核极限学习机pytorch
时间: 2023-10-21 16:28:58 浏览: 45
核极限学习机(PyTorch)是一种基于深度学习的非线性回归和分类模型。它是由Hung Son Nguyen等人在2019年提出的。核极限学习机通过将输入数据映射到高维特征空间,并利用核技巧来实现非线性变换。PyTorch是一个流行的深度学习框架,提供了丰富的工具和函数,用于构建和训练神经网络模型。
要在PyTorch中实现核极限学习机,首先需要定义模型架构。可以使用PyTorch的`nn.Module`类来创建自定义模型。模型的输入层将数据映射到高维特征空间,然后通过隐藏层处理这些特征,最后通过输出层进行预测或分类。
为了实现非线性变换,可以使用PyTorch中提供的各种核函数,如径向基函数(Radial Basis Function, RBF)或多项式核函数。这些核函数可以在输入和隐藏层之间的映射中使用,以提高模型的表达能力。
在训练过程中,可以使用PyTorch的优化器和损失函数来最小化模型的误差。常见的优化器包括随机梯度下降(SGD)和Adam优化器。对于回归任务,可以使用均方误差损失函数,对于分类任务,可以使用交叉熵损失函数。
总结来说,使用PyTorch实现核极限学习机需要定义模型架构,选择合适的核函数,并使用优化器和损失函数进行训练。这样可以构建一个强大的非线性回归或分类模型。
相关问题
pytorch实现elm极限学习机
### 回答1:
ELM(Extreme Learning Machine)是一种快速且高效的机器学习算法。它的特点是在训练阶段只需要随机初始化隐藏层的权重和偏置,然后直接求解输出层的权重,因此训练过程非常快速,适用于处理大规模数据。PyTorch是一种基于Python的机器学习库,提供了丰富的工具和接口,可以方便地实现ELM算法。
在PyTorch中实现ELM极限学习机的步骤如下:
1. 准备数据集:首先加载需要训练和测试的数据集,并进行预处理,如归一化处理。
2. 定义隐藏层:使用PyTorch定义隐藏层的层数、节点数以及激活函数等超参数。
3. 初始化隐藏层权重和偏置:使用PyTorch的randn函数生成随机初始权重和偏置。
4. 计算隐藏层输出:根据输入数据和隐藏层权重、偏置计算隐藏层的输出。
5. 计算输出层权重:根据隐藏层的输出和对应的标签,使用公式直接求解输出层的权重。
6. 预测和评估:使用得到的隐藏层和输出层的权重进行预测,并进行评估。
7. 可选的模型保存:可以将训练好的模型保存以备后续使用。
在以上步骤中,我们可以借助PyTorch提供的张量操作、优化器和损失函数等功能来简化计算过程和优化模型。通过PyTorch实现ELM极限学习机,我们能够高效地处理大规模数据,并得到准确的预测结果。
### 回答2:
PyTorch是一个基于Python的开源机器学习库,可用于构建深度学习模型。极限学习机(ELM)是一种神经网络模型,它是由日本学者森田亮提出的一种单层前馈神经网络。ELM具有神经网络的训练速度快、可解释性好的优点。
要使用PyTorch实现ELM,首先需要导入PyTorch库,并安装相关依赖。然后,根据ELM的原理,构建ELM模型。ELM模型由输入层、隐藏层和输出层组成。输入层接收数据输入,隐藏层使用随机权重进行线性组合,然后通过非线性激活函数进行处理,最后输出层将结果输出。
具体实现步骤如下:
1. 导入PyTorch库和其他所需的依赖项。
2. 定义ELM模型的类,并初始化输入层、隐藏层和输出层的节点数。
3. 初始化随机权重和偏差矩阵。隐藏层的权重矩阵大小为隐藏节点数乘以输入节点数,输出层的权重矩阵大小为输出节点数乘以隐藏节点数。
4. 定义非线性激活函数(例如 sigmoid、ReLU等)。
5. 使用PyTorch的Tensor对象将输入数据转换为正确的格式。
6. 将输入数据传递给隐藏层,并通过非线性激活函数进行处理。
7. 将隐藏层的输出结果与输出层的权重矩阵相乘,并应用非线性激活函数。
8. 使用PyTorch的优化器和损失函数对ELM模型进行训练。
9. 使用训练好的模型对新数据进行预测。
以上是用PyTorch实现ELM极限学习机的大致步骤。具体实现还需要根据任务类型和数据集的特点进行调整和完善。通过使用PyTorch的高级特性和强大的计算能力,可以方便地实现ELM模型,并获得准确的预测结果。
### 回答3:
PyTorch是一个开源的机器学习框架,可以方便地实现各种机器学习算法,包括极限学习机(ELM)。
极限学习机是一种单隐层前馈神经网络,它的隐层权重和偏置可以通过随机初始化得到。使用ELM进行训练时,我们先将输入数据通过随机生成的隐层权重和偏置进行非线性变换,然后将变换后的结果作为输入数据训练输出层的权重。相比传统的神经网络算法,ELM的训练过程更加高效,因为隐层权重和偏置不需要通过反向传播进行优化。
在PyTorch中实现ELM,首先需要定义一个ELM类。该类包含两个主要的方法:一个用于初始化ELM模型的权重和偏置,一个用于训练ELM模型。
在初始化方法中,我们可以使用PyTorch提供的random模块随机生成隐层权重和偏置,并将其保存为ELM模型的属性。
在训练方法中,我们可以通过调用PyTorch提供的Tensor对象的函数进行各种数学运算。首先,我们将输入数据转换为PyTorch的Tensor对象。然后,我们将隐层权重和偏置与输入数据进行矩阵运算,得到隐层输出。接下来,我们可以使用隐层输出和对应的目标输出训练输出层的权重。最后,我们可以通过计算预测输出和目标输出的损失来评估ELM模型的性能,并根据损失进行模型优化。
具体的代码实现请参考PyTorch的官方文档和教程,以及相关的开源项目和论文。在实现ELM算法时,需要注意输入数据的预处理、模型的参数设置和训练的策略等方面的注意事项。在实践中,可以结合其他的机器学习技术和工具,如数据集加载、数据增强、模型评估和模型解释等,来提高ELM模型的性能和可解释性。
支持向量机 pytorch
支持向量机(Support Vector Machine,简称SVM)是一种常用的机器学习算法,用于分类和回归任务。它的目标是找到一个最优的超平面,将不同类别的样本分开。PyTorch是一个流行的深度学习框架,它提供了丰富的工具和函数来实现各种机器学习算法,包括支持向量机。
在PyTorch中,可以使用torchsvm库来实现支持向量机算法。该库提供了一系列函数和类,用于训练和使用支持向量机模型。你可以使用torchsvm库加载数据集,定义模型,选择合适的核函数,并使用训练数据进行模型训练。训练完成后,你可以使用模型对新的样本进行分类。
需要注意的是,PyTorch主要用于深度学习任务,而支持向量机是一种传统的机器学习算法。虽然可以使用PyTorch实现支持向量机,但在处理大规模数据集时,传统的支持向量机库(如libsvm和scikit-learn)可能更加高效和方便。
总结起来,支持向量机是一种常用的机器学习算法,PyTorch是一个流行的深度学习框架,可以使用torchsvm库来实现支持向量机算法。但在实际应用中,可以根据具体情况选择合适的工具和库来实现支持向量机算法。
#### 引用[.reference_title]
- *1* *2* *3* [半监督支持向量机](https://blog.csdn.net/m0_46602930/article/details/129644335)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v91^control_2,239^v3^insert_chatgpt"}} ] [.reference_item]
[ .reference_list ]
相关推荐
最新推荐
pytorch学习教程之自定义数据集
在训练深度学习模型之前,样本集的制作非常重要。在pytorch中,提供了一些接口和类,方便我们定义自己的数据集合,下面完整的试验自定义样本集的整个流程。 开发环境 Ubuntu 18.04 pytorch 1.0 pycharm 实验目的 ...
PyTorch学习笔记(二)图像数据预处理
PyTorch version: 1.4.0 IDE: PyCharm 文章目录0. 写在前面1. 基本变换类1.1 填充1.2 擦除1.3 缩放1.4 裁剪1.5 旋转1.6 翻转1.7 颜色1.8 仿射变换和线性变换1.9 归一化和标准化1.10. Lambda2. 组合变换类3. 自定义...
pytorch之添加BN的实现
今天小编就为大家分享一篇pytorch之添加BN的实现,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
使用anaconda安装pytorch的实现步骤
主要介绍了使用anaconda安装pytorch的实现步骤,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
PyTorch官方教程中文版.pdf
Py Torch是一个基于 Torch的 Python开源机器学习库,用于自然语言处理等应用程序。它主要由Facebook的人工智能小组开发,不仅能够实现强大的GPU加速,同时还支持动态神经网络,这点是现在很多主流框架如 TensorFlow...
zigbee-cluster-library-specification
最新的zigbee-cluster-library-specification说明文档。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL数据库性能提升秘籍:揭秘性能下降幕后真凶及解决策略
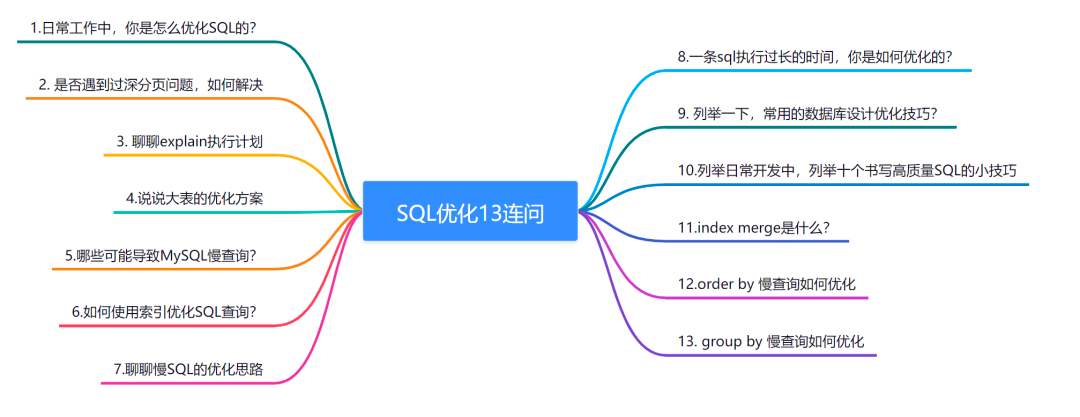
# 1. MySQL数据库性能优化概述**
MySQL数据库性能优化是一项至关重要的任务,可以显著提高应用程序的响应时间和整体用户体验。优化涉及识别和解决影响数据库性能的因素,包括硬件资源瓶颈、软件配置不当和数据库设计缺陷。通过采取适当的优化策略,可以显著提升数据库性能,满足业务需求并提高用户满意度。
# 2. MySQL数据库性能下降的幕后真凶
### 2.1 硬件资源瓶颈
#### 2.1.1 CPU利用率过高
**症状:
如何在unity创建按钮
在 Unity 中创建按钮的步骤如下:
1. 在 Unity 中创建一个 UI Canvas,选择 GameObject -> UI -> Canvas。
2. 在 Canvas 中创建一个按钮,选择 GameObject -> UI -> Button。
3. 在场景视图中调整按钮的位置和大小。
4. 在 Inspector 中设置按钮的文本、颜色、字体等属性。
5. 添加按钮的响应事件,选择按钮,在 Inspector 的 On Click () 中添加相应的方法。
这样就可以创建一个按钮了,你可以在游戏中使用它来触发相应的操作。
JSBSim Reference Manual
JSBSim参考手册,其中包含JSBSim简介,JSBSim配置文件xml的编写语法,编程手册以及一些应用实例等。其中有部分内容还没有写完,估计有生之年很难看到完整版了,但是内容还是很有参考价值的。