置控件的初始大小、位置等属性。
3. 加载网页:将浏览器控件与一个网页地址关联起来,即可在控件中加载显示网页内容。
4. 控制浏览器行为:通过易核心支持库提供的接口,可以控制浏览器的行为,如前进、后退、刷新页面等。同时,也可以响应浏览器事件,实现自定义的交互逻辑。
5. 调试和优化:在开发完成后,需要对IE浏览框进行调试,确保其在不同的操作和网页内容下均能够正常工作。对于性能和兼容性的问题需要进行相应的优化处理。
易语言的易核心支持库使得在易语言环境下实现IE浏览框变得非常方便,它极大地降低了开发难度,并且提高了开发效率。由于易语言的易用性,即使是初学者也能够在短时间内学会如何创建和操作IE浏览框,实现网页浏览的功能。
需要注意的是,由于IE浏览器已经逐渐被微软边缘浏览器(Microsoft Edge)所替代,使用IE核心的技术未来可能面临兼容性和安全性的挑战。因此,在实际开发中,开发者应考虑到这一点,并根据需求选择合适的浏览器控件实现技术。
此外,易语言虽然简化了编程过程,但其在功能上可能不如主流的编程语言(如C++, Java等)强大,且社区和技术支持相比其他语言可能较为有限,这些都是在选择易语言作为开发工具时需要考虑的因素。
文件名列表中的“IE类”可能是指包含实现IE浏览框功能的类库或者示例代码。在易语言中,类库是一组封装好的代码模块,其中包含了各种功能的实现。通过在易语言项目中引用这些类库,开发者可以简化开发过程,快速实现特定功能。而示例代码则为开发者提供了具体的实现参考,帮助理解和学习如何使用易核心支持库来创建IE浏览框。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
STM32F407ZG引脚功能深度剖析:掌握引脚分布与配置的秘密(全面解读)
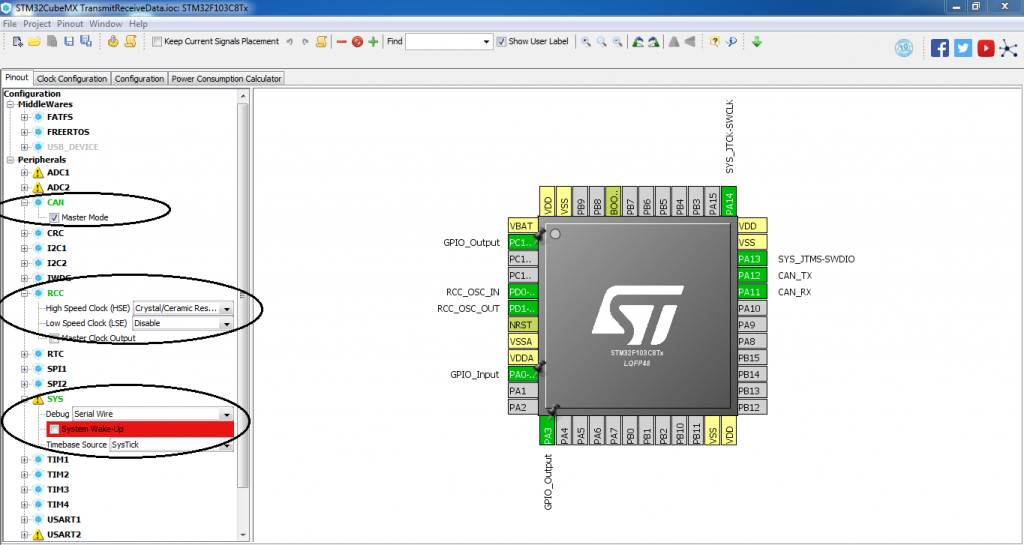
# 摘要
本文全面介绍了STM32F407ZG微控制器的引脚特性、功能、配置和应用。首先概述了该芯片的引脚布局,然后详细探讨了标准外设、高级控制以及特殊功能引脚的不同配置和使用方法。在此基础上,文章深入分析了引脚模式配置、高级配置技巧,并提供了实际应用案例,如LED控制和串口通信。在设计方面,阐述了引脚布局策略、多层板设计及高密度引脚应用的解决方案。最后,介绍
给出文档中问题的答案代码
您提到的是需要编写MATLAB代码来实现文档中的实验任务。以下是根据文档内容编写的MATLAB代码示例:
```matlab
% 上机2 实验代码
% 读取输入图像
inputImage = imread('your_face_image.jpg'); % 替换为您的图像文件路径
if size(inputImage, 1) < 1024 || size(inputImage, 2) < 1024
error('图像尺寸必须大于1024x1024');
end
% 将彩色图像转换为灰度图像
grayImage = rgb2gray(inputImage);
% 调整图像大小为5
Docker构建与运行Next.js应用的指南
资源摘要信息:"rivoltafilippo-next-main"
在探讨“rivoltafilippo-next-main”这一资源时,首先要从标题“rivoltafilippo-next”入手。这个标题可能是某一项目、代码库或应用的命名,结合描述中提到的Docker构建和运行命令,我们可以推断这是一个基于Docker的Node.js应用,特别是使用了Next.js框架的项目。Next.js是一个流行的React框架,用于服务器端渲染和静态网站生成。
描述部分提供了构建和运行基于Docker的Next.js应用的具体命令:
1. `docker build`命令用于创建一个新的Docker镜像。在构建镜像的过程中,开发者可以定义Dockerfile文件,该文件是一个文本文件,包含了创建Docker镜像所需的指令集。通过使用`-t`参数,用户可以为生成的镜像指定一个标签,这里的标签是`my-next-js-app`,意味着构建的镜像将被标记为`my-next-js-app`,方便后续的识别和引用。
2. `docker run`命令则用于运行一个Docker容器,即基于镜像启动一个实例。在这个命令中,`-p 3000:3000`参数指示Docker将容器内的3000端口映射到宿主机的3000端口,这样做通常是为了让宿主机能够访问容器内运行的应用。`my-next-js-app`是容器运行时使用的镜像名称,这个名称应该与构建时指定的标签一致。
最后,我们注意到资源包含了“TypeScript”这一标签,这表明项目可能使用了TypeScript语言。TypeScript是JavaScript的一个超集,它添加了静态类型定义的特性,能够帮助开发者更容易地维护和扩展代码,尤其是在大型项目中。
结合资源名称“rivoltafilippo-next-main”,我们可以推测这是项目的主目录或主仓库。通常情况下,开发者会将项目的源代码、配置文件、构建脚本等放在一个主要的目录中,这个目录通常命名为“main”或“src”等,以便于管理和维护。
综上所述,我们可以总结出以下几个重要的知识点:
- Docker容器和镜像的概念以及它们之间的关系:Docker镜像是静态的只读模板,而Docker容器是从镜像实例化的动态运行环境。
- `docker build`命令的使用方法和作用:这个命令用于创建新的Docker镜像,通常需要一个Dockerfile来指定构建的指令和环境。
- `docker run`命令的使用方法和作用:该命令用于根据镜像启动一个或多个容器实例,并可指定端口映射等运行参数。
- Next.js框架的特点:Next.js是一个支持服务器端渲染和静态网站生成的React框架,适合构建现代的Web应用。
- TypeScript的作用和优势:TypeScript是JavaScript的一个超集,它提供了静态类型检查等特性,有助于提高代码质量和可维护性。
- 项目资源命名习惯:通常项目会有一个主目录,用来存放项目的源代码和核心配置文件,以便于项目的版本控制和团队协作。
以上内容基于给定的信息进行了深入的分析,为理解该项目的构建、运行方式以及技术栈提供了基础。在实际开发中,开发者应当参考更详细的文档和指南,以更高效地管理和部署基于Docker和TypeScript的Next.js项目。