Doc文本 embedding
时间: 2024-08-28 19:01:31 浏览: 53
文档文本嵌入(Doc2Vec)是一种自然语言处理技术,它将整个文档而不是单个单词映射到一个高维向量空间中。这种技术通常基于Word2Vec模型,如Continuous Bag of Words (CBOW) 或 Skip-Gram 模型,但它考虑了上下文的全局信息,因为它们不仅仅是孤立词的上下文窗口。
Doc2Vec通过训练捕捉到了词语在整个文档中的语义和结构模式。它可以生成每个文档的独特向量表示,使得相似的文档在向量空间中有相近的位置。这种方法常用于文档分类、检索、摘要生成等应用场景,因为它能够保留文档的主题和整体内容信息。
常见的Doc2Vec模型有GloVe for Docs和Paragraph Vector(PV-DM和PV-DBoW)。在实际应用中,可以使用预训练好的模型或自己训练模型来获得文档向量。
相关问题
doc2vec embedding
Doc2Vec是一种基于Word2Vec的扩展,用于将文档或句子表示为固定长度的向量。它是一种无监督的学习方法,可以将文本转换为连续的向量表示。
在Doc2Vec中,每个文档被表示为一个向量,这个向量可以捕捉到文档的语义含义。与Word2Vec类似,Doc2Vec也有两种模型:分布式内存模型(Distributed Memory Model of Paragraph Vectors,简称DM)和分布式袋模型(Distributed Bag of Words,简称DBOW)。
在DM模型中,每个文档都有一个唯一的标识符,同时也有一个特殊的"标签"。这个标签会作为一个额外的输入来预测文档中的词语。通过不断地调整模型参数,最终可以得到文档的向量表示。
在DBOW模型中,文档被看作是无序的词袋,模型只关注预测词出现的概率。通过训练一个神经网络来预测词语,可以得到文档的向量表示。
Doc2Vec可以应用于多个自然语言处理任务,如文本分类、文档相似度计算和信息检索等。它在许多实际应用中取得了良好的效果,并且可以处理大规模数据集。
Doc2Vec 生成embedding 模型
Doc2Vec(文档到向量)是一种自然语言处理技术,它扩展自 Word2Vec,旨在捕获句子级别的上下文信息,生成每个文档的固定长度向量表示,即文档嵌入(Document Embedding)。这种技术通常基于两种模型: Distributed Memory Model of Paragraph Vectors (PV-DM) 和 Continuous Bag-of-Words with Subword Information (CBOW-SW)。
**生成过程**:
1. **训练阶段**:
- 首先,将整个文档拆分成段落或单词序列(对于 PV-DM),并标记好它们的上下文。
- CBOW-SW 还利用子词信息来增强词汇表的覆盖范围。
- 训练过程中,模型会学习每个词以及其上下文词的关系,同时尝试从上下文中推断出未看到过的词。
2. **生成 embedding**:
- 给定一个新的文档,通过相似的训练过程,将整个文档作为一个整体输入到模型中,计算出这个文档的向量表示,这个向量能反映出文档的主题、结构和内容特点。
3. **应用**:
- 文档嵌入可以用于多种任务,如文档相似度计算、文档分类、聚类、检索等。
**实例**:
```R
library(doc2vec)
# 假设我们有一个名为"docs"的数据框,其中包含文章文本
model <- TextModel$new(docs$text_column, vector_size = 100) # 设置向量维度
model$train(window = 5, min_count = 1) # 训练参数
doc_vecs <- model$sentenceVector(docs$new_document) # 对新文档生成向量
```
阅读全文
相关推荐
大家在看
一种基于SLA的业务管理模型
一种基于SLA的业务管理模型,夏虹,李增智,提出了一种业务级协议(Service Level Agreement,SLA)驱动的业务管理模型,用于将业务使用者和提供者达成的SLA参数转化成设备属性参数。�
蓝矩智慧校友管理系统
蓝矩智慧校友管理系统,已为全国近三十家高校开发了系统,包括上海交通大学、上海理工大学、厦门大学、南开大学、四川大学等知名院校。
ThinkPadT61升级BIOS2.29程序,升级后可支持8GB内存,SATAIII固态盘,支持T9300CPU
ThinkPadT61升级BIOS2.29程序,升级后可支持8GB内存,SATAIII固态盘,支持T9300CPU
saml-idp.zip
saml2.0 idp 应用suceess factors java spring boot
思科无线接入点无法连接到无线 LAN 控制器
思科无线接入点无法连接到无线 LAN 控制器
最新推荐
utlog.sqlite
utlog.sqlite
易语言例程:用易核心支持库打造功能丰富的IE浏览框
资源摘要信息:"易语言-易核心支持库实现功能完善的IE浏览框"
易语言是一种简单易学的编程语言,主要面向中文用户。它提供了大量的库和组件,使得开发者能够快速开发各种应用程序。在易语言中,通过调用易核心支持库,可以实现功能完善的IE浏览框。IE浏览框,顾名思义,就是能够在一个应用程序窗口内嵌入一个Internet Explorer浏览器控件,从而实现网页浏览的功能。
易核心支持库是易语言中的一个重要组件,它提供了对IE浏览器核心的调用接口,使得开发者能够在易语言环境下使用IE浏览器的功能。通过这种方式,开发者可以创建一个具有完整功能的IE浏览器实例,它不仅能够显示网页,还能够支持各种浏览器操作,如前进、后退、刷新、停止等,并且还能够响应各种事件,如页面加载完成、链接点击等。
在易语言中实现IE浏览框,通常需要以下几个步骤:
1. 引入易核心支持库:首先需要在易语言的开发环境中引入易核心支持库,这样才能在程序中使用库提供的功能。
2. 创建浏览器控件:使用易核心支持库提供的API,创建一个浏览器控件实例。在这个过程中,可以设置控件的初始大小、位置等属性。
3. 加载网页:将浏览器控件与一个网页地址关联起来,即可在控件中加载显示网页内容。
4. 控制浏览器行为:通过易核心支持库提供的接口,可以控制浏览器的行为,如前进、后退、刷新页面等。同时,也可以响应浏览器事件,实现自定义的交互逻辑。
5. 调试和优化:在开发完成后,需要对IE浏览框进行调试,确保其在不同的操作和网页内容下均能够正常工作。对于性能和兼容性的问题需要进行相应的优化处理。
易语言的易核心支持库使得在易语言环境下实现IE浏览框变得非常方便,它极大地降低了开发难度,并且提高了开发效率。由于易语言的易用性,即使是初学者也能够在短时间内学会如何创建和操作IE浏览框,实现网页浏览的功能。
需要注意的是,由于IE浏览器已经逐渐被微软边缘浏览器(Microsoft Edge)所替代,使用IE核心的技术未来可能面临兼容性和安全性的挑战。因此,在实际开发中,开发者应考虑到这一点,并根据需求选择合适的浏览器控件实现技术。
此外,易语言虽然简化了编程过程,但其在功能上可能不如主流的编程语言(如C++, Java等)强大,且社区和技术支持相比其他语言可能较为有限,这些都是在选择易语言作为开发工具时需要考虑的因素。
文件名列表中的“IE类”可能是指包含实现IE浏览框功能的类库或者示例代码。在易语言中,类库是一组封装好的代码模块,其中包含了各种功能的实现。通过在易语言项目中引用这些类库,开发者可以简化开发过程,快速实现特定功能。而示例代码则为开发者提供了具体的实现参考,帮助理解和学习如何使用易核心支持库来创建IE浏览框。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
STM32F407ZG引脚功能深度剖析:掌握引脚分布与配置的秘密(全面解读)
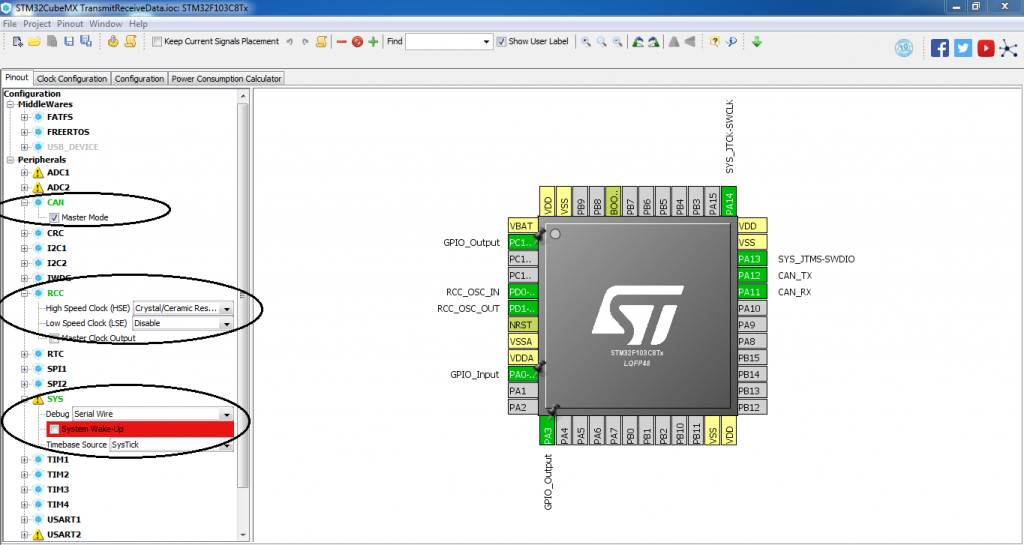
# 摘要
本文全面介绍了STM32F407ZG微控制器的引脚特性、功能、配置和应用。首先概述了该芯片的引脚布局,然后详细探讨了标准外设、高级控制以及特殊功能引脚的不同配置和使用方法。在此基础上,文章深入分析了引脚模式配置、高级配置技巧,并提供了实际应用案例,如LED控制和串口通信。在设计方面,阐述了引脚布局策略、多层板设计及高密度引脚应用的解决方案。最后,介绍
给出文档中问题的答案代码
您提到的是需要编写MATLAB代码来实现文档中的实验任务。以下是根据文档内容编写的MATLAB代码示例:
```matlab
% 上机2 实验代码
% 读取输入图像
inputImage = imread('your_face_image.jpg'); % 替换为您的图像文件路径
if size(inputImage, 1) < 1024 || size(inputImage, 2) < 1024
error('图像尺寸必须大于1024x1024');
end
% 将彩色图像转换为灰度图像
grayImage = rgb2gray(inputImage);
% 调整图像大小为5
Docker构建与运行Next.js应用的指南
资源摘要信息:"rivoltafilippo-next-main"
在探讨“rivoltafilippo-next-main”这一资源时,首先要从标题“rivoltafilippo-next”入手。这个标题可能是某一项目、代码库或应用的命名,结合描述中提到的Docker构建和运行命令,我们可以推断这是一个基于Docker的Node.js应用,特别是使用了Next.js框架的项目。Next.js是一个流行的React框架,用于服务器端渲染和静态网站生成。
描述部分提供了构建和运行基于Docker的Next.js应用的具体命令:
1. `docker build`命令用于创建一个新的Docker镜像。在构建镜像的过程中,开发者可以定义Dockerfile文件,该文件是一个文本文件,包含了创建Docker镜像所需的指令集。通过使用`-t`参数,用户可以为生成的镜像指定一个标签,这里的标签是`my-next-js-app`,意味着构建的镜像将被标记为`my-next-js-app`,方便后续的识别和引用。
2. `docker run`命令则用于运行一个Docker容器,即基于镜像启动一个实例。在这个命令中,`-p 3000:3000`参数指示Docker将容器内的3000端口映射到宿主机的3000端口,这样做通常是为了让宿主机能够访问容器内运行的应用。`my-next-js-app`是容器运行时使用的镜像名称,这个名称应该与构建时指定的标签一致。
最后,我们注意到资源包含了“TypeScript”这一标签,这表明项目可能使用了TypeScript语言。TypeScript是JavaScript的一个超集,它添加了静态类型定义的特性,能够帮助开发者更容易地维护和扩展代码,尤其是在大型项目中。
结合资源名称“rivoltafilippo-next-main”,我们可以推测这是项目的主目录或主仓库。通常情况下,开发者会将项目的源代码、配置文件、构建脚本等放在一个主要的目录中,这个目录通常命名为“main”或“src”等,以便于管理和维护。
综上所述,我们可以总结出以下几个重要的知识点:
- Docker容器和镜像的概念以及它们之间的关系:Docker镜像是静态的只读模板,而Docker容器是从镜像实例化的动态运行环境。
- `docker build`命令的使用方法和作用:这个命令用于创建新的Docker镜像,通常需要一个Dockerfile来指定构建的指令和环境。
- `docker run`命令的使用方法和作用:该命令用于根据镜像启动一个或多个容器实例,并可指定端口映射等运行参数。
- Next.js框架的特点:Next.js是一个支持服务器端渲染和静态网站生成的React框架,适合构建现代的Web应用。
- TypeScript的作用和优势:TypeScript是JavaScript的一个超集,它提供了静态类型检查等特性,有助于提高代码质量和可维护性。
- 项目资源命名习惯:通常项目会有一个主目录,用来存放项目的源代码和核心配置文件,以便于项目的版本控制和团队协作。
以上内容基于给定的信息进行了深入的分析,为理解该项目的构建、运行方式以及技术栈提供了基础。在实际开发中,开发者应当参考更详细的文档和指南,以更高效地管理和部署基于Docker和TypeScript的Next.js项目。
"互动学习:行动中的多样性与论文攻读经历"
多样性她- 事实上SCI NCES你的时间表ECOLEDO C Tora SC和NCESPOUR l’Ingén学习互动,互动学习以行动为中心的强化学习学会互动,互动学习,以行动为中心的强化学习计算机科学博士论文于2021年9月28日在Villeneuve d'Asq公开支持马修·瑟林评审团主席法布里斯·勒菲弗尔阿维尼翁大学教授论文指导奥利维尔·皮耶昆谷歌研究教授:智囊团论文联合主任菲利普·普雷教授,大学。里尔/CRISTAL/因里亚报告员奥利维耶·西格德索邦大学报告员卢多维奇·德诺耶教授,Facebook /索邦大学审查员越南圣迈IMT Atlantic高级讲师邀请弗洛里安·斯特鲁布博士,Deepmind对于那些及时看到自己错误的人...3谢谢你首先,我要感谢我的两位博士生导师Olivier和Philippe。奥利维尔,"站在巨人的肩膀上"这句话对你来说完全有意义了。从科学上讲,你知道在这篇论文的(许多)错误中,你是我可以依
【热传递模型的终极指南】:掌握分类、仿真设计、优化与故障诊断的18大秘诀

# 摘要
热传递模型在工程和物理学中占有重要地位,对于提高热交换效率和散热设计至关重要。本文系统性地介绍了热传递模型的基础知识、分类以及在实际中的应用案例。文章详细阐述了导热、对流换热以及辐射传热的基本原理,并对不同类型的热传递模型进行了分类,包括稳态与非稳态模型、一维到三维模型和线性与非线性模型。通过仿真设计章节,文章展示了如何选择合适的仿真软件、构建几何模型、设置材料属性和
python经典题型和解题代码
Python的经典题型通常涵盖了基础语法、数据结构、算法、函数式编程、文件操作、异常处理以及网络爬虫等内容。以下是一些常见的题目及其简单示例:
1. **基础题**:
- 示例:打印九九乘法表
```python
for i in range(1, 10):
print(f"{i} * {i} = {i*i}")
```
2. **数据结构**:
- 示例:实现队列(使用列表)
```python
class Queue:
def __init__(self):
宠物控制台应用程序:Java编程实践与反思
资源摘要信息:"宠物控制台:统一编码练习"
本节内容将围绕PetStore控制台应用程序的开发细节进行深入解析,包括其结构、异常处理、toString方法的实现以及命令行参数的应用。
标题中提到的“宠物控制台:统一编码练习”指的是创建一个用于管理宠物信息的控制台应用程序。这个项目通常被用作学习编程语言(如Java)和理解应用程序结构的练习。在这个上下文中,“宠物”一词代表了应用程序处理的数据对象,而“控制台”则明确了用户与程序交互的界面类型。
描述部分反映了开发者在创建这个控制台应用程序的过程中遇到的挑战和学习体验。开发者提到,这是他第一次不依赖MVC RESTful API格式的代码,而是直接使用Java编写控制台应用程序。这表明了从基于Web的应用程序转向桌面应用程序的开发者可能会面临的转变和挑战。
在描述中,开发者提到了关于项目结构的一些想法,说明了项目结构不是完全遵循约定,部分结构是自行组合的,部分是从实践中学习而来的。这说明了开发者在学习过程中可能会采用灵活的编码实践,以适应不同的编程任务。
异常处理是编程中的一个重要方面,开发者表示在此练习中没有处理异常,而是通过避免null值来“闪避”一些潜在的问题。这可能表明开发者更关注于快速原型的实现,而不是在学习阶段就深入处理异常情况。虽然这样的做法在实际项目中是不被推荐的,但它可以帮助初学者快速理解程序逻辑。
在toString方法的实现上,开发者明确表示该方法并不遵循常规的约定,而是为了让控制台读数更易于人类阅读,这表明开发者在这个阶段更注重于输出结果的可读性,而不是遵循某些严格的编程习惯。
最后,开发者谈到了希望包括一些命令行参数来控制数据输出,但因为这不是最小可行性产品(MVP)的一部分,所以没有实现。在Java等语言中,使用命令行参数是控制应用程序行为的常见做法,通常通过解析`main`方法的`args`参数来实现。
标签中提到的"Java"是本练习的主要编程语言。Java是一种广泛使用的通用编程语言,它特别适合于大型系统开发。Java编写的控制台应用程序能够跨平台运行,因为Java虚拟机(JVM)为它提供了跨平台的兼容性。
从提供的文件名称列表“pet-console-develop”可以推测出,这个文件夹可能包含了所有与开发PetStore控制台应用程序相关的源代码、文档和其他资源。由于开发者提到的是“练习”,可以推断这是一个用于学习和实验的项目,而非一个完整的商业软件。
总结以上分析,PetStore控制台应用程序是一个用于教学目的的Java项目,它提供了对于控制台应用程序结构、异常处理、方法重写以及命令行参数使用等方面的实践学习。这个练习可以帮助初学者或经验较少的开发者学习如何构建简单的桌面应用程序,并逐步理解更多的编程概念。