speller-bert
时间: 2024-07-22 18:01:07 浏览: 62
Speller-BERT是一种基于Transformer架构的语言模型,它结合了BERT(Bidirectional Encoder Representations from Transformers)和拼写检查功能。BERT最初是为了自然语言理解任务设计的,它通过预训练学习到了丰富的文本上下文信息。Speller-BERT则是在此基础上添加了对单词错误检测和纠正的能力。
这种模型通常会接受一段输入文本,然后判断其中可能存在拼写错误的部分,并尝试生成正确的单词建议。通过将拼写检查与深度学习模型相结合,它可以更准确地识别常见的拼写错误并提供相应的修正,常用于自动纠错、教育工具以及搜索引擎优化等领域。
相关问题
巴特沃斯带通滤波matlab
巴特沃斯带通滤波器是一种常用的滤波器,用于通过特定频率范围内的信号,并抑制其他频率范围的信号。它在MATLAB中的实现可以使用以下代码片段进行:
```matlab
OmegaP=12*pi*10^3; % 通带截止频率
OmegaS=24*pi*10^3; % 阻带截止频率
Rp=1; % 通带最大衰减
As=30; % 阻带最小衰减
% 计算巴特沃斯滤波器的阶数N和3dB截止频率OmegaC
[N,OmegaC = buttord(OmegaP, OmegaS, Rp, As, 's');
% 根据计算得到的阶数和截止频率,生成巴特沃斯滤波器的系数
[b,a = butter(N, OmegaC, 's');
% 绘制滤波器的频率响应曲线
[H,w = freqs(b, a); % 计算巴特沃斯滤波器的频率响应
Hx = freqs(b, a, [OmegaC, OmegaS]); % 检验截止频率对应的衰减指标
dbHx = -20*log10(abs(Hx)/max(abs(H))); % 将衰减指标转换为分贝单位
plot(w, 20*log10(abs(H))); % 绘制频率响应曲线
xlabel('w');
ylabel('分贝');
set(gca,'xtickmode','manual','xtick',[0,5*10^5,10*10^5,15*10^5,20*10^5,]);
set(gca,'ytickmode','manual','ytick',[-200,-150,-100,-50,-1,]);
```
以上代码中,使用`buttord`函数计算了滤波器的阶数和3dB截止频率,然后使用`butter`函数生成滤波器的系数。最后,使用`freqs`函数计算了滤波器的频率响应,并使用`plot`函数绘制出了滤波器的频率响应曲线。通过调整截止频率和阶数,可以实现不同的滤波效果。<span class="em">1</span><span class="em">2</span><span class="em">3</span>
#### 引用[.reference_title]
- *1* [巴特沃斯带通滤波器matlab代码-EEG-P300Speller-Toolkit:实施了脑电图处理工具包;集成SVM;堆叠的RNN和CNN](https://download.csdn.net/download/weixin_38736018/18922964)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v93^chatsearchT3_2"}}] [.reference_item style="max-width: 50%"]
- *2* *3* [基于matlab的巴特沃斯滤波器设计](https://blog.csdn.net/matlablx/article/details/121588058)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v93^chatsearchT3_2"}}] [.reference_item style="max-width: 50%"]
[ .reference_list ]
两篇英文文献关于语音识别
1. "Deep Speech 2: End-to-End Speech Recognition in English and Mandarin" by Dario Amodei, et al. (2016)
This paper presents Deep Speech 2, a deep learning-based approach for end-to-end speech recognition in both English and Mandarin. The authors use a recurrent neural network with bidirectional long short-term memory units for acoustic modeling, and a connectionist temporal classification layer for transcription. The model is trained on a large dataset of speech recordings and achieves state-of-the-art results on several benchmark datasets.
2. "Listen, Attend and Spell" by William Chan, et al. (2016)
This paper proposes the Listen, Attend and Spell (LAS) model for speech recognition, which combines a sequence-to-sequence model with an attention mechanism. The model includes a listener component that encodes the input speech signal, an attention mechanism that focuses on relevant parts of the signal during decoding, and a speller component that generates the transcription. The authors evaluate the model on several datasets and show that it outperforms existing approaches.
相关推荐
最新推荐
武汉学院在广东2021-2024各专业最低录取分数及位次表.pdf
全国各大学在广东2021-2024各专业最低录取分数及位次表
山西农业大学在广东2021-2024各专业最低录取分数及位次表.pdf
全国各大学在广东2021-2024各专业最低录取分数及位次表
tirtos-cc13xx-cc26xx-setupwin32-2-21-01-08
cc13xx和cc26xx的SDK
83rthbp8ys-2.zip
83rthbp8ys-2.zip
TB500板链提升机_机械3D图Solidworks设计图.zip
TB500板链提升机_机械3D图Solidworks设计图.zip
AirKiss技术详解:无线传递信息与智能家居连接
AirKiss原理是一种创新的信息传输技术,主要用于解决智能设备与外界无物理连接时的网络配置问题。传统的设备配置通常涉及有线或无线连接,如通过路由器的Web界面输入WiFi密码。然而,AirKiss技术简化了这一过程,允许用户通过智能手机或其他移动设备,无需任何实际连接,就能将网络信息(如WiFi SSID和密码)“隔空”传递给目标设备。
具体实现步骤如下:
1. **AirKiss工作原理示例**:智能插座作为一个信息孤岛,没有物理连接,通过AirKiss技术,用户的微信客户端可以直接传输SSID和密码给插座,插座收到这些信息后,可以自动接入预先设置好的WiFi网络。
2. **传统配置对比**:以路由器和无线摄像头为例,常规配置需要用户手动设置:首先,通过有线连接电脑到路由器,访问设置界面输入运营商账号和密码;其次,手机扫描并连接到路由器,进行子网配置;最后,摄像头连接家庭路由器后,会自动寻找厂商服务器进行心跳包发送以保持连接。
3. **AirKiss的优势**:AirKiss技术简化了配置流程,减少了硬件交互,特别是对于那些没有显示屏、按键或网络连接功能的设备(如无线摄像头),用户不再需要手动输入复杂的网络设置,只需通过手机轻轻一碰或发送一条消息即可完成设备的联网。这提高了用户体验,降低了操作复杂度,并节省了时间。
4. **应用场景扩展**:AirKiss技术不仅适用于智能家居设备,也适用于物联网(IoT)场景中的各种设备,如智能门锁、智能灯泡等,只要有接收AirKiss信息的能力,它们就能快速接入网络,实现远程控制和数据交互。
AirKiss原理是利用先进的无线通讯技术,结合移动设备的便利性,构建了一种无需物理连接的设备网络配置方式,极大地提升了物联网设备的易用性和智能化水平。这种技术在未来智能家居和物联网设备的普及中,有望发挥重要作用。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
交叉验证全解析:数据挖掘中的黄金标准与优化策略
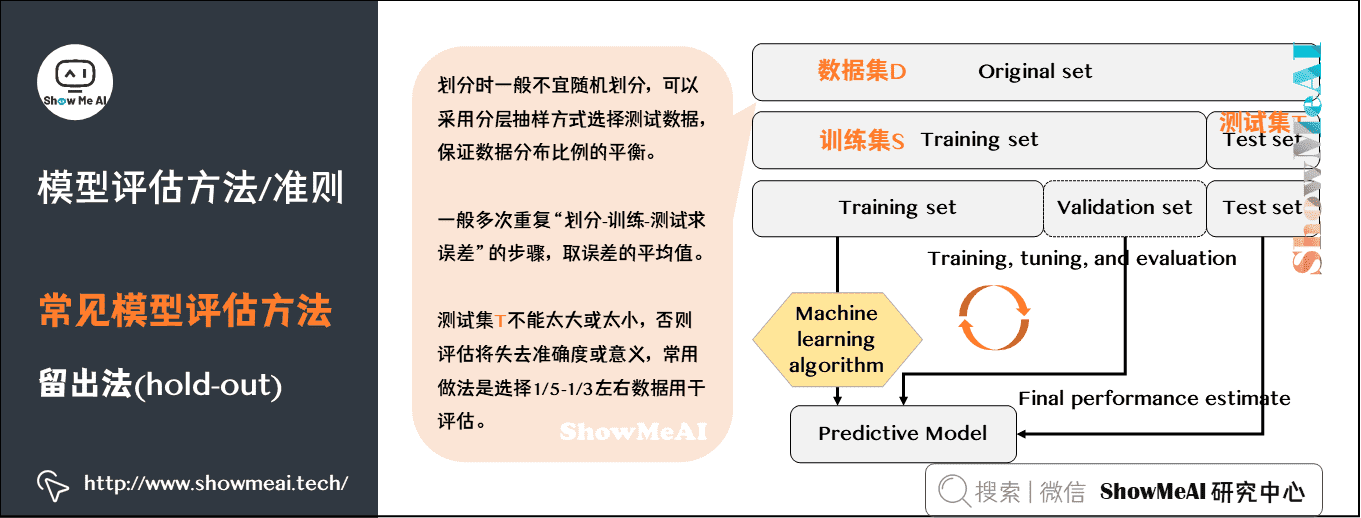
# 1. 交叉验证的基本概念和重要性
## 1.1 交叉验证的定义
交叉验证是一种统计方法,用于评估并改进机器学习模型的泛化能力。它通过将数据集分为几个小的“折”(或称为“子集”),然后迭代使用这些数据子集来训练和测试模型,从而得到模型性能的更准确估计。
## 1.2 交叉验证的重要性
在机器学习过程中,我们通常面临一个重要的问题:模型可能对训练数据过度拟合,而不能很好地推广到新数据
在交换机上创建 VLAN10、VLAN20和VLAN30,将交换机 B 的 2-5 接口加入到 VLAN 10 中 用ensp写出配置命令
在交换机上配置VLAN并分配接口到特定的VLAN中,通常需要登录到交换机的命令行界面。以下是在华为交换机上使用eNSP(Enterprise Network Simulation Platform,企业网络模拟平台)模拟器进行VLAN配置的基本步骤和命令:
首先,进入系统视图:
```
system-view
```
然后创建VLAN10、VLAN20和VLAN30:
```
vlan 10
vlan 20
vlan 30
```
接下来,将交换机B的2到5端口加入到VLAN10中,假设交换机B的接口编号为GigabitEthernet0/0/2至GigabitEthernet0/0/5
Hibernate主键生成策略详解
"Hibernate各种主键生成策略与配置详解"
在关系型数据库中,主键是表中的一个或一组字段,用于唯一标识一条记录。在使用Hibernate进行持久化操作时,主键的生成策略是一个关键的配置,因为它直接影响到数据的插入和管理。以下是Hibernate支持的各种主键生成策略的详细解释:
1. assigned: 这种策略要求开发者在保存对象之前手动设置主键值。Hibernate不参与主键的生成,因此这种方式可以跨数据库,但并不推荐,因为可能导致数据一致性问题。
2. increment: Hibernate会从数据库中获取当前主键的最大值,并在内存中递增生成新的主键。由于这个过程不依赖于数据库的序列或自增特性,它可以跨数据库使用。然而,当多进程并发访问时,可能会出现主键冲突,导致Duplicate entry错误。
3. hilo: Hi-Lo算法是一种优化的增量策略,它在一个较大的范围内生成主键,减少数据库交互。在每个session中,它会从数据库获取一个较大的范围,然后在内存中分配,降低主键碰撞的风险。
4. seqhilo: 类似于hilo,但它使用数据库的序列来获取范围,适合Oracle等支持序列的数据库。
5. sequence: 这个策略依赖于数据库提供的序列,如Oracle、PostgreSQL等,直接使用数据库序列生成主键,保证全局唯一性。
6. identity: 适用于像MySQL这样的数据库,它们支持自动增长的主键。Hibernate在插入记录时让数据库自动为新行生成主键。
7. native: 根据所连接的数据库类型,自动选择最合适的主键生成策略,如identity、sequence或hilo。
8. uuid: 使用UUID算法生成128位的唯一标识符,适用于分布式环境,无需数据库支持。
9. guid: 类似于uuid,但根据不同的实现可能会有所不同,通常在Windows环境下生成的是GUID字符串。
10. foreign: 通过引用另一个表的主键来生成当前表的主键,适用于关联实体的情况。
11. select: 在插入之前,通过执行SQL查询来获取主键值,这种方式需要开发者提供定制的SQL语句。
12. 注释方式配置: 可以通过在Java实体类的@Id和@GeneratedValue注解中指定generator属性来配置自定义的主键生成策略。
13. 小结: Hibernate的主键生成策略选择应基于数据库特性、性能需求以及是否需要跨数据库兼容等因素。在实际应用中,需要根据项目具体需求选择最适合的策略。
注意,合理选择主键生成策略对于数据库性能和数据一致性至关重要。例如,increment策略在多进程环境下可能会出现问题,而sequence和identity策略则更安全,但可能不适合所有数据库系统。因此,开发者应充分理解每种策略的优缺点,并结合实际情况作出决策。