python transformer语音识别
时间: 2023-05-13 17:02:35 浏览: 80
Python transformer语音识别是指利用Python语言编写的transformer模型对语音数据进行识别的过程。这种技术可用于自然语言处理、语音识别、翻译等方面。
在语音识别方面,利用transformer模型可以更好地进行聚焦机制,即将注意力集中在输入的某些部分以提高识别的准确性。同时,该技术还具有优秀的适应性和泛化能力,针对不同的语种和口音也可以进行很好的识别。
Python作为一种广泛应用于人工智能领域的编程语言,提供了包括TensorFlow、PyTorch、Keras等在内的多种深度学习框架和工具包,能够支持大规模的模型训练和部署。
总的来说,Python transformer语音识别技术在语音识别领域具有广泛的应用前景,是一个十分有价值和重要的研究方向。
相关问题
Transformer 语音识别代码
Transformer是一种基于自注意力机制的神经网络模型,广泛应用于自然语言处理任务中,如机器翻译、文本生成等。在语音识别领域,Transformer也被用于构建端到端的语音识别系统。
下面是一个简单的Transformer语音识别代码示例:
```python
import torch
import torch.nn as nnimport torch.nn.functional as F
class TransformerASR(nn.Module):
def __init__(self, input_dim,_dim, d_model, nhead, num_layers):
super(TransformerASR, self).__init__()
self.embedding = nn.Linear(input_dim, d_model)
self.transformer = nn.Transformer(d_model, nhead, num_layers)
self.fc = nn.Linear(d_model, output_dim)
def forward(self, x):
x = self.embedding(x)
x = x.permute(1, 0, 2) # 调整输入形状为(seq_len, batch_size, input_dim)
output = self.transformer(x)
output = output.permute(1, 0, 2) # 调整输出形状为(batch_size, seq_len, d_model)
output = self.fc(output)
return F.log_softmax(output, dim=-1)
```
在这个代码示例中,`TransformerASR`类定义了一个基本的Transformer语音识别模型。它包含了一个线性层用于输入特征的维度转换,一个`nn.Transformer`模块用于实现Transformer的自注意力机制,以及一个线性层用于输出类别的预测。在`forward`方法中,输入特征经过线性层和变换后,传入Transformer模块进行处理,最后通过线性层和log_softmax函数得到类别的预测结果。
transformer语音识别代码
以下是一个使用Transformer进行语音识别的Python代码示例:
```python
import torch
import torch.nn as nn
import torch.optim as optim
import torchaudio
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
# Define the dataset for loading the audio data
class AudioDataset(Dataset):
def __init__(self, file_paths):
self.file_paths = file_paths
def __len__(self):
return len(self.file_paths)
def __getitem__(self, idx):
waveform, sample_rate = torchaudio.load(self.file_paths[idx])
return waveform, sample_rate
# Define the Transformer model
class TransformerModel(nn.Module):
def __init__(self, input_dim, output_dim, d_model, nhead, num_layers, dim_feedforward, dropout):
super(TransformerModel, self).__init__()
self.input_proj = nn.Linear(input_dim, d_model)
encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
self.output_proj = nn.Linear(d_model, output_dim)
def forward(self, src):
src = self.input_proj(src)
src = src.permute(1, 0, 2)
output = self.transformer_encoder(src)
output = output.permute(1, 0, 2)
output = self.output_proj(output)
return output
# Set the hyperparameters
input_dim = 1
output_dim = 29 # Number of phonemes in English language
d_model = 512
nhead = 8
num_layers = 6
dim_feedforward = 2048
dropout = 0.1
lr = 0.0001
batch_size = 32
epochs = 10
# Load the audio dataset and create the dataloader
file_paths = ["audio1.wav", "audio2.wav", ...]
audio_dataset = AudioDataset(file_paths)
audio_dataloader = DataLoader(audio_dataset, batch_size=batch_size, shuffle=True)
# Initialize the Transformer model and the optimizer
model = TransformerModel(input_dim, output_dim, d_model, nhead, num_layers, dim_feedforward, dropout)
optimizer = optim.Adam(model.parameters(), lr=lr)
# Define the loss function
criterion = nn.CrossEntropyLoss()
# Train the Transformer model
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(audio_dataloader, 0):
inputs, labels = data
inputs = inputs.squeeze().transpose(0, 1) # Shape: (seq_len, batch_size, input_dim)
labels = labels.squeeze() - 1 # Subtract 1 to convert phoneme index from 1-based to 0-based
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs.view(-1, output_dim), labels.view(-1))
loss.backward()
optimizer.step()
running_loss += loss.item()
print("Epoch %d loss: %.3f" % (epoch+1, running_loss / len(audio_dataloader)))
```
请注意,此示例是基于一个简单的英语语音识别任务,使用TIMIT数据集。在实际使用时,你需要根据你的数据集和任务进行适当的修改。
相关推荐
最新推荐
Transformers for Natural Language Processing.pdf
图书简介 该书将带您学习使用Python的NLP,并研究了由Google,Facebook,...将Python,TensorFlow和Keras程序应用于情感分析,文本摘要,语音识别,机器翻译等 测量关键变压器的生产率,以定义其范围,潜力和生产限制
2024-2030全球及中国PCB接触式探头行业研究及十五五规划分析报告.docx
2024-2030全球及中国PCB接触式探头行业研究及十五五规划分析报告
网站界面设计mortal0418代码
网站界面设计mortal0418代码
2023年中国辣条食品行业创新及消费需求洞察报告.pptx
随着时间的推移,中国辣条食品行业在2023年迎来了新的发展机遇和挑战。根据《2023年中国辣条食品行业创新及消费需求洞察报告》,辣条食品作为一种以面粉、豆类、薯类等原料为基础,添加辣椒、调味料等辅料制成的食品,在中国市场拥有着广阔的消费群体和市场潜力。
在行业概述部分,报告首先介绍了辣条食品的定义和分类,强调了辣条食品的多样性和口味特点,满足消费者不同的口味需求。随后,报告回顾了辣条食品行业的发展历程,指出其经历了从传统手工制作到现代化机械生产的转变,市场规模不断扩大,产品种类也不断增加。报告还指出,随着消费者对健康饮食的关注增加,辣条食品行业也开始向健康、营养的方向发展,倡导绿色、有机的生产方式。
在行业创新洞察部分,报告介绍了辣条食品行业的创新趋势和发展动向。报告指出,随着科技的不断进步,辣条食品行业在生产工艺、包装设计、营销方式等方面都出现了新的创新,提升了产品的品质和竞争力。同时,报告还分析了未来可能出现的新产品和新技术,为行业发展提供了新的思路和机遇。
消费需求洞察部分则重点关注了消费者对辣条食品的需求和偏好。报告通过调查和分析发现,消费者在选择辣条食品时更加注重健康、营养、口味的多样性,对产品的品质和安全性提出了更高的要求。因此,未来行业需要加强产品研发和品牌建设,提高产品的营养价值和口感体验,以满足消费者不断升级的需求。
在市场竞争格局部分,报告对行业内主要企业的市场地位、产品销量、市场份额等进行了分析比较。报告发现,中国辣条食品行业竞争激烈,主要企业之间存在着激烈的价格战和营销竞争,产品同质化严重。因此,企业需要加强品牌建设,提升产品品质,寻求差异化竞争的突破口。
最后,在行业发展趋势与展望部分,报告对未来辣条食品行业的发展趋势进行了展望和预测。报告认为,随着消费者对健康、有机食品的需求增加,辣条食品行业将进一步向健康、营养、绿色的方向发展,加强与农业合作,推动产业升级。同时,随着科技的不断进步,辣条食品行业还将迎来更多的创新和发展机遇,为行业的持续发展注入新的动力。
综上所述,《2023年中国辣条食品行业创新及消费需求洞察报告》全面深入地分析了中国辣条食品行业的发展现状、创新动向和消费需求,为行业的未来发展提供了重要的参考和借鉴。随着消费者消费观念的不断升级和科技的持续发展,中国辣条食品行业有望迎来更加广阔的发展空间,实现可持续发展和行业繁荣。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
学习率衰减策略及调参技巧:在CNN中的精准应用指南
# 1. 学习率衰减策略概述
学习率衰减是深度学习中常用的优化技巧,旨在调整模型训练时的学习率,以提高模型性能和收敛速度。在训练迭代过程中,通过逐步减小学习率的数值,模型在接近收敛时可以更精细地调整参数,避免在局部最优点处震荡。学习率衰减策略种类繁多,包括固定衰减率、指数衰减、阶梯衰减和余弦衰减等,每种方法都有适用的场景和优势。掌握不同学习率衰减策略,可以帮助深度学习从业者更好地训练和调优模型。
# 2. 深入理解学习率衰减
学习率衰减在深度学习中扮演着重要的角色,能够帮助模型更快地收敛,并提高训练效率和泛化能力。在本章节中,我们将深入理解学习率衰减的基本概念、原理以及常见方法。
##
如何让restTemplate call到一个mock的数据
要使用 `RestTemplate` 调用一个模拟的数据,你可以使用 `MockRestServiceServer` 类来模拟服务端的响应。下面是一个示例代码:
```java
import org.springframework.http.HttpMethod;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.test
2023年半导体行业20强品牌.pptx
2023年半导体行业20强品牌汇报人文小库于2024年1月10日提交了《2023年半导体行业20强品牌》的报告,报告内容主要包括品牌概述、产品线分析、技术创新、市场趋势和品牌策略。根据报告显示的数据和分析,可以看出各品牌在半导体行业中的综合实力和发展情况。
在品牌概述部分,文小库对2023年半导体行业20强品牌进行了排名,主要根据市场份额、技术创新能力和品牌知名度等多个指标进行评估。通过综合评估,得出了各品牌在半导体行业中的排名,并分析了各品牌的市场份额变化情况,了解了各品牌在市场中的竞争态势和发展趋势。此外,还对各品牌的品牌影响力进行了分析,包括对行业发展的推动作用和对消费者的影响力等方面进行评估,从品牌知名度和品牌价值两个维度来评判各品牌的实力。
在产品线分析部分,报告详细描述了微处理器在半导体行业中的核心地位,这是主要应用于计算机、手机、平板等智能终端设备中的关键产品。通过对产品线进行详细分析,可以了解各品牌在半导体领域中的产品布局和市场表现,为后续的市场策略制定提供了重要的参考信息。
在技术创新方面,报告也对各品牌在技术创新方面的表现进行了评估,这是半导体行业发展的关键驱动力之一。通过分析各品牌在技术研发、产品设计和生产制造等方面的创新能力,可以评判各品牌在未来发展中的竞争优势和潜力,为品牌策略的制定提供重要依据。
在市场趋势和品牌策略方面,报告分析了半导体行业的发展趋势和竞争格局,为各品牌制定市场策略和品牌推广提供了重要参考。针对未来市场发展的趋势,各品牌需要不断加强技术创新、提升品牌影响力,以及制定有效的市场推广策略,来保持在行业中的竞争优势。
综上所述,在2023年半导体行业20强品牌报告中,通过对各品牌的综合排名、产品线分析、技术创新、市场趋势和品牌策略等方面的评估和分析,展现了各品牌在半导体行业中的实力和发展状态,为半导体行业的未来发展提供了重要的参考和指导。
"互动学习:行动中的多样性与论文攻读经历"
多样性她- 事实上SCI NCES你的时间表ECOLEDO C Tora SC和NCESPOUR l’Ingén学习互动,互动学习以行动为中心的强化学习学会互动,互动学习,以行动为中心的强化学习计算机科学博士论文于2021年9月28日在Villeneuve d'Asq公开支持马修·瑟林评审团主席法布里斯·勒菲弗尔阿维尼翁大学教授论文指导奥利维尔·皮耶昆谷歌研究教授:智囊团论文联合主任菲利普·普雷教授,大学。里尔/CRISTAL/因里亚报告员奥利维耶·西格德索邦大学报告员卢多维奇·德诺耶教授,Facebook /索邦大学审查员越南圣迈IMT Atlantic高级讲师邀请弗洛里安·斯特鲁布博士,Deepmind对于那些及时看到自己错误的人...3谢谢你首先,我要感谢我的两位博士生导师Olivier和Philippe。奥利维尔,"站在巨人的肩膀上"这句话对你来说完全有意义了。从科学上讲,你知道在这篇论文的(许多)错误中,你是我可以依
量化与剪枝技术在CNN模型中的神奇应用及效果评估
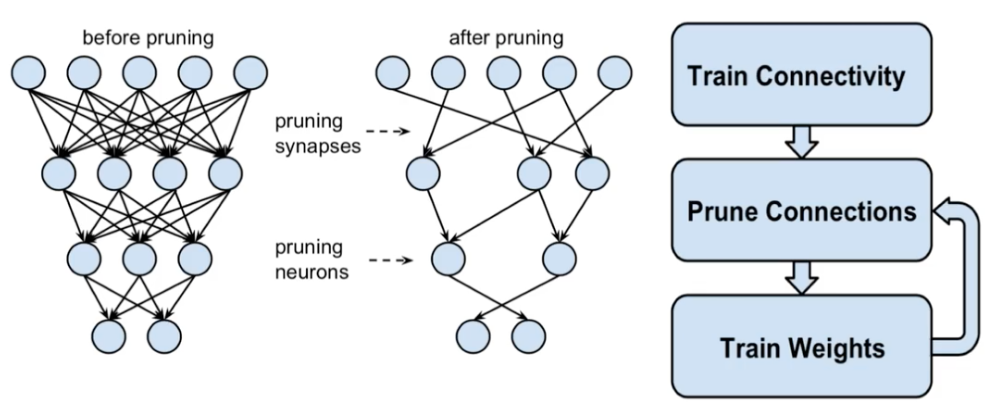
# 1. 量化与剪枝技术在CNN模型中的概览
在深度学习领域,量化与剪枝技术作为优化模型的重要手段,近年来备受关注。量化技术主要通过减少模型参数的位数,降低模型的计算复杂度,进而提升模型的推理速度。而剪枝技术则通过去除冗余的连接和神经元,减小模型的规模,提高模型的泛化能力和效率。本章将对这两项技术进行综述,为后续章节的深入探讨奠定基础。
# 2. 深入理解量化技术
### 2.1 量化技术概述
量化技术