larger batch size
时间: 2024-04-19 19:21:22 浏览: 136
根据提供的引用内容,关于batch size的大小,有以下几点需要注意:
1. 对于分类算法,较大的batch size一般没有明显的差别,因为一般的GPU显存都能cover住较大的batch设置[^1]。
2. 在目标检测、分割以及视频相关的算法中,由于输入图像较大、维度多样以及算法本身原因等,batch size一般都设置比较小。
3. 使用大的batch size可能对身体健康有害,并且对测试集的error不利。
4. 较小的batch size可能导致BN层所计算的统计信息的可靠性较差,从而影响最后的结果。
综上所述,batch size的选择应根据具体的算法和任务需求来确定,而不是简单地认为越大越好。在分类算法中,较大的batch size可能没有明显的差别,但在目标检测、分割和视频相关的算法中,由于输入图像较大和维度多样性等因素,较小的batch size可能更适合。此外,使用过大的batch size可能对身体健康有害,并且对测试集的error不利。
相关问题
yolov5 batchsize
### YOLOv5 Batch Size Configuration and Impact on Training
In the context of configuring YOLOv5 for training with a specific dataset such as VOC, setting an appropriate `batch-size` is crucial. When running the training script using Python, one specifies this parameter directly through command-line arguments like so:
```bash
python train.py --weights=./weights/yolov5s.pt --cfg=./models/minivoc_yolov5s.yaml --data=./data/mini_voc.yaml --epochs=10 --batch-size=32
```
The chosen value here (`--batch-size=32`) indicates that during each iteration or step within an epoch, 32 images will be processed simultaneously before updating model weights based on computed gradients.
#### Influence of Batch Size on Model Performance
Selecting too small a batch size can lead to unstable gradient estimates because fewer samples contribute less information about how weight updates should occur; conversely, excessively large batches may cause overfitting since they provide overly confident but potentially biased updates which do not generalize well beyond seen data points[^1].
A moderate approach often yields better results by balancing between these extremes while also considering computational resources available—larger values require more memory yet allow faster convergence due to smoother loss landscapes explored per update cycle when enough hardware support exists.
#### Practical Considerations for Setting Batch Size
For most applications including object detection tasks handled via architectures similar to those found in YOLO series models, starting from default recommendations provided alongside pre-trained checkpoints usually serves as good practice unless there are compelling reasons otherwise dictated either experimentally derived insights peculiarly relevant towards particular datasets being used or limitations imposed upon computing environments employed throughout experimentation phases.
When adjusting configurations related specifically to mini-batch processing sizes, it's important to monitor both performance metrics associated closely with learning efficiency (such as validation accuracy improvements across epochs) along with resource utilization statistics pertinent especially concerning GPU usage patterns ensuring neither underutilization nor saturation occurs unexpectedly leading possibly suboptimal outcomes overall.
--related questions--
1. How does changing the number of classes affect YOLOv5’s architecture?
2. What modifications need to be made to adapt YOLOv5 for custom datasets other than VOC?
3. Can TensorBoard visualize all aspects of YOLOv5 training effectively?
4. Are there alternative methods besides altering batch size for improving YOLOv5 training stability?
Minibatch size
Minibatch size refers to the number of examples or instances of data that are processed together in a single iteration or batch during training of a machine learning model. The size of the minibatch is typically smaller than the total size of the training dataset, and is chosen to balance the computational efficiency and the quality of the model's optimization. A larger minibatch size can lead to faster convergence, but may also require more memory and computational resources, while a smaller minibatch size may result in slower convergence and may require more training iterations to reach the same level of performance. The choice of minibatch size depends on the specific problem and the characteristics of the data and the model being trained.
阅读全文
相关推荐
大家在看
JESD47I中文版.docx
JESD47I中文版.docx
sdram 资料 原理。
控制信号与输出数据的时序图。初始化时序图。
运算放大器的设计及ADS仿真设计——两级运算放大器仿真设计
设计要求
(1) 总电流5000;
(4) 负载电容=1pF;
(5) 闭环电压增益=4(闭环误差精度<0.1%);
(6) 闭环阶跃响应达到1%精度时的建立时间<5 ns。
目录
设计要求
设计原理
参数初值计算
确定各晶体管参数
第一级晶体管的DC仿真以及参数设计
确定 M1、 M3 的参数
确定M0的参数
确定 M5、 M7的参数
第二级晶体管的DC仿真以及参数设计
确定 M9、 M10 的参数
确定 M11、 M12 的参数
晶体管参数总结
搭建二级仿真电路
搭建第一级仿真电路
搭建偏置电路
搭建两级运放以及子电路
共模反馈设计以及稳定性分析
闭环增益仿真
瞬态仿真
加入负载电容的仿真
结果分析及心得体会
《Web服务统一身份认证协议设计与实现》本科毕业论文一万字.doc
《Web服务统一身份认证协议设计与实现》本科毕业论文【一万字】.doc
目录如下,希望对你有所帮助:
第一章 绪论
1.1 研究背景
1.2 研究目的和意义
1.3 研究内容和方法
1.4 论文结构安排
第二章 Web服务统一身份认证协议相关理论
2.1 Web服务统一身份认证概述
2.2 Web服务统一身份认证协议设计原则
第三章 Web服务统一身份认证协议设计
3.1 协议需求分析
3.2 协议设计与流程
第四章 Web服务统一身份认证协议实现
4.1 协议实现环境
4.2 协议实现步骤
第五章 Web服务统一身份认证协议测试与评估
5.1 协议测试方案设计
5.2 协议测试结果分析
第六章 总结与展望
6.1 研究总结
6.2 研究展望
[C#]文件中转站程序及源码
在网上看到一款名为“DropPoint文件复制中转站”的工具,于是自己尝试仿写一下。并且添加一个移动文件的功能。
用来提高复制粘贴文件效率的工具,它会给你一个临时中转悬浮框,只需要将一处或多处想要复制的文件拖拽到这个悬浮框,再一次性拖拽至目的地文件夹,就能高效完成复制粘贴及移动文件。
支持拖拽多个文件到悬浮框,并显示文件数量
将悬浮窗内的文件往目标文件夹拖拽即可实现复制,适用于整理文件
主要的功能实现:
1、实现文件拖拽功能,将文件或者文件夹拖拽到软件上
2、实现文件拖拽出来,将文件或目录拖拽到指定的位置
3、实现多文件添加,包含目录及文件
4、添加软件透明背景、软件置顶、文件计数
最新推荐
微软内部资料-SQL性能优化3
Lesson 2: Concepts – Batch and Transaction 31 Lesson 3: Concepts – Locks and Applications 51 Lesson 4: Information Collection and Analysis 63 Lesson 5: Concepts – Formulating and Implementing ...
OpenCV部署YOLOv5-pose人体姿态估计(C++和Python双版本).zip
OpenCV部署YOLOv5-pose人体姿态估计(C++和Python双版本).zip
[资源说明]
1、该项目是团队成员近期最新开发,代码完整,资料齐全,含设计文档等
2、上传的项目源码经过严格测试,功能完善且能正常运行,请放心下载使用!
3、本项目适合计算机相关专业(人工智能、通信工程、自动化、电子信息、物联网等)的高校学生、教师、科研工作者、行业从业者下载使用,可借鉴学习,也可直接作为毕业设计、课程设计、作业、项目初期立项演示等,也适合小白学习进阶,遇到问题不懂就问,欢迎交流。
4、如果基础还行,可以在此代码基础上进行修改,以实现其他功能,也可直接用于毕设、课设、作业等。
5、不懂配置和运行,可远程教学
欢迎下载,学习使用!
ARIMA+Transformer+LSTM心跳时间序列预测模型源码+设计文档(课设新开发项目).zip
ARIMA+Transformer+LSTM心跳时间序列预测模型源码+设计文档(课设新开发项目).zip
[资源说明]
1、该项目是团队成员近期最新开发,代码完整,资料齐全,含设计文档等
2、上传的项目源码经过严格测试,功能完善且能正常运行,请放心下载使用!
3、本项目适合计算机相关专业(人工智能、通信工程、自动化、电子信息、物联网等)的高校学生、教师、科研工作者、行业从业者下载使用,可借鉴学习,也可直接作为毕业设计、课程设计、作业、项目初期立项演示等,也适合小白学习进阶,遇到问题不懂就问,欢迎交流。
4、如果基础还行,可以在此代码基础上进行修改,以实现其他功能,也可直接用于毕设、课设、作业等。
5、不懂配置和运行,可远程教学
欢迎下载,学习使用!
体育馆管理系统(代码+数据库+LW)
摘 要
现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本体育馆管理系统就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大的数据信息,使用这种软件工具可以帮助管理人员提高事务处理效率,达到事半功倍的效果。此体育馆管理系统利用当下成熟完善的SSM框架,使用跨平台的可开发大型商业网站的Java语言,以及最受欢迎的RDBMS应用软件之一的Mysql数据库进行程序开发。实现了用户在线选择试题并完成答题,在线查看考核分数。管理员管理收货地址管理、购物车管理、场地管理、场地订单管理、字典管理、赛事管理、赛事收藏管理、赛事评价管理、赛事订单管理、商品管理、商品收藏管理、商品评价管理、商品订单管理、用户管理、管理员管理等功能。体育馆管理系统的开发根据操作人员需要设计的界面简洁美观,在功能模块布局上跟同类型网站保持一致,程序在实现基本要求功能时,也为数据信息面临的安全问题提供了一些实用的解决方案。可以说该程序在帮助管理者高效率地处理工作事务的同时,也实现了数据信息的整体化,规范化与自动化。
关键词:体育馆管理系
基于HTML、TypeScript、JavaScript的全面运动健康手环App设计源码
该项目是一款基于HTML、TypeScript和JavaScript全面构建的运动健康手环App设计源码,包含263个文件,涵盖124个TypeScript文件、93个SVG文件、10个JSON文件、10个PNG图片文件、9个JSON5文件、8个HTML文件、4个TS文件、2个gitignore文件和1个hvigorw文件。该App专注于提供全面的运动健康追踪功能,适用于追求健康生活方式的用户。
HTML挑战:30天技术学习之旅
资源摘要信息: "desafio-30dias"
标题 "desafio-30dias" 暗示这可能是一个与挑战或训练相关的项目,这在编程和学习新技能的上下文中相当常见。标题中的数字“30”很可能表明这个挑战涉及为期30天的时间框架。此外,由于标题是西班牙语,我们可以推测这个项目可能起源于或至少是针对西班牙语使用者的社区。标题本身没有透露技术上的具体内容,但挑战通常涉及一系列任务,旨在提升个人的某项技能或知识水平。
描述 "desafio-30dias" 并没有提供进一步的信息,它重复了标题的内容。因此,我们不能从中获得关于项目具体细节的额外信息。描述通常用于详细说明项目的性质、目标和期望成果,但由于这里没有具体描述,我们只能依靠标题和相关标签进行推测。
标签 "HTML" 表明这个挑战很可能与HTML(超文本标记语言)有关。HTML是构成网页和网页应用基础的标记语言,用于创建和定义内容的结构、格式和语义。由于标签指定了HTML,我们可以合理假设这个30天挑战的目的是学习或提升HTML技能。它可能包含创建网页、实现网页设计、理解HTML5的新特性等方面的任务。
压缩包子文件的文件名称列表 "desafio-30dias-master" 指向了一个可能包含挑战相关材料的压缩文件。文件名中的“master”表明这可能是一个主文件或包含最终版本材料的文件夹。通常,在版本控制系统如Git中,“master”分支代表项目的主分支,用于存放项目的稳定版本。考虑到这个文件名称的格式,它可能是一个包含所有相关文件和资源的ZIP或RAR压缩文件。
结合这些信息,我们可以推测,这个30天挑战可能涉及了一系列的编程任务和练习,旨在通过实践项目来提高对HTML的理解和应用能力。这些任务可能包括设计和开发静态和动态网页,学习如何使用HTML5增强网页的功能和用户体验,以及如何将HTML与CSS(层叠样式表)和JavaScript等其他技术结合,制作出丰富的交互式网站。
综上所述,这个项目可能是一个为期30天的HTML学习计划,设计给希望提升前端开发能力的开发者,尤其是那些对HTML基础和最新标准感兴趣的人。挑战可能包含了理论学习和实践练习,鼓励参与者通过构建实际项目来学习和巩固知识点。通过这样的学习过程,参与者可以提高在现代网页开发环境中的竞争力,为创建更加复杂和引人入胜的网页打下坚实的基础。
【CodeBlocks精通指南】:一步到位安装wxWidgets库(新手必备)

# 摘要
本文旨在为使用CodeBlocks和wxWidgets库的开发者提供详细的安装、配置、实践操作指南和性能优化建议。文章首先介绍了CodeBlocks和wxWidgets库的基本概念和安装流程,然后深入探讨了CodeBlocks的高级功能定制和wxWidgets的架构特性。随后,通过实践操作章节,指导读者如何创建和运行一个wxWidgets项目,包括界面设计、事件
andorid studio 配置ERROR: Cause: unable to find valid certification path to requested target
### 解决 Android Studio SSL 证书验证问题
当遇到 `unable to find valid certification path` 错误时,这通常意味着 Java 运行环境无法识别服务器提供的 SSL 证书。解决方案涉及更新本地的信任库或调整项目中的网络请求设置。
#### 方法一:安装自定义 CA 证书到 JDK 中
对于企业内部使用的私有 CA 颁发的证书,可以将其导入至 JRE 的信任库中:
1. 获取 `.crt` 或者 `.cer` 文件形式的企业根证书;
2. 使用命令行工具 keytool 将其加入 cacerts 文件内:
```
VC++实现文件顺序读写操作的技巧与实践
资源摘要信息:"vc++文件的顺序读写操作"
在计算机编程中,文件的顺序读写操作是最基础的操作之一,尤其在使用C++语言进行开发时,了解和掌握文件的顺序读写操作是十分重要的。在Microsoft的Visual C++(简称VC++)开发环境中,可以通过标准库中的文件操作函数来实现顺序读写功能。
### 文件顺序读写基础
顺序读写指的是从文件的开始处逐个读取或写入数据,直到文件结束。这与随机读写不同,后者可以任意位置读取或写入数据。顺序读写操作通常用于处理日志文件、文本文件等不需要频繁随机访问的文件。
### VC++中的文件流类
在VC++中,顺序读写操作主要使用的是C++标准库中的fstream类,包括ifstream(用于从文件中读取数据)和ofstream(用于向文件写入数据)两个类。这两个类都是从fstream类继承而来,提供了基本的文件操作功能。
### 实现文件顺序读写操作的步骤
1. **包含必要的头文件**:要进行文件操作,首先需要包含fstream头文件。
```cpp
#include <fstream>
```
2. **创建文件流对象**:创建ifstream或ofstream对象,用于打开文件。
```cpp
ifstream inFile("example.txt"); // 用于读操作
ofstream outFile("example.txt"); // 用于写操作
```
3. **打开文件**:使用文件流对象的成员函数open()来打开文件。如果不需要在创建对象时指定文件路径,也可以在对象创建后调用open()。
```cpp
inFile.open("example.txt", std::ios::in); // 以读模式打开
outFile.open("example.txt", std::ios::out); // 以写模式打开
```
4. **读写数据**:使用文件流对象的成员函数进行数据的读取或写入。对于读操作,可以使用 >> 运算符、get()、read()等方法;对于写操作,可以使用 << 运算符、write()等方法。
```cpp
// 读取操作示例
char c;
while (inFile >> c) {
// 处理读取的数据c
}
// 写入操作示例
const char *text = "Hello, World!";
outFile << text;
```
5. **关闭文件**:操作完成后,应关闭文件,释放资源。
```cpp
inFile.close();
outFile.close();
```
### 文件顺序读写的注意事项
- 在进行文件读写之前,需要确保文件确实存在,且程序有足够的权限对文件进行读写操作。
- 使用文件流进行读写时,应注意文件流的错误状态。例如,在读取完文件后,应检查文件流是否到达文件末尾(failbit)。
- 在写入文件时,如果目标文件不存在,某些open()操作会自动创建文件。如果文件已存在,open()操作则会清空原文件内容,除非使用了追加模式(std::ios::app)。
- 对于大文件的读写,应考虑内存使用情况,避免一次性读取过多数据导致内存溢出。
- 在程序结束前,应该关闭所有打开的文件流。虽然文件流对象的析构函数会自动关闭文件,但显式调用close()是一个好习惯。
### 常用的文件操作函数
- `open()`:打开文件。
- `close()`:关闭文件。
- `read()`:从文件读取数据到缓冲区。
- `write()`:向文件写入数据。
- `tellg()` 和 `tellp()`:分别返回当前读取位置和写入位置。
- `seekg()` 和 `seekp()`:设置文件流的位置。
### 总结
在VC++中实现顺序读写操作,是进行文件处理和数据持久化的基础。通过使用C++的标准库中的fstream类,我们可以方便地进行文件读写操作。掌握文件顺序读写不仅可以帮助我们在实际开发中处理数据文件,还可以加深我们对C++语言和文件I/O操作的理解。需要注意的是,在进行文件操作时,合理管理和异常处理是非常重要的,这有助于确保程序的健壮性和数据的安全。
【大数据时代必备:Hadoop框架深度解析】:掌握核心组件,开启数据科学之旅
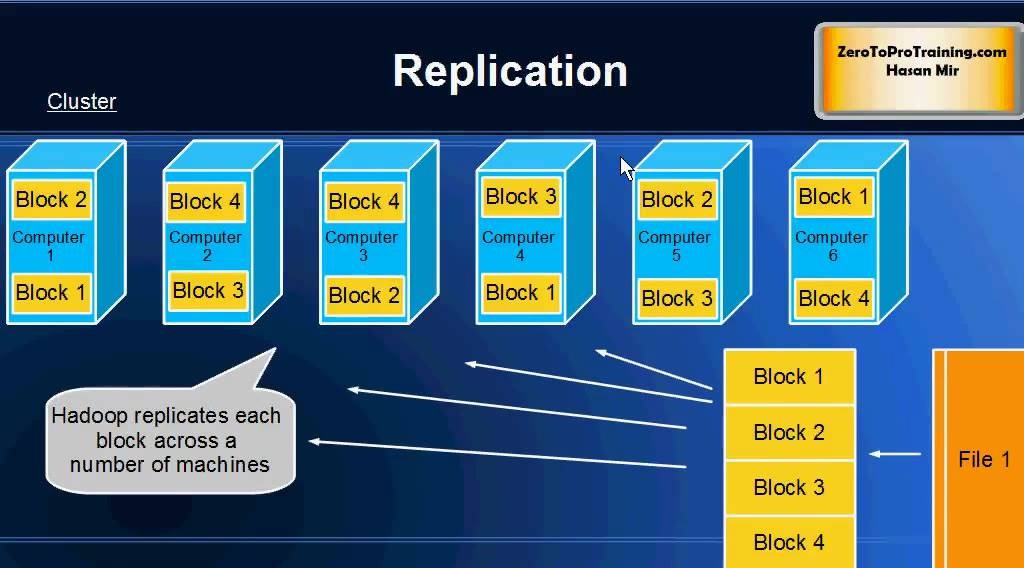
# 摘要
Hadoop作为一个开源的分布式存储和计算框架,在大数据处理领域发挥着举足轻重的作用。本文首先对Hadoop进行了概述,并介绍了其生态系统中的核心组件。深入分