spring cloud生产者无法连接数据库
时间: 2023-09-21 15:12:32 浏览: 88
您好!对于Spring Cloud生产者无法连接数据库的问题,有几个可能的原因和解决方法:
1. 数据库配置错误:请确保您在应用程序的配置文件(如application.properties或application.yml)中提供了正确的数据库连接配置,包括数据库的URL、用户名和密码。
2. 数据库驱动依赖缺失:请检查您的项目依赖中是否包含了正确的数据库驱动程序。例如,对于MySQL数据库,您需要添加MySQL驱动依赖,如'mysql-connector-java'。
3. 数据库服务不可用:请确保您正在连接的数据库服务处于运行状态。您可以尝试使用其他工具(如数据库客户端)连接到同一数据库以验证是否存在连接问题。
4. 服务发现配置错误:如果您在生产者中使用了服务发现(如Eureka或Consul),请确保服务注册和发现的配置正确,以便其他服务可以正确地找到和连接到生产者。
5. 防火墙或网络配置问题:请检查防火墙设置或网络配置,确保允许生产者应用程序与数据库进行通信。
如果您仍然无法解决问题,请提供更多详细信息,例如错误消息或代码片段,以便进一步帮助您解决问题。
相关问题
spring cloud alibaba项目生产者启动报错的原因
Spring Cloud Alibaba是一套基于Spring Cloud体系之上开发的微服务框架,其主要目的是为了解决微服务架构中的复杂性问题。对于生产环境中的Spring Cloud Alibaba项目启动报错,可能的原因有很多,以下是一些常见的原因和解决方案:
1. 网络原因:检查网络是否正常,是否能够访问相关服务和资源。
2. 环境配置问题:检查各个环境变量是否配置正确,是否符合要求。
3. 依赖冲突:检查项目中的依赖是否有冲突,特别是阿里巴巴的依赖。
4. 数据库连接问题:检查数据库配置是否正确,是否能够连接数据库。
5. 代码问题:检查代码是否符合规范,是否存在逻辑问题,是否有潜在的性能问题等。
6. 日志查看:查看应用程序的日志,以确定错误的具体原因。
在解决问题时,可以先尝试排除简单的问题,然后逐步深入到更复杂的问题。如果遇到无法解决的问题,可以搜索相关的资料或者寻求专业的帮助。
springcloud整合kafka实战
### 回答1:
springcloud与kafka结合可以实现微服务之间的消息传递,方便实现系统间的交互。主要步骤有:1. 配置springcloud和kafka;2. 使用@EnableBinding注解启用消息绑定;3. 使用@StreamListener注解实现消息的消费;4. 使用@SendTo注解实现消息的发送。
### 回答2:
Spring Cloud是一个用于构建分布式系统的开发工具包,它提供了一系列的解决方案和组件,包括服务注册与发现(Eureka)、负载均衡(Ribbon)、断路器(Hystrix)、网关(Zuul)等。而Kafka是一种高吞吐量的分布式消息队列系统,它可以实现消息的发布订阅模式。
在将Spring Cloud与Kafka进行整合时,我们可以利用Spring Cloud Stream框架来实现。Spring Cloud Stream是一个轻量级的微服务框架,它提供了统一的编程模型,简化了与消息中间件的集成。
首先,我们需要在pom.xml文件中添加Spring Cloud Stream和Kafka相关的依赖项。接下来,我们可以通过配置文件指定Kafka的地址和相关的参数,例如topic名称、分片数等。在Spring Cloud Stream中,将消息发布者称为生产者(producer),将消息订阅者称为消费者(consumer)。
在生产者方面,我们可以使用@EnableBinding注解将Spring Cloud Stream与Kafka进行绑定,并通过定义一个output通道来发送消息。在代码中,我们只需要调用output.send()方法即可将消息发送到Kafka中。
在消费者方面,我们同样使用@EnableBinding注解将Spring Cloud Stream与Kafka进行绑定,并通过定义一个input通道来接收消息。在代码中,我们可以使用@StreamListener注解来监听消息,并进行相应的处理逻辑,例如将消息存储到数据库中或者进行其他的业务操作。
通过以上步骤,我们就完成了Spring Cloud与Kafka的整合。在实际的项目中,可以将Kafka用作消息队列,实现服务之间的解耦和异步通信。通过Spring Cloud Stream的支持,我们可以更加方便地使用Kafka,并且将其作为整个分布式系统的消息中间件。这种架构具有高可扩展性和高可靠性,适用于大规模的分布式系统。
### 回答3:
Spring Cloud是一个基于Spring Framework的分布式系统开发框架,而Kafka是一个高吞吐量的分布式发布订阅消息系统。将二者整合起来可以实现可靠的消息传递和分布式的消息处理。
首先,我们需要在Spring Cloud项目中引入Kafka依赖。可以通过在pom.xml文件中添加相应的依赖来实现。然后,在配置文件中配置Kafka的相关参数,包括Kafka集群的地址和端口等信息。
接着,我们需要创建Kafka生产者和消费者。在Spring Cloud中,我们可以使用KafkaTemplate来发送消息,同时我们也可以通过注解@KafkaListener来订阅和处理消息。在生产者中,我们可以使用KafkaTemplate的send()方法来发送消息到Kafka集群。在消费者中,我们可以使用@KafkaListener注解来监听指定的主题,并通过编写对应的业务逻辑代码来处理接收到的消息。
此外,我们还可以使用Spring Cloud Stream来简化整合过程。Spring Cloud Stream是一种基于Spring Boot的用于构建消息驱动的微服务的框架。通过使用Spring Cloud Stream,我们可以进一步简化Kafka的消费者和生产者的创建和配置,只需要编写一些简单的配置文件就可以实现整合。
总的来说,Spring Cloud整合Kafka可以帮助我们实现高可靠性、高吞吐量的分布式消息传递和处理。我们可以通过配置和编写相应的代码来实现Kafka的生产者和消费者功能,同时也可以使用Spring Cloud Stream来简化整合过程。
相关推荐
最新推荐
spring cloud 体系版本选型,涉及spring cloud alibaba spring boot spring cloud
spring boot , spring cloud alibaba, spring cloub 版本选型
详解Spring连接数据库的几种常用的方式
本篇文章主要介绍了Spring连接数据库的几种常用的方式,具有一定的参考价值,有需要的可以了解一下。
spring cloud eureka(免费下载)
最新版本的springcloud微服务实战,老版本与新版本差异较大,按照老的文章去使用新版本会有很多bug。
30 道 Spring Cloud 面试题及答案.docx
什么是Spring Cloud 设计目标与优缺点 设计目标 优缺点 Spring Cloud发展前景 整体架构
详解spring cloud如何使用spring-test进行单元测试
主要介绍了spring cloud如何使用spring-test进行单元测试,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
工业AI视觉检测解决方案.pptx
工业AI视觉检测解决方案.pptx是一个关于人工智能在工业领域的具体应用,特别是针对视觉检测的深入探讨。该报告首先回顾了人工智能的发展历程,从起步阶段的人工智能任务失败,到专家系统的兴起到深度学习和大数据的推动,展示了人工智能从理论研究到实际应用的逐步成熟过程。
1. 市场背景:
- 人工智能经历了从计算智能(基于规则和符号推理)到感知智能(通过传感器收集数据)再到认知智能(理解复杂情境)的发展。《中国制造2025》政策强调了智能制造的重要性,指出新一代信息技术与制造技术的融合是关键,而机器视觉因其精度和效率的优势,在智能制造中扮演着核心角色。
- 随着中国老龄化问题加剧和劳动力成本上升,以及制造业转型升级的需求,机器视觉在汽车、食品饮料、医药等行业的渗透率有望提升。
2. 行业分布与应用:
- 国内市场中,电子行业是机器视觉的主要应用领域,而汽车、食品饮料等其他行业的渗透率仍有增长空间。海外市场则以汽车和电子行业为主。
- 然而,实际的工业制造环境中,由于产品种类繁多、生产线场景各异、生产周期不一,以及标准化和个性化需求的矛盾,工业AI视觉检测的落地面临挑战。缺乏统一的标准和模型定义,使得定制化的解决方案成为必要。
3. 工业化前提条件:
- 要实现工业AI视觉的广泛应用,必须克服标准缺失、场景多样性、设备技术不统一等问题。理想情况下,应有明确的需求定义、稳定的场景设置、统一的检测标准和安装方式,但现实中这些条件往往难以满足,需要通过技术创新来适应不断变化的需求。
4. 行业案例分析:
- 如金属制造业、汽车制造业、PCB制造业和消费电子等行业,每个行业的检测需求和设备技术选择都有所不同,因此,解决方案需要具备跨行业的灵活性,同时兼顾个性化需求。
总结来说,工业AI视觉检测解决方案.pptx着重于阐述了人工智能如何在工业制造中找到应用场景,面临的挑战,以及如何通过标准化和技术创新来推进其在实际生产中的落地。理解这个解决方案,企业可以更好地规划AI投入,优化生产流程,提升产品质量和效率。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL运维最佳实践:经验总结与建议
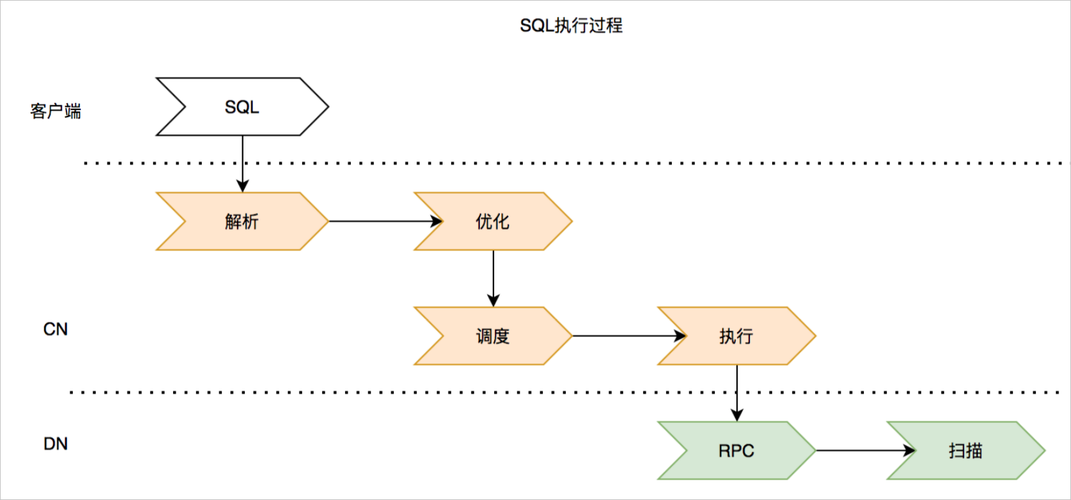
# 1. MySQL运维基础**
MySQL运维是一项复杂而重要的任务,需要深入了解数据库技术和最佳实践。本章将介绍MySQL运维的基础知识,包括:
- **MySQL架构和组件:**了解MySQL的架构和主要组件,包括服务器、客户端和存储引擎。
- **MySQL安装和配置:**涵盖MySQL的安装过
stata面板数据画图
Stata是一个统计分析软件,可以用来进行数据分析、数据可视化等工作。在Stata中,面板数据是一种特殊类型的数据,它包含了多个时间段和多个个体的数据。面板数据画图可以用来展示数据的趋势和变化,同时也可以用来比较不同个体之间的差异。
在Stata中,面板数据画图有很多种方法。以下是其中一些常见的方法
智慧医院信息化建设规划及愿景解决方案.pptx
"智慧医院信息化建设规划及愿景解决方案.pptx"
在当今信息化时代,智慧医院的建设已经成为提升医疗服务质量和效率的重要途径。本方案旨在探讨智慧医院信息化建设的背景、规划与愿景,以满足"健康中国2030"的战略目标。其中,"健康中国2030"规划纲要强调了人民健康的重要性,提出了一系列举措,如普及健康生活、优化健康服务、完善健康保障等,旨在打造以人民健康为中心的卫生与健康工作体系。
在建设背景方面,智慧医院的发展受到诸如分级诊疗制度、家庭医生签约服务、慢性病防治和远程医疗服务等政策的驱动。分级诊疗政策旨在优化医疗资源配置,提高基层医疗服务能力,通过家庭医生签约服务,确保每个家庭都能获得及时有效的医疗服务。同时,慢性病防治体系的建立和远程医疗服务的推广,有助于减少疾病发生,实现疾病的早诊早治。
在规划与愿景部分,智慧医院的信息化建设包括构建完善的电子健康档案系统、健康卡服务、远程医疗平台以及优化的分级诊疗流程。电子健康档案将记录每位居民的动态健康状况,便于医生进行个性化诊疗;健康卡则集成了各类医疗服务功能,方便患者就医;远程医疗技术可以跨越地域限制,使优质医疗资源下沉到基层;分级诊疗制度通过优化医疗结构,使得患者能在合适的层级医疗机构得到恰当的治疗。
在建设内容与预算方面,可能涉及硬件设施升级(如医疗设备智能化)、软件系统开发(如电子病历系统、预约挂号平台)、网络基础设施建设(如高速互联网接入)、数据安全与隐私保护措施、人员培训与技术支持等多个方面。预算应考虑项目周期、技术复杂性、维护成本等因素,以确保项目的可持续性和效益最大化。
此外,"互联网+医疗健康"的政策支持鼓励创新,智慧医院信息化建设还需要结合移动互联网、大数据、人工智能等先进技术,提升医疗服务的便捷性和精准度。例如,利用AI辅助诊断、物联网技术监控患者健康状态、区块链技术保障医疗数据的安全共享等。
智慧医院信息化建设是一项系统工程,需要政府、医疗机构、技术供应商和社会各方共同参与,以实现医疗服务质量的提升、医疗资源的优化配置,以及全民健康水平的提高。在2023年的背景下,这一进程将进一步加速,为我国的医疗健康事业带来深远影响。