系统间数据交互图,给一张参考图片
时间: 2023-11-15 11:38:34 浏览: 218
系统间数据交互图是指表示系统之间数据交互关系的图表,它主要用于描述系统之间数据流动的过程。下面是一个常见的系统间数据交互图示意图:

该图展示了一个简单的客户端和服务器之间数据交互的过程。其中,客户端通过网络将请求数据发送给服务器,服务器接收到请求后进行处理,并将响应数据返回给客户端。在数据交互的过程中,还包括了一些网络协议和数据格式的转换,如HTTP协议和JSON数据格式等。系统间数据交互图是描述系统之间数据流动的重要工具,它可以帮助人们更好地理解系统之间的关系和数据传输的过程。
相关问题
代码实现iOS图片轮播
### 回答1:
可以使用 `UICollectionView` 或 `UIPageViewController` 来实现 iOS 图片轮播。
使用 `UICollectionView` 实现的方法如下:
1. 在您的视图控制器中,创建一个 `UICollectionView` 实例,并将其作为子视图添加到您的视图控制器的视图中。
2. 使用自定义布局实现循环滚动。可以参考以下代码:
```
class LoopCollectionViewFlowLayout: UICollectionViewFlowLayout {
override func targetContentOffset(forProposedContentOffset proposedContentOffset: CGPoint, withScrollingVelocity velocity: CGPoint) -> CGPoint {
guard let collectionView = collectionView else {
return super.targetContentOffset(forProposedContentOffset: proposedContentOffset, withScrollingVelocity: velocity)
}
let collectionViewSize = collectionView.bounds.size
let proposedContentOffsetCenterX = proposedContentOffset.x + collectionViewSize.width * 0.5
let proposedRect = CGRect(x: proposedContentOffset.x, y: 0, width: collectionViewSize.width, height: collectionViewSize.height)
guard let layoutAttributes = layoutAttributesForElements(in: proposedRect) else {
return super.targetContentOffset(forProposedContentOffset: proposedContentOffset, withScrollingVelocity: velocity)
}
let centerX = proposedContentOffsetCenterX
let offset = CGPoint(x: proposedContentOffset.x + nearestTargetOffset(for: layoutAttributes, with: centerX), y: proposedContentOffset.y)
return offset
}
private func nearestTargetOffset(for layoutAttributes: [UICollectionViewLayoutAttributes], with centerX: CGFloat) -> CGFloat {
let targetAttributes = layoutAttributes.sorted { abs($0.center.x - centerX) < abs($1.center.x - centerX) }
let nearestAttribute = targetAttributes.first
return nearestAttribute?.center.x ?? 0 - centerX
}
}
```
3. 创建自定义 `UICollectionViewCell` 类,并在其中添加一个 `UIImageView` 用于显示图片。
4. 实现 `UICollectionViewDataSource` 协议中的方法,用于设置图片数据源和自定义的 `UICollectionViewCell`。
5. 实现定时器
### 回答2:
要实现iOS图片轮播功能,可以按照以下步骤进行:
1. 创建一个UIScrollView,设置其frame和contentSize,确保能够展示一张图片。
2. 在UIScrollView中添加UIImageView,设置其frame和图片内容。
3. 在UIScrollView中添加UIPageControl,设置其frame和总页数。
4. 创建一个定时器,每隔一定时间滚动UIScrollView的内容。
5. 在定时器的回调方法中,通过设置UIScrollView的contentOffset来实现图片的滚动。可以使用UIView的动画函数来实现动画效果。
6. 根据UIScrollView的滚动距离,更新UIPageControl的当前页码。
7. 监听UIPageControl的用户交互事件,在用户切换页面时,通过设置UIScrollView的contentOffset来滚动到指定的图片。
8. 考虑到用户手动滚动UIScrollView的情况,需要在UIScrollView的滚动结束时,重新设置定时器的时间间隔。
以上是一种基本的实现思路,具体的代码实现会涉及到UIScrollView的委托方法、UIImageView的点击事件处理等细节。可以使用Objective-C或Swift语言来实现。
### 回答3:
iOS的图片轮播可以通过使用UIScrollView和UIPageControl来实现。具体步骤如下:
1. 创建一个UIScrollView来显示图片轮播视图。设置UIScrollView的frame大小和contentSize为每张图片的宽度和高度。
2. 创建一个UIPageControl来显示当前显示的图片页数。设置UIPageControl的frame和numberOfPages属性。
3. 将图片视图添加到UIScrollView中。可以通过循环遍历图片数组,创建UIImageView并设置其frame和image属性,然后将其添加到UIScrollView的contentView上。
4. 设置UIScrollView的pagingEnabled属性为true,使其支持翻页效果。
5. 实现UIScrollViewDelegate代理方法scrollViewDidScroll,用于监听UIScrollView的滚动事件。在该方法中可以计算当前显示的页面,并将页面索引赋值给UIPageControl的currentPage属性。
6. 可选的步骤:实现自动轮播效果。可以使用NSTimer来定时调用UIScrollView的scrollRectToVisible:animated:方法来实现自动滚动功能。
综上所述,通过上述步骤可以实现iOS图片轮播效果。在实际开发中,可以根据需求进行相应的定制和扩展,例如添加图片点击事件、添加过渡动画效果等。
用jupyter写一个简单的图片识别界面,模型类型为pth
### 回答1:
首先,你需要安装PyTorch和Jupyter Notebook。安装方法可以参考PyTorch官方网站和Jupyter Notebook官方网站。
然后,你需要准备好要用来测试的图片和你训练的.pth模型。假设你已经将它们放在了同一个文件夹中。
接下来,打开Jupyter Notebook,在一个新的notebook中输入以下代码:
```python
import torch
import torchvision
import torchvision.transforms as transforms
from PIL import Image
import matplotlib.pyplot as plt
# 加载模型
model = torch.load('your_model.pth')
# 定义预处理函数
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 定义类别列表
classes = ['class1', 'class2', 'class3', ...]
# 定义预测函数
def predict(image_path):
# 加载图片
image = Image.open(image_path)
# 预处理图片
image = transform(image)
# 添加批次维度
image = image.unsqueeze(0)
# 将图片输入到模型中进行预测
output = model(image)
# 获取预测结果
_, predicted = torch.max(output.data, 1)
# 返回预测结果
return classes[predicted.item()]
# 加载图片并进行预测
image_path = 'your_image.jpg'
predicted_class = predict(image_path)
# 显示图片和预测结果
image = Image.open(image_path)
plt.imshow(image)
plt.title(predicted_class)
plt.show()
```
在代码中,我们首先加载了我们训练好的.pth模型,然后定义了一个预处理函数,用于将图片转换为模型输入需要的格式。接着,我们定义了一个预测函数,用于将图片输入到模型中进行预测,并返回预测结果。最后,我们加载了一张测试图片,并将其传入预测函数中进行预测,最终将预测结果显示出来。
注意,你需要将代码中的“your_model.pth”替换为你自己训练好的.pth模型的文件名,将“classes”列表替换为你自己的类别列表,将“your_image.jpg”替换为你自己的测试图片的文件名。
完成后,你可以运行代码并查看预测结果。
### 回答2:
要使用Jupyter写一个简单的图片识别界面,首先需要准备一个经过训练的.pth模型,并确保已安装好必要的Python库和Jupyter。
1. 打开Jupyter Notebook,并在一个新的笔记本中创建一个Cell。
2. 在该Cell中,首先导入所需的库:
```python
import torch
import torchvision.transforms as transforms
from PIL import Image
```
3. 将训练好的.pth模型加载到内存中:
```python
model = torch.load('your_model.pth')
```
4. 定义一个函数,用于预处理图像:
```python
def preprocess_image(image):
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
image = transform(image).unsqueeze(0)
return image
```
5. 定义一个函数,用于进行图像识别:
```python
def predict_image(image_path):
image = Image.open(image_path)
image = preprocess_image(image)
output = model(image)
_, predicted = torch.max(output.data, 1)
return predicted.item()
```
6. 最后,定义界面的输入和输出部分:
```python
from IPython.display import display
from ipywidgets import FileUpload, Output, Image
upload = FileUpload()
output = Output()
display(upload)
def on_upload(change):
image_path = 'uploaded_image.jpg'
with open(image_path, 'wb') as file:
file.write(upload.data[0])
with output:
display(Image(value=upload.data[0], format='jpg', width=300, height=300))
prediction = predict_image(image_path)
print(f"图片识别结果为: {prediction}")
upload.observe(on_upload, names='_counter')
display(output)
```
7. 运行该Cell,就会在Jupyter界面中看到一个上传按钮。点击按钮,选择你要识别的图片进行上传,然后该图片将在界面上显示,并输出识别结果。
这样,你就用Jupyter写了一个简单的图片识别界面,可以使用.pth模型进行图像识别。
### 回答3:
Jupyter是一个开源的交互式编程环境,可以用于数据分析和可视化。如果我们想要在Jupyter中编写一个简单的图片识别界面,可以按照以下步骤进行操作:
1. 安装所需的库:首先,我们需要安装Pillow库来处理图像文件,以及Torchvision库来加载和处理模型;如果没有安装,可以使用以下命令安装:
```
!pip install Pillow
!pip install torchvision
```
2. 导入所需的库:在Jupyter笔记本的第一个单元格中,导入所需的库:
```python
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.models as models
from PIL import Image
```
3. 加载预训练模型:选择适合你的任务和数据集的模型,并加载预训练权重。例如,我们可以使用ResNet50模型:
```python
model = models.resnet50(pretrained=True)
```
4. 进行图像预处理:在对图像进行预测之前,我们需要对其进行正确的预处理。这包括将图像调整为模型的输入大小,将像素值标准化为0到1之间的范围,并将图像转换为Torch张量:
```python
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
def preprocess_image(image_path):
image = Image.open(image_path)
image = transform(image).unsqueeze(0)
return image
```
5. 进行预测:在Jupyter笔记本的一个单元格中,定义一个函数来进行图像预测,并根据模型的输出返回预测结果:
```python
def predict_image(image_path):
image = preprocess_image(image_path)
output = model(image)
_, predicted_idx = torch.max(output, 1)
return predicted_idx
```
6. 使用图像识别界面:在Jupyter笔记本中的另一个单元格中,创建一个用于上传图像文件的界面,并在上传成功后调用预测函数并显示结果:
```python
from IPython.display import display
import ipywidgets as widgets
uploader = widgets.FileUpload()
display(uploader)
def on_upload_button_clicked(b):
image_path = list(uploader.value.keys())[0]
predicted_idx = predict_image(image_path)
print(f"预测结果: {predicted_idx}")
upload_button = widgets.Button(description='上传图片')
upload_button.on_click(on_upload_button_clicked)
display(upload_button)
```
以上是在Jupyter中编写一个简单图像识别界面的基本步骤,你可以根据具体的需求和模型类型进行相应的修改和调整。
相关推荐
最新推荐
教材管理系统 毕业设计 任务书
3. 提供留言公告和用户分类管理,增强系统的交互性和个性化。 4. 设计安全控制策略,保障系统和数据的安全。 5. 采用B/S架构,数据库可选用Access或SQL Server 2000,开发技术可选择ASP、PHP或JSP。 6. 系统需使用...
微信小程序仿朋友圈发布动态功能
【微信小程序仿朋友圈发布动态功能】的实现主要...这个功能的实现不仅展示了微信小程序的基本组件使用,还涉及了数据绑定、事件处理、图片上传和用户交互等关键概念,对于学习和实践微信小程序开发具有很高的参考价值。
二阶RLC串联电路的零输入响应matlab课程设计
它提供了一个交互式环境,可以快速实现算法、模型和系统的设计、仿真和可视化。MATLAB 的功能特点包括: * 强大的数值计算能力 * 广泛的图形和可视化功能 * 强大的编程语言和开发环境 * 广泛的应用领域,包括信号...
XML轻松学习手册--XML肯定是未来的发展趋势,不论是网页设计师还是网络程序员,都应该及时学习和了解
我的理解是它满足了网络共享和数据交互,使用DTD最大的好处在于DTD文件的共享。(就是上文DTD说明语句中的PUBLIC属性)。比如,两个相同行业不同地区的人使用同一个DTD文件来作为文档创建规范,那么他们的数据就很容易...
基于YOLOv5的猫狗鼠情绪分类模型训练实践与项目复盘
在宠物情绪识别领域,利用深度学习技术进行分类是一个热门且具有实际意义的应用场景。基于此,我选择了YOLOv5进行分类模型的训练,用于识别猫、狗、鼠的不同情绪类型。通过自定义数据集,结合YOLOv5强大的分类功能,开发了一个轻量化的情绪分类模型。
1. YOLOv5 分类模型的应用:虽然YOLOv5更多应用于目标检测,但分类模型在小数据集或特定任务上也能发挥强大的作用。本文实践展示了如何使用YOLOv5进行高效的情绪分类任务。
2. 自定义数据集的准备:高质量的数据集是成功训练模型的基础。在这个项目中,通过图像增强等手段,增加了训练数据的多样性,显著提高了模型的表现。
3. 模型超参数调整的重要性:超参数(如学习率、批次大小、训练轮次)的选择直接影响到模型的训练效果。根据不同的任务场景,灵活调整这些参数,可以得到显著的性能提升。
4. 模型优化与部署:通过剪枝和量化技术,可以在不明显降低模型性能的情况下,减少模型的大小和计算需求,这对部署到资源有限的设备非常重要。
------------------上传为权重文件,需要安装环境欢迎咨询
解决Eclipse配置与导入Java工程常见问题
"本文主要介绍了在Eclipse中配置和导入Java工程时可能遇到的问题及解决方法,包括工作空间切换、项目导入、运行配置、构建路径设置以及编译器配置等关键步骤。"
在使用Eclipse进行Java编程时,可能会遇到各种配置和导入工程的问题。以下是一些基本的操作步骤和解决方案:
1. **切换或创建工作空间**:
- 当Eclipse出现问题时,首先可以尝试切换到新的工作空间。通过菜单栏选择`File > Switch Workspace > Other`,然后选择一个新的位置作为你的工作空间。这有助于排除当前工作空间可能存在的配置问题。
2. **导入项目**:
- 如果你有现有的Java项目需要导入,可以选择`File > Import > General > Existing Projects into Workspace`,然后浏览并选择你要导入的项目目录。确保项目结构正确,尤其是`src`目录,这是存放源代码的地方。
3. **配置运行配置**:
- 当你需要运行项目时,如果出现找不到库的问题,可以在Run Configurations中设置。在`Run > Run Configurations`下,找到你的主类,确保`Main class`设置正确。如果使用了`System.loadLibrary()`加载本地库,需要在`Arguments`页签的`VM Arguments`中添加`-Djava.library.path=库路径`。
4. **调整构建路径**:
- 在项目上右键点击,选择`Build Path > Configure Build Path`来管理项目的依赖项。
- 在`Libraries`选项卡中,你可以添加JRE系统库,如果需要更新JRE版本,可以选择`Add Library > JRE System Library`,然后选择相应的JRE版本。
- 如果有外部的jar文件,可以在`Libraries`中选择`Add External Jars`,将jar文件添加到构建路径,并确保在`Order and Export`中将其勾选,以便在编译和运行时被正确引用。
5. **设置编译器兼容性**:
- 在项目属性中,选择`Java Compiler`,可以设置编译器的兼容性级别。如果你的目标是Java 1.6,那么将`Compiler Compliance Level`设置为1.6。注意,不同的Java版本可能有不同的语法特性,因此要确保你的编译器设置与目标平台匹配。
这些步骤可以帮助解决Eclipse中常见的Java项目配置问题。当遇到错误时,记得检查每个环节,确保所有配置都符合你的项目需求。同时,保持Eclipse及其插件的更新,也可以避免很多已知的问题。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
【错误处理与调试】:Python操作MySQL的常见问题与解决之道
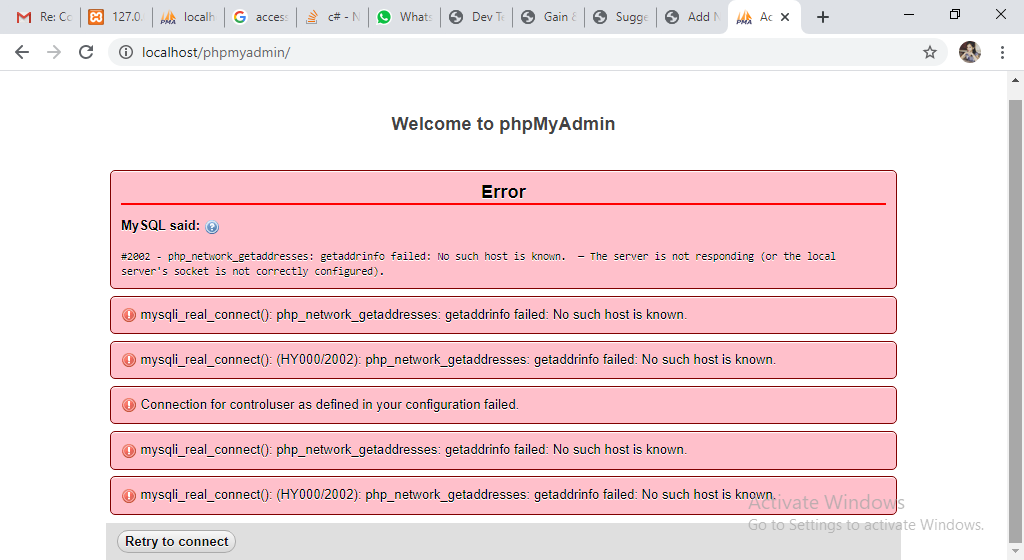
# 1. Python与MySQL交互基础
在当今的数据驱动世界中,Python与MySQL的交互变得尤为重要。作为一款广泛使用的动态编程语言,Python具有简洁明了的语法,且易于学习,它在数据分析、科学计算以及Web开发等多个领域中都表现出色。而MySQL作为流行的开源关系数据库管理系统,广泛应用于网站后端数据存储与管理。
首先,要实现Python与MySQL的交互,
#include<stdio.h> void main() { char c; scanf("%c",&c); print("%d\n",c); }
你提供的代码是C语言的简单程序,用于从标准输入读取一个字符,并试图打印该字符的ASCII码值。然而,程序中存在一个小错误。在C语言中,函数`printf`用于输出,而不是`print`。下面是修正后的代码:
```c
#include<stdio.h>
void main()
{
char c;
scanf("%c", &c);
printf("%d\n", c);
}
```
这段代码的作用如下:
1. 包含标准输入输出库`stdio.h`,它提供了输入输出函数的声明。
2. 定义`main`函数,它是每个C程序的入口点。
3. 声明一个`char`类型的变量`
真空发生器:工作原理与抽吸性能分析
"真空发生器是一种利用正压气源产生负压的设备,适用于需要正负压转换的气动系统,常见应用于工业自动化多个领域,如机械、电子、包装等。真空发生器主要通过高速喷射压缩空气形成卷吸流动,从而在吸附腔内制造真空。其工作原理基于流体力学的连续性和伯努利理想能量方程,通过改变截面面积和流速来调整压力,达到产生负压的目的。根据喷管出口的马赫数,真空发生器可以分为亚声速、声速和超声速三种类型,其中超声速喷管型通常能提供最大的吸入流量和最高的吸入口压力。真空发生器的主要性能参数包括空气消耗量、吸入流量和吸入口处的压力。"
真空发生器是工业生产中不可或缺的元件,其工作原理基于喷管效应,利用压缩空气的高速喷射,在喷管出口形成负压。当压缩空气通过喷管时,由于喷管截面的收缩,气流速度增加,根据连续性方程(A1v1=A2v2),截面增大导致流速减小,而伯努利方程(P1+1/2ρv1²=P2+1/2ρv2²)表明流速增加会导致压力下降,当喷管出口流速远大于入口流速时,出口压力会低于大气压,产生真空。这种现象在Laval喷嘴(先收缩后扩张的超声速喷管)中尤为明显,因为它能够更有效地提高流速,实现更高的真空度。
真空发生器的性能主要取决于几个关键参数:
1. 空气消耗量:这是指真空发生器从压缩空气源抽取的气体量,直接影响到设备的运行成本和效率。
2. 吸入流量:指设备实际吸入的空气量,最大吸入流量是在无阻碍情况下,吸入口直接连通大气时的流量。
3. 吸入口处压力:表示吸入口的真空度,是评估真空发生器抽吸能力的重要指标。
在实际应用中,真空发生器常与吸盘结合,用于吸附和搬运各种物料,特别是对易碎、柔软、薄的非铁非金属材料或球形物体,因其抽吸量小、真空度要求不高的特点而备受青睐。深入理解真空发生器的抽吸机理和影响其性能的因素,对于优化气路设计和选择合适的真空发生器具有重要意义,可以提升生产效率,降低成本,并确保作业过程的稳定性和可靠性。