广告联盟系统v7.09
时间: 2024-01-01 18:02:21 浏览: 110
广告联盟系统v7.09是一款全新的广告合作平台,它能够帮助广告主和网站主实现更有效的合作。该系统拥有更智能的广告投放功能,可以根据用户的兴趣和行为进行定向投放,提高广告的触达和转化率。同时,系统还提供了更多的数据分析和报告功能,帮助用户更好地了解广告效果和用户行为,从而优化广告投放策略。
除此之外,广告联盟系统v7.09还拥有更丰富的广告资源和更灵活的合作模式。广告主可以根据自己的需求选择不同类型的广告资源,包括图片广告、视频广告、原生广告等,满足不同的推广需求。而对于网站主来说,可以通过更灵活的结算方式和更多样化的广告展示方式,实现更稳定和可持续的收益增长。
该系统还支持更全面的用户管理功能,包括用户注册、登录、权限管理等,为用户提供更便捷的操作体验。而且,广告联盟系统v7.09还拥有更安全的数据保护和隐私保护机制,保障用户数据的安全和隐私。
总的来说,广告联盟系统v7.09是一款功能更强大,操作更便捷,资源更丰富,安全性更高的广告合作平台,将为广告主和网站主带来更多的商业机会和收益增长。
相关问题
petalinux 系统测试方法
Petalinux是基于Yocto Project构建的嵌入式Linux开发平台,提供了一套完整的工具链和开发环境,支持快速构建嵌入式Linux系统。下面是Petalinux系统的测试方法:
1.启动系统
使用Petalinux生成的BOOT.bin和image.ub镜像文件烧录到目标板后,通过串口或者网口连接到目标板,启动系统。
2.验证系统启动
在目标板启动后,可以通过串口或者网口连接到系统,检查系统启动状态。可以使用以下命令检查系统启动信息:
```
dmesg | grep "Boot"
```
如果系统启动成功,应该能够看到类似以下信息:
```
[ 0.000000] Booting Linux on physical CPU 0x0
[ 0.000000] Linux version 4.14.0-xilinx-v2018.3 (oe-user@oe-host) (gcc version 7.3.0 (GCC)) #1 SMP PREEMPT Wed Dec 12 14:56:37 PST 2018
[ 0.000000] Boot CPU: AArch64 Processor [410fd034]
[ 0.000000] Machine model: xlnx,zynqmp
[ 0.000000] earlycon: cdns0 at MMIO 0x00000000ff000000 (options '')
[ 0.000000] bootconsole [cdns0] enabled
```
3.验证系统网络
Petalinux系统默认启用了网络支持,可以通过网口连接到系统并测试网络连接。可以使用以下命令检查网络配置信息:
```
ifconfig
```
如果网络配置正确,应该能够看到类似以下信息:
```
eth0 Link encap:Ethernet HWaddr 00:0a:35:00:01:22
inet addr:192.168.1.10 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::20a:35ff:fe00:122/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Interrupt:40 Base address:0x8000
```
可以使用以下命令测试网络连接:
```
ping www.baidu.com
```
如果网络配置正确,应该能够看到类似以下信息:
```
PING www.a.shifen.com (220.181.38.148) 56(84) bytes of data.
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=1 ttl=54 time=7.16 ms
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=2 ttl=54 time=7.35 ms
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=3 ttl=54 time=7.36 ms
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=4 ttl=54 time=7.09 ms
^C
--- www.a.shifen.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3005ms
rtt min/avg/max/mdev = 7.093/7.241/7.360/0.116 ms
```
4.验证系统存储
Petalinux系统默认支持SD卡和NAND Flash存储,可以使用以下命令检查存储设备状态:
```
df -h
```
如果存储设备挂载成功,应该能够看到类似以下信息:
```
Filesystem Size Used Available Use% Mounted on
/dev/mmcblk0p1 7.3G 828.4M 6.6G 11% /
devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 1.9G 47.7M 1.9G 2% /run
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
tmpfs 1.9G 0 1.9G 0% /tmp
tmpfs 380M 0 380M 0% /run/user/0
```
5.验证系统功能
Petalinux系统默认安装了一些常用的工具和应用程序,可以使用以下命令测试系统功能:
```
ls /usr/bin
```
如果系统功能正常,应该能够看到类似以下信息:
```
[...]
xz
xzcat
xzcmp
xzdec
[...]
```
除此之外,还可以通过其他常用的命令和应用程序测试系统功能,比如ls、cat、echo、vi等命令,或者使用ping等网络工具测试网络功能。
CUDA out of memory. Tried to allocate 6.29 GiB (GPU 0; 8.00 GiB total capacity; 7.09 GiB already allocated; 0 bytes free; 7.09 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
这个错误提示表明在使用CUDA进行计算时,显存不足以分配所需的内存。可能的原因是模型或数据集过大,导致无法完全放入显存中。
以下是一些解决这个问题的方法:
1. 减少批次大小(batch size):尝试减少每个批次中样本的数量。较小的批次大小会减少每个批次所需的内存量,但也可能影响训练效果。
2. 减少模型参数数量:考虑减少模型的大小,例如减少网络层数、减少每层的节点数或使用更小的模型。这样可以减少模型所需的内存量。
3. 使用更小的图像尺寸:如果你正在处理图像数据,可以尝试将图像尺寸缩小,以减少每个样本所需的内存量。
4. 释放不必要的变量:在每个训练迭代之后,手动释放不再需要的变量,以释放显存空间。可以使用`del`语句来删除不再需要的变量。
5. 使用更高显存的GPU:如果你有多个GPU可用,尝试切换到一个具有更高显存容量的GPU。
6. 使用分布式训练:如果你有多台机器可用,可以尝试使用分布式训练来分散计算和内存负载。
7. 设置`max_split_size_mb`参数:根据错误提示中的建议,你可以尝试通过设置`max_split_size_mb`参数来避免内存碎片问题。具体设置方法可以参考PyTorch的内存管理文档以及PYTORCH_CUDA_ALLOC_CONF文档。
请注意,以上方法仅为一些建议,具体解决方案可能因实际情况而异。如果问题仍然存在,你可能需要进一步调整你的模型、数据集或计算资源配置。
相关推荐
最新推荐
数据结构实验报告(集合)
此代码实现了一个集合的抽象数据类型 ASet,用于管理整数集合,确保集合内所有元素唯一且无重复。提供了多种基本操作,包括集合的创建、输出、元素查找及集合间的基本运算(并集、交集、差集)。
主要功能
创建集合:
从整数数组创建集合,并设定集合大小。
输出集合:
打印集合内所有元素,格式为以空格分隔的整数列表。
元素查找:
判断指定元素是否存在于集合中,返回布尔值。
集合运算:
并集:合并两个集合的所有元素,并去重。
交集:找出两个集合的共同元素。
差集:找出存在于第一个集合但不在第二个集合中的元素。
核心算法
快速排序:对集合元素进行排序,采用递归方式实现,确保集合有序。
去重:对已排序的集合进行去重,确保集合内元素唯一。
集合运算:使用双指针法高效计算并集、交集和差集。
MythwareStudentHacker-main.zip
MythwareStudentHacker-main
《金智慧RFID高校固定资产管理平台解决方案》.doc
《金智慧RFID高校固定资产管理平台解决方案》.doc
大连东软信息学院在广东2021-2024各专业最低录取分数及位次表.pdf
全国各大学在广东2021-2024各专业最低录取分数及位次表
湖南财政经济学院在广东2021-2024各专业最低录取分数及位次表.pdf
全国各大学在广东2021-2024各专业最低录取分数及位次表
AirKiss技术详解:无线传递信息与智能家居连接
AirKiss原理是一种创新的信息传输技术,主要用于解决智能设备与外界无物理连接时的网络配置问题。传统的设备配置通常涉及有线或无线连接,如通过路由器的Web界面输入WiFi密码。然而,AirKiss技术简化了这一过程,允许用户通过智能手机或其他移动设备,无需任何实际连接,就能将网络信息(如WiFi SSID和密码)“隔空”传递给目标设备。
具体实现步骤如下:
1. **AirKiss工作原理示例**:智能插座作为一个信息孤岛,没有物理连接,通过AirKiss技术,用户的微信客户端可以直接传输SSID和密码给插座,插座收到这些信息后,可以自动接入预先设置好的WiFi网络。
2. **传统配置对比**:以路由器和无线摄像头为例,常规配置需要用户手动设置:首先,通过有线连接电脑到路由器,访问设置界面输入运营商账号和密码;其次,手机扫描并连接到路由器,进行子网配置;最后,摄像头连接家庭路由器后,会自动寻找厂商服务器进行心跳包发送以保持连接。
3. **AirKiss的优势**:AirKiss技术简化了配置流程,减少了硬件交互,特别是对于那些没有显示屏、按键或网络连接功能的设备(如无线摄像头),用户不再需要手动输入复杂的网络设置,只需通过手机轻轻一碰或发送一条消息即可完成设备的联网。这提高了用户体验,降低了操作复杂度,并节省了时间。
4. **应用场景扩展**:AirKiss技术不仅适用于智能家居设备,也适用于物联网(IoT)场景中的各种设备,如智能门锁、智能灯泡等,只要有接收AirKiss信息的能力,它们就能快速接入网络,实现远程控制和数据交互。
AirKiss原理是利用先进的无线通讯技术,结合移动设备的便利性,构建了一种无需物理连接的设备网络配置方式,极大地提升了物联网设备的易用性和智能化水平。这种技术在未来智能家居和物联网设备的普及中,有望发挥重要作用。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
交叉验证全解析:数据挖掘中的黄金标准与优化策略
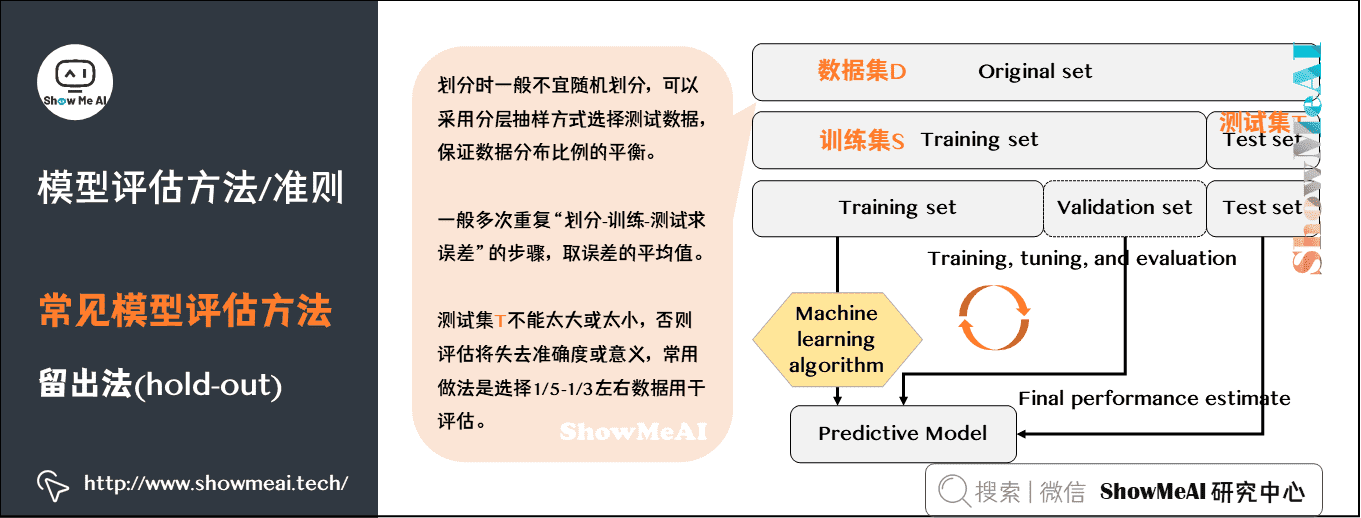
# 1. 交叉验证的基本概念和重要性
## 1.1 交叉验证的定义
交叉验证是一种统计方法,用于评估并改进机器学习模型的泛化能力。它通过将数据集分为几个小的“折”(或称为“子集”),然后迭代使用这些数据子集来训练和测试模型,从而得到模型性能的更准确估计。
## 1.2 交叉验证的重要性
在机器学习过程中,我们通常面临一个重要的问题:模型可能对训练数据过度拟合,而不能很好地推广到新数据
在交换机上创建 VLAN10、VLAN20和VLAN30,将交换机 B 的 2-5 接口加入到 VLAN 10 中 用ensp写出配置命令
在交换机上配置VLAN并分配接口到特定的VLAN中,通常需要登录到交换机的命令行界面。以下是在华为交换机上使用eNSP(Enterprise Network Simulation Platform,企业网络模拟平台)模拟器进行VLAN配置的基本步骤和命令:
首先,进入系统视图:
```
system-view
```
然后创建VLAN10、VLAN20和VLAN30:
```
vlan 10
vlan 20
vlan 30
```
接下来,将交换机B的2到5端口加入到VLAN10中,假设交换机B的接口编号为GigabitEthernet0/0/2至GigabitEthernet0/0/5
Hibernate主键生成策略详解
"Hibernate各种主键生成策略与配置详解"
在关系型数据库中,主键是表中的一个或一组字段,用于唯一标识一条记录。在使用Hibernate进行持久化操作时,主键的生成策略是一个关键的配置,因为它直接影响到数据的插入和管理。以下是Hibernate支持的各种主键生成策略的详细解释:
1. assigned: 这种策略要求开发者在保存对象之前手动设置主键值。Hibernate不参与主键的生成,因此这种方式可以跨数据库,但并不推荐,因为可能导致数据一致性问题。
2. increment: Hibernate会从数据库中获取当前主键的最大值,并在内存中递增生成新的主键。由于这个过程不依赖于数据库的序列或自增特性,它可以跨数据库使用。然而,当多进程并发访问时,可能会出现主键冲突,导致Duplicate entry错误。
3. hilo: Hi-Lo算法是一种优化的增量策略,它在一个较大的范围内生成主键,减少数据库交互。在每个session中,它会从数据库获取一个较大的范围,然后在内存中分配,降低主键碰撞的风险。
4. seqhilo: 类似于hilo,但它使用数据库的序列来获取范围,适合Oracle等支持序列的数据库。
5. sequence: 这个策略依赖于数据库提供的序列,如Oracle、PostgreSQL等,直接使用数据库序列生成主键,保证全局唯一性。
6. identity: 适用于像MySQL这样的数据库,它们支持自动增长的主键。Hibernate在插入记录时让数据库自动为新行生成主键。
7. native: 根据所连接的数据库类型,自动选择最合适的主键生成策略,如identity、sequence或hilo。
8. uuid: 使用UUID算法生成128位的唯一标识符,适用于分布式环境,无需数据库支持。
9. guid: 类似于uuid,但根据不同的实现可能会有所不同,通常在Windows环境下生成的是GUID字符串。
10. foreign: 通过引用另一个表的主键来生成当前表的主键,适用于关联实体的情况。
11. select: 在插入之前,通过执行SQL查询来获取主键值,这种方式需要开发者提供定制的SQL语句。
12. 注释方式配置: 可以通过在Java实体类的@Id和@GeneratedValue注解中指定generator属性来配置自定义的主键生成策略。
13. 小结: Hibernate的主键生成策略选择应基于数据库特性、性能需求以及是否需要跨数据库兼容等因素。在实际应用中,需要根据项目具体需求选择最适合的策略。
注意,合理选择主键生成策略对于数据库性能和数据一致性至关重要。例如,increment策略在多进程环境下可能会出现问题,而sequence和identity策略则更安全,但可能不适合所有数据库系统。因此,开发者应充分理解每种策略的优缺点,并结合实际情况作出决策。