failed result: hostbyte=did_error
时间: 2023-08-10 17:01:24 浏览: 172
"failed result: hostbyte=did_error" 是一个错误信息,通常在计算机网络通信中出现。这个错误信息意味着在与主机通信的过程中出现了错误。
具体而言,"hostbyte" 代表主机错误,而 "did_error" 表示发生了错误。这可能是由于以下几个原因导致的:
1. 连接问题:可能由于网络连接问题,无法与目标主机建立稳定的连接,导致数据传输失败。
2. 主机故障:目标主机可能遇到硬件或软件故障,无法正常处理请求或提供所需的服务。
3. 配置错误:可能由于配置错误或设置不正确,导致主机无法正确处理请求,从而出现错误。
4. 安全限制:目标主机可能受到安全限制,例如防火墙或访问控制列表,阻止了与主机的通信。
在解决这个问题的过程中,可以尝试以下步骤:
1. 检查网络连接:确保网络连接正常,尝试与其他主机进行通信,以确定是否存在网络问题。
2. 检查主机状态:确认目标主机是否正常运行,并检查主机上的系统日志或错误日志,以获取更多有关错误的详细信息。
3. 检查配置:核实与目标主机通信所使用的协议、端口号和其他配置是否正确。
4. 检查安全设置:如果存在安全限制,确保已正确配置防火墙或访问控制列表,以允许与目标主机的通信。
如果以上步骤都没有解决问题,可以尝试联系网络管理员或技术支持团队,他们可能能够提供更进一步的帮助和指导。
相关问题
linux messages中硬件故障内容案例
以下是Linux系统日志(/var/log/messages)中硬件故障内容的一个例子:
```
Sep 10 11:23:45 server kernel: [123456.789012] mpt3sas0: log_info(0x31120303): originator(PL), code(0x12), sub_code(0x0303)
Sep 10 11:23:45 server kernel: [123456.789012] mpt3sas0: log_info(0x31120303): originator(PL), code(0x12), sub_code(0x0303)
Sep 10 11:24:01 server kernel: [123472.789012] sd 0:0:0:0: [sda] FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Sep 10 11:24:01 server kernel: [123472.789012] sd 0:0:0:0: [sda] CDB: Read(10): 28 00 00 00 00 00 00 00 08 00
Sep 10 11:24:01 server kernel: [123472.789012] blk_update_request: I/O error, dev sda, sector 0
Sep 10 11:24:01 server kernel: [123472.789012] Buffer I/O error on dev sda, logical block 0, async page read
Sep 10 11:24:01 server kernel: [123472.789012] ata1: EH complete
Sep 10 11:24:01 server kernel: [123472.789012] sd 0:0:0:0: [sda] FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Sep 10 11:24:01 server kernel: [123472.789012] sd 0:0:0:0: [sda] CDB: Read(10): 28 00 00 00 00 00 00 00 08 00
Sep 10 11:24:01 server kernel: [123472.789012] blk_update_request: I/O error, dev sda, sector 0
Sep 10 11:24:01 server kernel: [123472.789012] Buffer I/O error on dev sda, logical block 0, async page read
Sep 10 11:24:01 server kernel: [123472.789012] ata1: EH complete
```
这段日志中包含了一个硬件故障的信息,指出了磁盘sda的读取操作失败,可能是硬件设备出现了故障。需要进一步检查和排除故障。
linux messages中硬盘故障内容案例
以下是Linux系统日志(/var/log/messages)中硬盘故障内容的一个例子:
```
Aug 12 10:41:42 server kernel: [123456.789012] ata1.00: exception Emask 0x0 SAct 0x1 SErr 0x0 action 0x0
Aug 12 10:41:42 server kernel: [123456.789012] ata1.00: irq_stat 0x40000008
Aug 12 10:41:42 server kernel: [123456.789012] ata1.00: failed command: READ FPDMA QUEUED
Aug 12 10:41:42 server kernel: [123456.789012] ata1.00: cmd 60/08:00:00:00:08/00:00:00:00:00/40 tag 0 ncq 4096 in
Aug 12 10:41:42 server kernel: [123456.789012] res 51/40:08:00:00:08/00:00:00:00:00/40 Emask 0x9 (media error)
Aug 12 10:41:42 server kernel: [123456.789012] ata1.00: status: { DRDY ERR }
Aug 12 10:41:42 server kernel: [123456.789012] ata1.00: error: { UNC }
Aug 12 10:41:42 server kernel: [123456.789012] ata1.00: configured for UDMA/133
Aug 12 10:41:42 server kernel: [123456.789012] sd 0:0:0:0: [sda] tag#0 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
Aug 12 10:41:42 server kernel: [123456.789012] sd 0:0:0:0: [sda] tag#0 Sense Key : Medium Error [current] [descriptor]
Aug 12 10:41:42 server kernel: [123456.789012] sd 0:0:0:0: [sda] tag#0 Add. Sense: Unrecovered read error - auto reallocate failed
Aug 12 10:41:42 server kernel: [123456.789012] sd 0:0:0:0: [sda] tag#0 CDB: Read(10) 28 00 00 00 08 00 00 00 08 00
Aug 12 10:41:42 server kernel: [123456.789012] blk_update_request: I/O error, dev sda, sector 2048 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0
Aug 12 10:41:42 server kernel: [123456.789012] Buffer I/O error on dev sda, logical block 256, async page read
Aug 12 10:41:42 server kernel: [123456.789012] ata1: EH complete
```
这段日志中也包含了一个硬盘故障的信息,指出了磁盘sda的读取操作失败,错误类型为"Medium Error",并且自动重分配失败。这种错误通常意味着硬盘表面存在坏道,需要及时更换硬盘以避免数据丢失。
相关推荐
最新推荐
JSP学生学籍管理系统设计与实现(源代码+论文+开题报告+外文翻译+答辩PPT).zip
1、资源项目源码均已通过严格测试验证,保证能够正常运行;
2、项目问题、技术讨论,可以给博主私信或留言,博主看到后会第一时间与您进行沟通;
3、本项目比较适合计算机领域相关的毕业设计课题、课程作业等使用,尤其对于人工智能、计算机科学与技术等相关专业,更为适合;
4、下载使用后,可先查看README.md或论文文件(如有),本项目仅用作交流学习参考,请切勿用于商业用途。
5、资源来自互联网采集,如有侵权,私聊博主删除。
6、可私信博主看论文后选择购买源代码。
1、资源项目源码均已通过严格测试验证,保证能够正常运行;
2、项目问题、技术讨论,可以给博主私信或留言,博主看到后会第一时间与您进行沟通;
3、本项目比较适合计算机领域相关的毕业设计课题、课程作业等使用,尤其对于人工智能、计算机科学与技术等相关专业,更为适合;
4、下载使用后,可先查看README.md或论文文件(如有),本项目仅用作交流学习参考,请切勿用于商业用途。
5、资源来自互联网采集,如有侵权,私聊博主删除。
6、可私信博主看论文后选择购买源代码。
1、资源项目源码均已通过严格测试验证,保证能够正常运行;
2、项目问题、技术讨论,可以给博主私信或留言,博主看到后会第一时间与您进行沟通;
3、本项目比较适合计算机领域相关的毕业设计课题、课程作业等使用,尤其对于人工智能、计算机科学与技术等相关专业,更为适合;
4、下载使用后,可先查看README.md或论文文件(如有),本项目仅用作交流学习参考,请切勿用于商业用途。
5、资源来自互联网采集,如有侵权,私聊博主删除。
6、可私信博主看论文后选择购买源代码。
省市区数据,完成三级联动,选择地区
省市区数据,完成三级联动,选择地区
机械原理课程设计网球自动捡球机.doc
机械原理课程设计网球自动捡球机.doc
2024秋招华为笔试题大全-仅供参考具体需要根据实际修改
2024秋招华为笔试题大全-仅供参考具体需要根据实际修改
借助于Ascend310 AI处理器完成深度学习算法部署任务,
应用背景为变电站电力巡检,基于YOLO v4算法模型对常见电力巡检目标进行检测,并充分利用Ascend310提供的DVPP等硬件支持能力来完成流媒体的传输、处理等任务,并对系统性能做出一定的优化。.zip深度学习是机器学习的一个子领域,它基于人工神经网络的研究,特别是利用多层次的神经网络来进行学习和模式识别。深度学习模型能够学习数据的高层次特征,这些特征对于图像和语音识别、自然语言处理、医学图像分析等应用至关重要。以下是深度学习的一些关键概念和组成部分:
1. **神经网络(Neural Networks)**:深度学习的基础是人工神经网络,它是由多个层组成的网络结构,包括输入层、隐藏层和输出层。每个层由多个神经元组成,神经元之间通过权重连接。
2. **前馈神经网络(Feedforward Neural Networks)**:这是最常见的神经网络类型,信息从输入层流向隐藏层,最终到达输出层。
3. **卷积神经网络(Convolutional Neural Networks, CNNs)**:这种网络特别适合处理具有网格结构的数据,如图像。它们使用卷积层来提取图像的特征。
4. **循环神经网络(Recurrent Neural Networks, RNNs)**:这种网络能够处理序列数据,如时间序列或自然语言,因为它们具有记忆功能,能够捕捉数据中的时间依赖性。
5. **长短期记忆网络(Long Short-Term Memory, LSTM)**:LSTM 是一种特殊的 RNN,它能够学习长期依赖关系,非常适合复杂的序列预测任务。
6. **生成对抗网络(Generative Adversarial Networks, GANs)**:由两个网络组成,一个生成器和一个判别器,它们相互竞争,生成器生成数据,判别器评估数据的真实性。
7. **深度学习框架**:如 TensorFlow、Keras、PyTorch 等,这些框架提供了构建、训练和部署深度学习模型的工具和库。
8. **激活函数(Activation Functions)**:如 ReLU、Sigmoid、Tanh 等,它们在神经网络中用于添加非线性,使得网络能够学习复杂的函数。
9. **损失函数(Loss Functions)**:用于评估模型的预测与真实值之间的差异,常见的损失函数包括均方误差(MSE)、交叉熵(Cross-Entropy)等。
10. **优化算法(Optimization Algorithms)**:如梯度下降(Gradient Descent)、随机梯度下降(SGD)、Adam 等,用于更新网络权重,以最小化损失函数。
11. **正则化(Regularization)**:技术如 Dropout、L1/L2 正则化等,用于防止模型过拟合。
12. **迁移学习(Transfer Learning)**:利用在一个任务上训练好的模型来提高另一个相关任务的性能。
深度学习在许多领域都取得了显著的成就,但它也面临着一些挑战,如对大量数据的依赖、模型的解释性差、计算资源消耗大等。研究人员正在不断探索新的方法来解决这些问题。
ExtJS 2.0 入门教程与开发指南
"EXTJS开发指南,适用于初学者,涵盖Ext组件和核心技术,可用于.Net、Java、PHP等后端开发的前端Ajax框架。教程包括入门、组件结构、控件使用等,基于ExtJS2.0。提供有配套的单用户Blog系统源码以供实践学习。作者还编写了更详细的《ExtJS实用开发指南》,包含控件配置、服务器集成等,面向进阶学习者。"
EXTJS是一个强大的JavaScript库,专门用于构建富客户端的Web应用程序。它以其丰富的组件和直观的API而闻名,能够创建具有桌面应用般用户体验的Web界面。在本文档中,我们将深入探讨EXTJS的核心技术和组件,帮助初学者快速上手。
首先,EXTJS的组件模型是其强大功能的基础。它包括各种各样的控件,如窗口(Window)、面板(Panel)、表格(Grid)、表单(Form)、菜单(Menu)等,这些组件可以灵活组合,构建出复杂的用户界面。通过理解这些组件的属性、方法和事件,开发者可以定制化界面以满足特定需求。
入门EXTJS,你需要了解基本的HTML和JavaScript知识。EXTJS的API文档是学习的重要资源,它详细解释了每个组件的功能和用法。此外,通过实际操作和编写代码,你会更快地掌握EXTJS的精髓。本教程中,作者提供了新手入门指导,包括如何设置开发环境,创建第一个EXTJS应用等。
EXTJS的组件体系结构是基于MVC(Model-View-Controller)模式的,这使得代码组织清晰,易于维护。学习如何构建和组织这些组件,对于理解EXTJS的工作原理至关重要。同时,EXTJS提供了数据绑定机制,可以方便地将视图组件与数据源连接,实现数据的实时更新。
在EXTJS中,控件的使用是关键。例如,表格控件(GridPanel)可以显示大量数据,支持排序、过滤和分页;表单控件(FormPanel)用于用户输入,可以验证数据并发送到服务器。每个控件都有详细的配置选项,通过调整这些选项,可以实现各种自定义效果。
此外,EXTJS与服务器端的集成是另一个重要话题。无论你的后端是.NET、Java还是PHP,EXTJS都能通过Ajax通信进行数据交换。了解如何使用Store和Proxy来处理数据请求和响应,是构建交互式应用的关键。
为了深化EXTJS的学习,你可以参考作者编写的《ExtJS实用开发指南》。这本书更深入地讲解了EXTJS框架,包括控件的详细配置、服务器集成示例以及一个完整应用系统的构建过程,适合已经掌握了EXTJS基础并希望进一步提升技能的开发者。
EXTJS是一个强大的工具,能够帮助开发者构建功能丰富、用户体验优秀的Web应用。通过本文档提供的教程和配套资源,初学者可以逐步掌握EXTJS,从而踏入这个充满可能的世界。在实践中不断学习和探索,你将能驾驭EXTJS,创造出自己的富客户端应用。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
【Java字符串不可变性深度剖析】:影响与应用场景分析
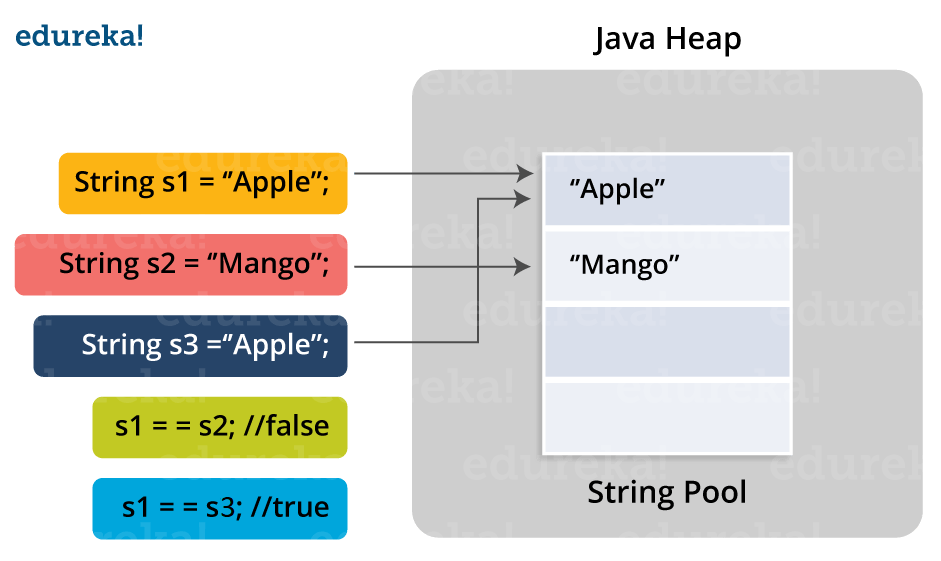
# 1. Java字符串不可变性的基本概念
Java字符串的不可变性指的是一个字符串对象一旦被创建,其内部的字符序列就不能被改变。这意味着任何对字符串的修改操作,如更改字符、拼接、截取等,都不会影响原始字符串对象,而是会生成一个新的字符串对象。不可变性是Java中String类的一个核心特性,它为Java语言带来了多方面的积极影响,比如线程安全、高效的字符串池管理等。然而,这一特性也并
如何让一个字符串等于一个字符数组
要让一个字符串等于一个字符数组,你可以直接赋值,假设我们有一个字符数组`char strArray[]`和一个字符串`char* myString`,你可以这样做:
```c
// 字符数组初始化
char strArray[] = "Hello, World!";
// 将字符串字面量赋给myString
char* myString = strArray;
// 或者如果你想要创建动态分配的字符串并且需要手动添加终止符'\0',
// 可以使用strcpy()函数
size_t len = strlen(strArray); // 获取字符串长度
myString = (char*)
基于TMS320F2812的能量回馈调速系统设计
"基于TMS320F2812的能量回馈调速系统的研发,涉及硬件电路设计、软件设计及Matlab仿真,是理解能量回馈技术的重要资料。"
本文详细探讨了基于TI公司的TMS320F2812 DSP芯片实现的能量回馈调速系统。TMS320F2812是一款高性能的数字信号处理器,适用于实时控制应用,其内置的双事件管理器功能使得双PWM控制得以高效实现,降低了硬件成本并支持复杂控制算法。
在能量回馈的基本原理上,传统的能耗制动方法在变频调速中存在能源浪费、电阻过热以及无法在四象限运行等问题。能量回馈技术则解决了这些问题,它允许变频器在所有四个象限运行,并通过控制整流器和逆变器之间的功率平衡,减小直流储能电容的需求。此外,制动能量被送回电网,提高了系统的整体效率,同时不会对电网质量造成负面影响。
文章首先介绍了能量回馈调速系统的硬件电路设计。主电路采用了两电平电压型双PWM变换器架构,包含网侧电抗器、PWM整流器、直流环节和PWM逆变器。PWM整流器在电机减速时将电机产生的机械能转化为电能,并通过逆变器将其反馈到电网。直流母线电压检测、电流检测、同步电路和温度检测电路等辅助电路确保了系统稳定运行和安全。
接下来,文章阐述了系统的控制策略和软件设计。通过DSP芯片,可以执行实时的控制算法,实现精确的电压和电流控制,确保能量有效回馈。软件设计包括了对电机状态的监控、PWM信号的生成以及各种保护机制的编程。
最后,作者进行了Matlab仿真实验,通过仿真波形验证了设计的有效性。实验结果表明,基于TMS320F2812的系统能够实现能量回馈,且动态性能良好。尽管国际上已有类似的四象限运行变频器和再生装置,但考虑到价格和电网适应性,本设计提供了更经济、更适合中国国情的解决方案。
这篇文章为读者提供了一个深入理解能量回馈技术以及如何利用TMS320F2812 DSP实现这一技术的实例,对于从事相关领域的工程师和技术人员来说,是一份有价值的参考资料。