invocation获取数据库驱动
时间: 2024-01-15 13:03:14 浏览: 53
您可以使用Java的反射机制来加载数据库驱动并创建数据库连接。以下是一个示例代码片段:
```java
Class.forName("com.mysql.jdbc.Driver"); // 加载MySQL驱动
String url = "jdbc:mysql://localhost:3306/mydatabase"; // 数据库连接URL
String user = "myusername"; // 数据库用户名
String password = "mypassword"; // 数据库密码
Connection conn = DriverManager.getConnection(url, user, password); // 创建数据库连接
```
请注意,上述示例中使用的是MySQL数据库驱动,您需要根据您使用的数据库类型选择正确的驱动。
相关问题
invocation 获取sqlSession
您可以通过以下代码获取 MyBatis 中的 SqlSession 对象:
```java
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
// 创建 SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
// 获取 SqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
```
请注意,这里假设您已经有了一个名为 `mybatis-config.xml` 的 MyBatis 配置文件。如果您还没有,请先创建一个。此外,获取 SqlSession 后,您需要使用它来执行数据库操作。例如:
```java
try {
// 执行数据库操作
// ...
sqlSession.commit(); // 提交事务
} catch (Exception e) {
sqlSession.rollback(); // 回滚事务
} finally {
sqlSession.close(); // 关闭 SqlSession
}
```
joinpoint获取methodInvocation
您可以使用AspectJ来获取方法执行时的连接点(joinpoint)和方法调用(method invocation)信息。AspectJ是一个面向切面编程的扩展,它可以与Java一起使用。
要获取方法执行时的连接点信息,您可以使用AspectJ的@Around注解来定义一个环绕通知(around advice)。在环绕通知中,您可以通过ProceedingJoinPoint参数来获取方法执行的连接点信息。
下面是一个示例代码片段,展示了如何使用AspectJ的@Around注解来获取方法执行时的连接点和方法调用信息:
```java
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
@Aspect
public class MethodInvocationAspect {
@Around("execution(* com.example.myapp.MyClass.myMethod(..))")
public Object aroundMethod(ProceedingJoinPoint joinPoint) throws Throwable {
// 获取方法调用的连接点信息
String methodName = joinPoint.getSignature().getName();
Object[] args = joinPoint.getArgs();
// 输出连接点和方法调用信息
System.out.println("Method name: " + methodName);
System.out.println("Arguments: " + Arrays.toString(args));
// 执行原始方法
Object result = joinPoint.proceed();
// 在方法执行后可以进行一些操作
return result;
}
}
```
在上面的示例中,@Around注解指定了要拦截的方法执行连接点,这里拦截了名为"myMethod"的方法。在aroundMethod方法中,可以通过ProceedingJoinPoint参数获取方法调用的连接点信息,如方法名和参数。然后,您可以根据需要执行其他操作,并调用joinPoint.proceed()来继续执行原始方法。
请注意,使用AspectJ需要进行相关配置,并将AspectJ的相关库添加到项目中。具体的配置和使用方式可以参考AspectJ的官方文档。
希望这个示例可以帮助您获取方法执行时的连接点和方法调用信息!如果您有任何疑问,请随时提问。
相关推荐
最新推荐
struts2 MySQL数据库 增删查改
要与MySQL数据库交互,需要使用数据库驱动,例如`org.gjt.mm.mysql.Driver`。在Action类中,可以通过`java.sql.Connection`接口创建数据库连接,并使用`java.sql.Statement`或`java.sql.PreparedStatement`对象来...
2进制3位数过去现在将来输赢公式代码.txt
2进制3位数过去现在将来输赢公式代码
AirKiss技术详解:无线传递信息与智能家居连接
AirKiss原理是一种创新的信息传输技术,主要用于解决智能设备与外界无物理连接时的网络配置问题。传统的设备配置通常涉及有线或无线连接,如通过路由器的Web界面输入WiFi密码。然而,AirKiss技术简化了这一过程,允许用户通过智能手机或其他移动设备,无需任何实际连接,就能将网络信息(如WiFi SSID和密码)“隔空”传递给目标设备。
具体实现步骤如下:
1. **AirKiss工作原理示例**:智能插座作为一个信息孤岛,没有物理连接,通过AirKiss技术,用户的微信客户端可以直接传输SSID和密码给插座,插座收到这些信息后,可以自动接入预先设置好的WiFi网络。
2. **传统配置对比**:以路由器和无线摄像头为例,常规配置需要用户手动设置:首先,通过有线连接电脑到路由器,访问设置界面输入运营商账号和密码;其次,手机扫描并连接到路由器,进行子网配置;最后,摄像头连接家庭路由器后,会自动寻找厂商服务器进行心跳包发送以保持连接。
3. **AirKiss的优势**:AirKiss技术简化了配置流程,减少了硬件交互,特别是对于那些没有显示屏、按键或网络连接功能的设备(如无线摄像头),用户不再需要手动输入复杂的网络设置,只需通过手机轻轻一碰或发送一条消息即可完成设备的联网。这提高了用户体验,降低了操作复杂度,并节省了时间。
4. **应用场景扩展**:AirKiss技术不仅适用于智能家居设备,也适用于物联网(IoT)场景中的各种设备,如智能门锁、智能灯泡等,只要有接收AirKiss信息的能力,它们就能快速接入网络,实现远程控制和数据交互。
AirKiss原理是利用先进的无线通讯技术,结合移动设备的便利性,构建了一种无需物理连接的设备网络配置方式,极大地提升了物联网设备的易用性和智能化水平。这种技术在未来智能家居和物联网设备的普及中,有望发挥重要作用。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
交叉验证全解析:数据挖掘中的黄金标准与优化策略
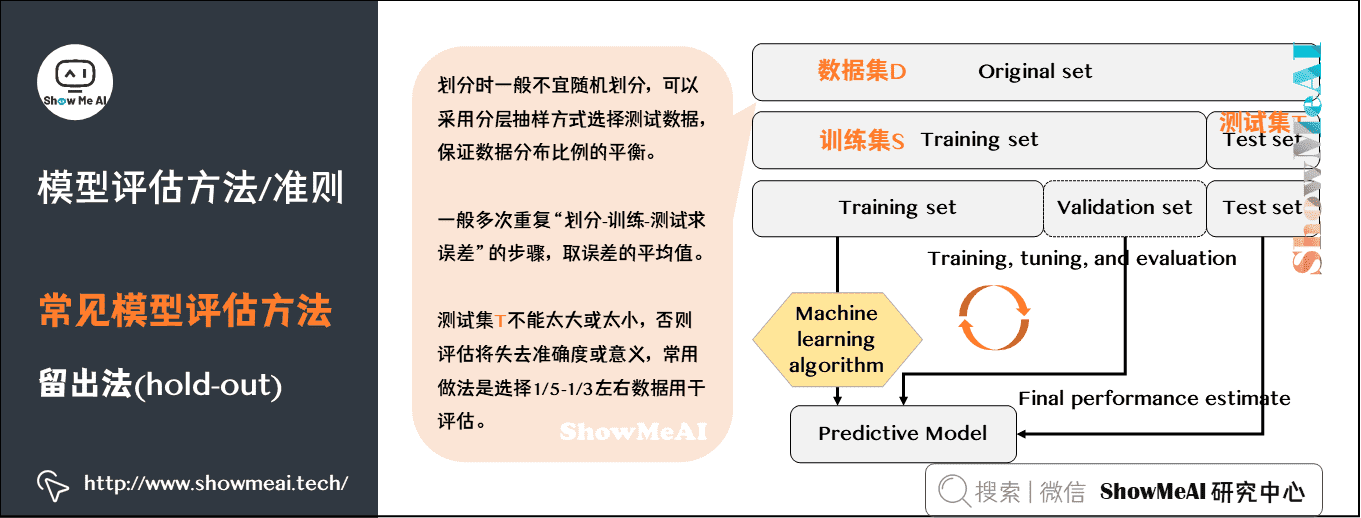
# 1. 交叉验证的基本概念和重要性
## 1.1 交叉验证的定义
交叉验证是一种统计方法,用于评估并改进机器学习模型的泛化能力。它通过将数据集分为几个小的“折”(或称为“子集”),然后迭代使用这些数据子集来训练和测试模型,从而得到模型性能的更准确估计。
## 1.2 交叉验证的重要性
在机器学习过程中,我们通常面临一个重要的问题:模型可能对训练数据过度拟合,而不能很好地推广到新数据
在交换机上创建 VLAN10、VLAN20和VLAN30,将交换机 B 的 2-5 接口加入到 VLAN 10 中 用ensp写出配置命令
在交换机上配置VLAN并分配接口到特定的VLAN中,通常需要登录到交换机的命令行界面。以下是在华为交换机上使用eNSP(Enterprise Network Simulation Platform,企业网络模拟平台)模拟器进行VLAN配置的基本步骤和命令:
首先,进入系统视图:
```
system-view
```
然后创建VLAN10、VLAN20和VLAN30:
```
vlan 10
vlan 20
vlan 30
```
接下来,将交换机B的2到5端口加入到VLAN10中,假设交换机B的接口编号为GigabitEthernet0/0/2至GigabitEthernet0/0/5
Hibernate主键生成策略详解
"Hibernate各种主键生成策略与配置详解"
在关系型数据库中,主键是表中的一个或一组字段,用于唯一标识一条记录。在使用Hibernate进行持久化操作时,主键的生成策略是一个关键的配置,因为它直接影响到数据的插入和管理。以下是Hibernate支持的各种主键生成策略的详细解释:
1. assigned: 这种策略要求开发者在保存对象之前手动设置主键值。Hibernate不参与主键的生成,因此这种方式可以跨数据库,但并不推荐,因为可能导致数据一致性问题。
2. increment: Hibernate会从数据库中获取当前主键的最大值,并在内存中递增生成新的主键。由于这个过程不依赖于数据库的序列或自增特性,它可以跨数据库使用。然而,当多进程并发访问时,可能会出现主键冲突,导致Duplicate entry错误。
3. hilo: Hi-Lo算法是一种优化的增量策略,它在一个较大的范围内生成主键,减少数据库交互。在每个session中,它会从数据库获取一个较大的范围,然后在内存中分配,降低主键碰撞的风险。
4. seqhilo: 类似于hilo,但它使用数据库的序列来获取范围,适合Oracle等支持序列的数据库。
5. sequence: 这个策略依赖于数据库提供的序列,如Oracle、PostgreSQL等,直接使用数据库序列生成主键,保证全局唯一性。
6. identity: 适用于像MySQL这样的数据库,它们支持自动增长的主键。Hibernate在插入记录时让数据库自动为新行生成主键。
7. native: 根据所连接的数据库类型,自动选择最合适的主键生成策略,如identity、sequence或hilo。
8. uuid: 使用UUID算法生成128位的唯一标识符,适用于分布式环境,无需数据库支持。
9. guid: 类似于uuid,但根据不同的实现可能会有所不同,通常在Windows环境下生成的是GUID字符串。
10. foreign: 通过引用另一个表的主键来生成当前表的主键,适用于关联实体的情况。
11. select: 在插入之前,通过执行SQL查询来获取主键值,这种方式需要开发者提供定制的SQL语句。
12. 注释方式配置: 可以通过在Java实体类的@Id和@GeneratedValue注解中指定generator属性来配置自定义的主键生成策略。
13. 小结: Hibernate的主键生成策略选择应基于数据库特性、性能需求以及是否需要跨数据库兼容等因素。在实际应用中,需要根据项目具体需求选择最适合的策略。
注意,合理选择主键生成策略对于数据库性能和数据一致性至关重要。例如,increment策略在多进程环境下可能会出现问题,而sequence和identity策略则更安全,但可能不适合所有数据库系统。因此,开发者应充分理解每种策略的优缺点,并结合实际情况作出决策。
"互动学习:行动中的多样性与论文攻读经历"
多样性她- 事实上SCI NCES你的时间表ECOLEDO C Tora SC和NCESPOUR l’Ingén学习互动,互动学习以行动为中心的强化学习学会互动,互动学习,以行动为中心的强化学习计算机科学博士论文于2021年9月28日在Villeneuve d'Asq公开支持马修·瑟林评审团主席法布里斯·勒菲弗尔阿维尼翁大学教授论文指导奥利维尔·皮耶昆谷歌研究教授:智囊团论文联合主任菲利普·普雷教授,大学。里尔/CRISTAL/因里亚报告员奥利维耶·西格德索邦大学报告员卢多维奇·德诺耶教授,Facebook /索邦大学审查员越南圣迈IMT Atlantic高级讲师邀请弗洛里安·斯特鲁布博士,Deepmind对于那些及时看到自己错误的人...3谢谢你首先,我要感谢我的两位博士生导师Olivier和Philippe。奥利维尔,"站在巨人的肩膀上"这句话对你来说完全有意义了。从科学上讲,你知道在这篇论文的(许多)错误中,你是我可以依
【数据挖掘模型评估】:AUC-ROC曲线深度剖析及应用

# 1. 数据挖掘模型评估基础
在数据挖掘领域,评估一个模型的性能是至关重要的环节。这不仅关系到模型是否能够满足预期任务的需求,而且还涉及到模型泛化能力的判定。传统上,模型的评估指标包括准确度、召回率、精确率等。然而,这些指标在面对不平衡数据集时可能会产生误导。因此,数据挖掘者需要更全面和深入的评估方法,而R
hbase建表,插入数据
HBase是一个开源的非关系型分布式数据库(NoSQL),它基于Google的Bigtable模型,适用于存储大量稀疏的数据集。HBase的数据模型由行、列和时间戳组成,数据是按照列族(Column Family)存储的。下面是使用HBase进行建表和插入数据的基本步骤:
1. 建表
在HBase中建表主要涉及确定表名和列族。使用HBase Shell或者编程API可以创建一个新的表。例如,在HBase Shell中创建一个名为`my_table`的表,可以按照以下命令操作:
```shell
create 'my_table', 'cf1', 'cf2'
```
上述命令创建了一个新表