package anaylse import org.apache.spark.sql.SparkSession object BasicAnaylse { val spark=SparkSession.builder().appName("BasicAnalyse") .master("local[*]") 注释其中重要部分的意思 .enableHiveSupport() .getOrCreate() // spark.sparkContext.setLogLevel("WARN") def main(args: Array[String]): Unit = { //探索每个表中的重复记录表和空值记录数 val tableName = Array("media_index","mediamatch_userevent","mediamatch_usermsg","mmconsume_billevents","order_index") var i = ""; for(i<-tableName){ Analyse(i) } // val mediamatch_userevent = spark.table("user_project.mediamatch_userevent") // mediamatch_userevent.show(false) } def Analyse(tableName:String): Unit ={ val data = spark.table("user_project."+tableName) print(tableName+"表数据:"+data.count()) print(tableName+"表phone_no字段为空数:"+(data.count()-data.select("phone_no").na.drop().count)) } }
时间: 2024-04-28 08:26:12 浏览: 161
这段代码是一个基本的数据分析程序,使用 Apache Spark SQL 的 SparkSession 类来创建一个 Spark 应用程序。它的主要作用是对指定的表进行分析,包括查找重复记录表和空值记录数。其中重要的部分是:
- `appName("BasicAnalyse")`:设置应用程序的名称为 "BasicAnalyse"。
- `master("local[*]")`:设置应用程序在本地运行,使用所有可用的 CPU 核心。
- `enableHiveSupport()`:启用 Hive 支持,可以在 Spark SQL 中访问 Hive 表。
- `getOrCreate()`:获取或创建 SparkSession 实例。
- `spark.table("user_project."+tableName)`:通过 SparkSession 实例获取指定表的 DataFrame。
在 `main` 函数中,使用一个循环语句遍历指定的表,并调用 `Analyse` 函数对每个表进行分析。在 `Analyse` 函数中,使用 `count()` 函数获取表的总记录数,使用 `na.drop()` 函数删除空值记录,计算出表中 `phone_no` 字段的空值记录数。
相关问题
分析代码package analyse import org.apache.spark.sql.SparkSession object BasicAnaylse { val spark=SparkSession.builder() .appName("BasicAnalyse") .master("local[*]") .enableHiveSupport() .getOrCreate() spark.sparkContext.setLogLevel("WARN") def main(args: Array[String]): Unit = { val tableName = Array("media_index","mediamatch_userevent","mediamatch_usermsg","mmconsume_billevents","order_index") var i = ""; for ( i<-tableName){ Analyse(i) } } def Analyse(tableName:String):Unit={ val data = spark.table(tableName = "user_project."+tableName) println(tableName+"表数据:"+data.count()) println(tableName+"表字段为空数:"+(data.count()-data.select("phone_no").na.drop().count)) } }
根据你提供的代码,我们可以看出该代码的功能是对指定的5个表进行数据分析,输出表数据的总量和字段为空的数量。具体分析如下:
1. 导入了SparkSession类,用于连接Spark集群。
2. 创建了一个BasicAnalyse对象,并定义了SparkSession对象spark,用于连接Spark集群和设置日志级别为WARN。
3. 在main函数中,定义了一个包含5个表名的数组tableName,并使用for循环遍历该数组,依次调用Analyse函数进行分析。
4. Analyse函数中,首先通过SparkSession对象spark的table方法获取指定表名的数据。
5. 然后使用count方法计算数据总量,并使用na.drop().count方法计算字段为空的数量。
6. 最后输出表数据的总量和字段为空的数量。
需要注意的是,该代码使用了Spark SQL来操作数据,因此需要确保Spark集群已经启动并且可以访问到指定的表。同时,该代码中使用了变量i来遍历表名数组tableName,可以使用更加直观的方式来定义变量名。例如,可以使用tableName.foreach(tableName => Analyse(tableName))来遍历表名数组并调用Analyse函数进行分析。
解释下列代码package sparkML import org.apache.spark.ml.clustering.{KMeans, KMeansModel} import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer} import org.apache.spark.sql.{DataFrame, SparkSession} object Kmeans { case class Product(id: String, wd: String, jd: String, sjc: String, jyje: String) def main(args: Array[String]): Unit = { val spark = SparkSession .builder() .appName("TFIDF@2") .master("local[3]") .getOrCreate() import spark.implicits._ val product = spark.sparkContext.textFile("data/data.txt").map { x => val data = x.split(",") Product(data(0), data(1), data(2), data(3), data(4)) }.toDS().cache() product.createOrReplaceTempView("data") val products: DataFrame = spark.sql("select id, concat_ws(',',collect_set(jyje)) as jyje from data group by id") val productData = new Tokenizer().setInputCol("jyje").setOutputCol("productWords").transform(products) val tfData = new HashingTF().setNumFeatures(20).setInputCol("productWords").setOutputCol("productFeatures").transform(productData) val idfModel = new IDF().setInputCol("productFeatures").setOutputCol("features").fit(tfData) val idfData = idfModel.transform(tfData) val trainingData = idfData.select("id", "features") val kmeans = new KMeans() .setK(4) .setMaxIter(5) .setFeaturesCol("features") .setPredictionCol("prediction") val kmeansModel = kmeans.fit(trainingData) val kmeansData = kmeansModel.transform(trainingData) kmeansData.show() } }
这段代码是一个使用Spark ML库实现KMeans聚类算法的示例。代码中定义了一个名为Product的case class,表示一个产品的属性集合。代码中首先使用SparkContext的textFile方法读取数据文件,然后使用map方法将每行数据转换为Product对象,并转换成DataFrame格式。接着,使用Spark SQL对DataFrame进行分组和聚合操作,得到每个产品的交易金额数据。然后,使用Tokenizer和HashingTF对文本进行分词和特征提取,使用IDF对特征进行加权,得到最终的训练数据。最后,使用KMeans算法对训练数据进行聚类,并输出聚类结果。
阅读全文
相关推荐
最新推荐
解决keras,val_categorical_accuracy:,0.0000e+00问题
然而,在实践中,我们可能会遇到一些问题,例如在训练过程中遇到`val_categorical_accuracy: 0.0000e+00`的情况。这通常意味着模型在验证集上的分类精度为零,即模型无法正确预测任何验证样本的类别。 问题描述: ...
Python Numpy:找到list中的np.nan值方法
import numpy as np x = np.array([2, 3, np.nan, 5, np.nan, 5, 2, 3]) # 简单查找np.nan值 for item in x: if np.isnan(item): print('yes') ``` 在这个例子中,`np.isnan(item)`函数被用来遍历数组`x`的每个...
OpenCV cv.Mat与.txt文件数据的读写操作
while (iss >> val) { data.push_back(val); } } // 保存到矩阵 matData = cv::Mat(matRows, matCols, CV_8UC1, data.data()); return (retVal); } ``` 这两个函数可以实现.txt文件的读写操作,其中WriteData...
Vue.js仿Select下拉框效果
`imitate-select` 组件的数据属性包括 `selectShoe`(控制下拉框是否显示)和 `val`(当前选中的值)。同时,它接收两个props:`h2Value`(标题文本)和 `list`(下拉选项列表)。模板中,`<input>` 用于输入和展示...
混合场景下大规模 GPU 集群构建与实践.pdf
混合场景下大规模 GPU 集群构建与实践.pdf
平尾装配工作平台运输支撑系统设计与应用
资源摘要信息:"该压缩包文件名为‘行业分类-设备装置-用于平尾装配工作平台的运输支撑系统.zip’,虽然没有提供具体的标签信息,但通过文件标题可以推断出其内容涉及的是航空或者相关重工业领域内的设备装置。从标题来看,该文件集中讲述的是有关平尾装配工作平台的运输支撑系统,这是一种专门用于支撑和运输飞机平尾装配的特殊设备。
平尾,即水平尾翼,是飞机尾部的一个关键部件,它对于飞机的稳定性和控制性起到至关重要的作用。平尾的装配工作通常需要在一个特定的平台上进行,这个平台不仅要保证装配过程中平尾的稳定,还需要适应平尾的搬运和运输。因此,设计出一个合适的运输支撑系统对于提高装配效率和保障装配质量至关重要。
从‘用于平尾装配工作平台的运输支撑系统.pdf’这一文件名称可以推断,该PDF文档应该是详细介绍这种支撑系统的构造、工作原理、使用方法以及其在平尾装配工作中的应用。文档可能包括以下内容:
1. 支撑系统的设计理念:介绍支撑系统设计的基本出发点,如便于操作、稳定性高、强度大、适应性强等。可能涉及的工程学原理、材料学选择和整体结构布局等内容。
2. 结构组件介绍:详细介绍支撑系统的各个组成部分,包括支撑框架、稳定装置、传动机构、导向装置、固定装置等。对于每一个部件的功能、材料构成、制造工艺、耐腐蚀性以及与其他部件的连接方式等都会有详细的描述。
3. 工作原理和操作流程:解释运输支撑系统是如何在装配过程中起到支撑作用的,包括如何调整支撑点以适应不同重量和尺寸的平尾,以及如何进行运输和对接。操作流程部分可能会包含操作步骤、安全措施、维护保养等。
4. 应用案例分析:可能包含实际操作中遇到的问题和解决方案,或是对不同机型平尾装配过程的支撑系统应用案例的详细描述,以此展示系统的实用性和适应性。
5. 技术参数和性能指标:列出支撑系统的具体技术参数,如载重能力、尺寸规格、工作范围、可调节范围、耐用性和可靠性指标等,以供参考和评估。
6. 安全和维护指南:对于支撑系统的使用安全提供指导,包括操作安全、应急处理、日常维护、定期检查和故障排除等内容。
该支撑系统作为专门针对平尾装配而设计的设备,对于飞机制造企业来说,掌握其详细信息是提高生产效率和保障产品质量的重要一环。同时,这种支撑系统的设计和应用也体现了现代工业在专用设备制造方面追求高效、安全和精确的趋势。"
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MATLAB遗传算法探索:寻找随机性与确定性的平衡艺术
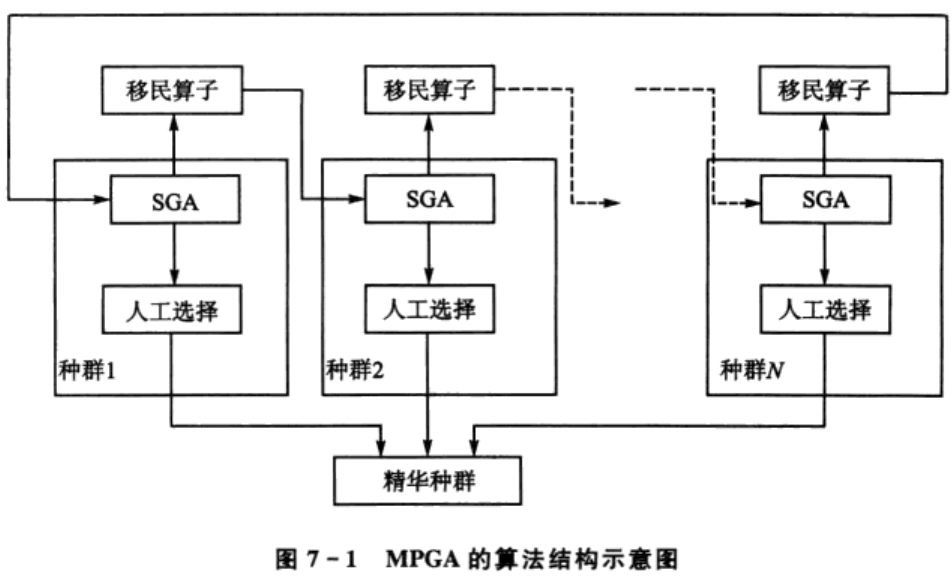
# 1. 遗传算法的基本概念与起源
遗传算法(Genetic Algorithm, GA)是一种模拟自然选择和遗传学机制的搜索优化算法。起源于20世纪60年代末至70年代初,由John Holland及其学生和同事们在研究自适应系统时首次提出,其理论基础受到生物进化论的启发。遗传算法通过编码一个潜在解决方案的“基因”,构造初始种群,并通过选择、交叉(杂交)和变异等操作模拟生物进化过程,以迭代的方式不断优化和筛选出最适应环境的
如何在S7-200 SMART PLC中使用MB_Client指令实现Modbus TCP通信?请详细解释从连接建立到数据交换的完整步骤。
为了有效地掌握S7-200 SMART PLC中的MB_Client指令,以便实现Modbus TCP通信,建议参考《S7-200 SMART Modbus TCP教程:MB_Client指令与功能码详解》。本教程将引导您了解从连接建立到数据交换的整个过程,并详细解释每个步骤中的关键点。
参考资源链接:[S7-200 SMART Modbus TCP教程:MB_Client指令与功能码详解](https://wenku.csdn.net/doc/119yes2jcm?spm=1055.2569.3001.10343)
首先,确保您的S7-200 SMART CPU支持开放式用户通
MAX-MIN Ant System:用MATLAB解决旅行商问题
资源摘要信息:"Solve TSP by MMAS: Using MAX-MIN Ant System to solve Traveling Salesman Problem - matlab开发"
本资源为解决经典的旅行商问题(Traveling Salesman Problem, TSP)提供了一种基于蚁群算法(Ant Colony Optimization, ACO)的MAX-MIN蚁群系统(MAX-MIN Ant System, MMAS)的Matlab实现。旅行商问题是一个典型的优化问题,要求找到一条最短的路径,让旅行商访问每一个城市一次并返回起点。这个问题属于NP-hard问题,随着城市数量的增加,寻找最优解的难度急剧增加。
MAX-MIN Ant System是一种改进的蚁群优化算法,它在基本的蚁群算法的基础上,对信息素的更新规则进行了改进,以期避免过早收敛和局部最优的问题。MMAS算法通过限制信息素的上下界来确保算法的探索能力和避免过早收敛,它在某些情况下比经典的蚁群系统(Ant System, AS)和带有局部搜索的蚁群系统(Ant Colony System, ACS)更为有效。
在本Matlab实现中,用户可以通过调用ACO函数并传入一个TSP问题文件(例如"filename.tsp")来运行MMAS算法。该问题文件可以是任意的对称或非对称TSP实例,用户可以从特定的网站下载多种标准TSP问题实例,以供测试和研究使用。
使用此资源的用户需要注意,虽然该Matlab代码可以免费用于个人学习和研究目的,但若要用于商业用途,则需要联系作者获取相应的许可。作者的电子邮件地址为***。
此外,压缩包文件名为"MAX-MIN%20Ant%20System.zip",该压缩包包含Matlab代码文件和可能的示例数据文件。用户在使用之前需要将压缩包解压,并将文件放置在Matlab的适当工作目录中。
为了更好地理解和应用该资源,用户应当对蚁群优化算法有初步了解,尤其是对MAX-MIN蚁群系统的基本原理和运行机制有所掌握。此外,熟悉Matlab编程环境和拥有一定的编程经验将有助于用户根据个人需求修改和扩展算法。
在实际应用中,用户可以根据问题规模调整MMAS算法的参数,如蚂蚁数量、信息素蒸发率、信息素增量等,以获得最优的求解效果。此外,也可以结合其他启发式或元启发式算法,如遗传算法、模拟退火等,来进一步提高算法的性能。
总之,本资源为TSP问题的求解提供了一种有效的算法框架,且Matlab作为编程工具的易用性和强大的计算能力,使得该资源成为算法研究人员和工程技术人员的有力工具。通过本资源的应用,用户将能够深入探索并实现蚁群优化算法在实际问题中的应用,为解决复杂的优化问题提供一种新的思路和方法。