建立一个二维数组,求其横向数值之和,并显示C语言
时间: 2023-06-19 12:06:22 浏览: 123
下面是一个示例代码,用于建立一个二维数组并计算其每行的数值之和:
```c
#include <stdio.h>
#define ROWS 3
#define COLS 4
int main()
{
int arr[ROWS][COLS] = {{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}};
for (int i = 0; i < ROWS; ++i)
{
int row_sum = 0;
for (int j = 0; j < COLS; ++j)
{
row_sum += arr[i][j];
}
printf("Row %d sum = %d\n", i, row_sum);
}
return 0;
}
```
在这个示例中,我们首先定义了一个二维数组 `arr`,其包含 3 行 4 列的元素。然后,我们使用两个嵌套的循环来遍历每个元素,并计算每行的数值之和。最后,我们使用 `printf` 函数将每行的总和输出到控制台。
相关问题
C语言多重循环如何运行
### C语言多重循环执行机制解释
#### 双重`for`循环的工作原理
在C语言中,双重`for`循环通常用于遍历多维数据结构,比如二维数组。外层循环控制行数,内层循环负责列的操作。
当初始化变量`i=0`并进入第一个`for`循环时,会检查条件`i<3`是否满足;如果为真,则开始处理内部的第二个`for`循环,在这里设置另一个计数器`j=0`来访问每一行中的各个元素[^1]。每次迭代都会更新索引值,并按照指定规则填充或修改矩阵内的数值。
具体到例子中提到的情况:
- 当`i=0`时,启动第二级循环,此时`j=0`也符合条件`j<2`,于是将位置`(0, 0)`处设为两者的和即`a[0][0]=0+0=0`;
- 接着`j`自增变为`1`再次测试条件,由于仍然小于`2`,故而继续运行并将下一个单元格置成相应的求和结果`a[0][1]=0+1=1`;
- 随后`j`增加至`2`不再符合范围限制(`j>=2`),这标志着一轮完整的横向扫描结束,随后返回上一层使`i`加一准备下一行的数据处理流程。
这种模式重复直到所有的行列组合都被覆盖完毕为止。
#### `do...while`单次后测循环的特点
不同于前缀形式的`for`/`while`先验证再行动的方式,`do...while`结构允许至少一次无条件地执行主体代码块之后才去评估终止表达式的真假状态。
考虑给出的例子:
```c
int a = 1;
int b = 10;
do {
b -= a; // 减法运算
printf("b=%d\n", b);
} while (b-- > 0); // 后置递减操作符应用于b
```
这段程序首先不问任何前提就做了一轮计算——把`b`减少掉当前的`a`值得到新的`b=9`,打印出来显示变化后的值。接着才是决定要不要再来一遍的关键时刻:通过比较剩余量与零的关系以及同步降低基数本身完成逻辑判断。在这个案例里因为初始设定使得最终不会陷入无限循环而是适时停止下来[^2]。
#### 组合使用不同类型的循环构建复杂算法
实际编程过程中经常遇到需要嵌套多种循环的情形,例如三重甚至更深级别的迭代可能是为了适应特定应用场景下的需求。理解每种基本构件的行为特性有助于开发者灵活运用这些工具解决更广泛的问题集。
xx1, xx2 = np.meshgrid( np.linspace(x1_min, x1_max, 100), # 在x1范围内生成100个等间距点,每行数据完全重复,第i行所有元素值 = 第i个x1坐标值 np.linspace(x2_min, x2_max, 100) # 在x2范围内生成100个等间距点 ) # xx1和xx2均为100x100的矩阵,每个点代表一个(x1, x2)组合 # 计算网格点上逻辑回归的预测概率 Z = sigmoid(np.c_[np.ones(xx1.ravel().shape[0]), xx1.ravel(), xx2.ravel()].dot(theta)) Z = Z.reshape(xx1.shape)画出xx1,xx2的变化
<think>嗯,用户现在想了解的是关于`xx1`和`xx2`在生成网格时的变化,以及如何用这些网格点来计算逻辑回归的预测概率,并最终绘制结果。我之前已经解释过`Z = sigmoid(...)`那部分代码,现在用户可能更关心`meshgrid`生成的数据结构,以及`xx1`和`xx2`是如何变化的。
首先,我需要回顾`np.meshgrid`的作用。这个函数是用来生成坐标矩阵的,通常在绘制二维图形时用到。比如,用户给出的例子中,`np.linspace`分别在x1和x2的范围内生成100个点,然后通过`meshgrid`创建两个100x100的矩阵。其中,`xx1`的每一行都是相同的x1值,而`xx2`的每一列都是相同的x2值。这样,每个点`(xx1[i,j], xx2[i,j])`就代表了一个网格点的坐标。
接下来,用户可能想知道为什么需要将`xx1`和`xx2`展平(ravel)后再进行运算。这里需要解释的是,逻辑回归模型需要将每个样本作为一行输入,所以需要将所有网格点转换为一维数组,每个点作为一个样本。通过`np.c_`将全1向量(偏置项)、展平后的xx1和xx2水平拼接,形成一个10000x3的特征矩阵,其中每一行对应一个网格点的特征向量。之后,通过点乘参数`theta`计算出线性组合,再经过sigmoid函数得到概率值。
然后,得到的Z是一维数组,有10000个元素,对应每个网格点的预测概率。为了绘图,需要将Z重新reshape成与原来的xx1和xx2相同的形状(100x100),这样才能在二维平面上正确显示每个点的位置和对应的概率值。
用户提到“画出xx1,xx2的变化”,可能需要更直观地展示xx1和xx2的结构。比如,可以用简单的例子,比如3x3的网格,来演示xx1和xx2的具体数值,以及展平后的结果。此外,解释为什么需要这样的结构,比如在绘图时,需要保持矩阵结构以便使用contour或contourf函数绘制等高线或填充图。
可能还需要讨论应用场景,比如分类边界可视化,热力图等。同时,检查是否有一些常见的错误,比如参数theta的维度是否正确,或者reshape时是否匹配原来的网格形状。另外,用户可能对ravel和flatten的区别有疑问,需要指出ravel返回的是视图,而flatten返回的是副本,但在这里可能影响不大。
最后,总结整个过程,从生成网格、处理数据、计算预测值到绘图,强调每个步骤的作用,确保用户能够理解整个流程的逻辑和目的。</think>好的,我来分步解释 `xx1` 和 `xx2` 的生成过程、数据结构及其可视化意义:
---
### **1. `np.meshgrid()` 的作用**
`xx1, xx2 = np.meshgrid(np.linspace(...), np.linspace(...))` 的目的是生成一个 **坐标网格矩阵**,用于覆盖整个特征空间。以下是关键步骤:
#### **(1) `np.linspace()` 生成等间距点**
- `x1_min` 到 `x1_max` 生成 **100个等间距点**(如 `[-3, -2.94, ..., 3]`)
- `x2_min` 到 `x2_max` 同样生成 **100个等间距点**
#### **(2) `np.meshgrid()` 的矩阵构造**
- `xx1` 的每一行 **完全重复相同的x1值**
(例如第0行全为 `x1_min`,第1行全为 `x1_min + 步长`,依此类推)
- `xx2` 的每一列 **完全重复相同的x2值**
(例如第0列全为 `x2_min`,第1列全为 `x2_min + 步长`,依此类推)
#### **(3) 生成结果示例**
假设 `x1` 范围是 `[0, 1]`,`x2` 范围是 `[2, 3]`,生成 `3x3` 网格:
```python
xx1 = [[0, 0.5, 1],
[0, 0.5, 1],
[0, 0.5, 1]]
xx2 = [[2, 2, 2],
[2.5, 2.5, 2.5],
[3, 3, 3]]
```
每个位置 `(i,j)` 的组合 `(xx1[i,j], xx2[i,j])` 对应一个坐标点,总共有 $100 \times 100 = 10,000$ 个点。
---
### **2. `xx1` 和 `xx2` 的可视化意义**
#### **(1) 网格点的空间分布**
- `xx1` 控制 **横向坐标**,从左到右均匀分布
- `xx2` 控制 **纵向坐标**,从下到上均匀分布
- 二者组合形成 **覆盖整个特征平面的网格点**,例如:
```
点 (0,0): (x1_min, x2_min)
点 (0,1): (x1_min + 步长, x2_min)
...
点 (99,99): (x1_max, x2_max)
```
#### **(2) 展平后的坐标变化**
- `xx1.ravel()` 和 `xx2.ravel()` 将矩阵展平为 **一维数组**,长度均为 $10,000$
- **展平顺序**:按行展开(C语言风格),例如:
```
xx1.ravel() = [0, 0.5, 1, 0, 0.5, 1, 0, 0.5, 1]
xx2.ravel() = [2, 2, 2, 2.5, 2.5, 2.5, 3, 3, 3]
```
---
### **3. 预测值 `Z` 的恢复过程**
#### **(1) 计算逻辑回归概率**
- 所有网格点展平后组成 $10,000 \times 3$ 的特征矩阵(含偏置项)
- 通过 `sigmoid(theta^T X)` 计算每个点的概率,得到一维数组 `Z`(长度 $10,000$)
#### **(2) 恢复为网格形状**
- `Z.reshape(xx1.shape)` 将一维数组恢复为 $100 \times 100$ 的矩阵
- **恢复后的 `Z` 与原始网格坐标一一对应**,例如:
```
Z[0,0] 对应 (x1_min, x2_min) 的概率
Z[50,50] 对应中间点的概率
Z[99,99] 对应 (x1_max, x2_max) 的概率
```
---
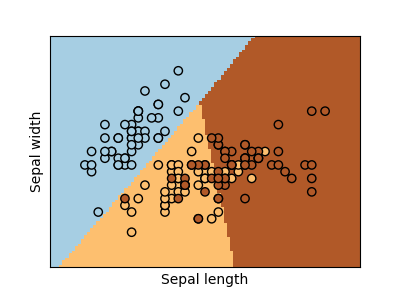
### **4. 可视化效果示意图**
#### **(1) 网格点分布**

#### **(2) 预测结果热力图**
- 使用 `contourf(xx1, xx2, Z)` 绘制时:
- **颜色深浅**:表示概率高低(如蓝色=0,红色=1)
- **决策边界**:`Z=0.5` 的等高线即为分类边界
---
### **5. 关键参数说明**
| 参数/操作 | 作用 |
|--------------------|--------------------------------------------------------------------|
| `np.linspace()` | 生成等间距点,控制网格密度(100点平衡精度与计算效率) |
| `xx1.shape` | 固定为 $100 \times 100$,确保覆盖整个特征空间 |
| `ravel()` | 展平操作,将矩阵转换为模型输入所需的格式 |
| `reshape()` | 恢复网格形状,匹配可视化工具(如 `matplotlib`)的输入要求 |
---
### **6. 应用场景**
此代码常用于:
1. **分类边界可视化**:显示逻辑回归的决策面
2. **概率密度图**:展示模型对空间各点的置信度
3. **多维特征分析**(通过投影到二维平面)
阅读全文
相关推荐
大家在看
SCSI-ATA-Translation-3_(SAT-3)-Rev-01a
本资料是SAT协议,即USB转接桥。通过上位机直接发送命令给SATA盘。
Surface pro 7 SD卡固定硬盘X64驱动带数字签名
针对surface pro 7内置硬盘较小,外扩SD卡后无法识别成本地磁盘,本驱动让windows X64把TF卡识别成本地硬盘,并带有数字签名,无需关闭系统强制数字签名,启动时也不会出现“修复系统”的画面,完美,无毒副作用,且压缩文件中带有详细的安装说明,你只需按部就班的执行即可。本驱动非本人所作,也是花C币买的,现在操作成功了,并附带详细的操作说明供大家使用。
文件内容如下:
surfacepro7_x64.zip
├── cfadisk.cat
├── cfadisk.inf
├── cfadisk.sys
├── EVRootCA.crt
└── surface pro 7将SD卡转换成固定硬盘驱动.docx
实验2.Week04_通过Console线实现对交换机的配置和管理.pdf
交换机,console
景象匹配精确制导中匹配概率的一种估计方法
基于景象匹配制导的飞行器飞行前需要进行航迹规划, 就是在飞行区域中选择出一些匹配概率高的匹配
区, 作为相关匹配制导的基准, 由此提出了估计匹配区匹配概率的问题本文模拟飞行中匹配定位的过程定义了匹
配概率, 并提出了基准图的三个特征参数, 最后通过线性分类器, 实现了用特征参数估计匹配概率的目标,
并进行了实验验证
Low-cost high-gain differential integrated 60 GHz phased array antenna in PCB process
Low-cost high-gain differential integrated 60 GHz phased array antenna in PCB process
最新推荐
C语言中二维数组作为函数参数来传递的三种方法
需要注意的是,在第三种方法中,我们不能使用array[i][j]这种形式来取值,而是需要将二维数组看成一个一维数组,使用array[i * j + j]这种形式来进行取值。这是因为在传参的时候,我们将array[][]数组当成二级指针来...
PHP将二维数组某一个字段相同的数组合并起来的方法
通过这种方法,我们成功地将原始二维数组中`time`字段相同的元素合并到了一起,形成一个新的二维数组,其中每个子数组都包含了`time`字段相同的所有元素。这个过程不仅可以应用于`time`字段,还可以扩展到任何其他...
Python reshape的用法及多个二维数组合并为三维数组的实例
方法二是通过`np.append`和`reshape`结合使用,当二维数组的形状不同时,可以先将它们拼接成一个大的一维数组,然后根据原始的二维数组的形状进行重塑,从而得到所需的三维数组。 在实际应用中,这些数组操作函数...
Python二维数组实现求出3*3矩阵对角线元素的和示例
'二维数组实现求三阶矩阵的对角线元素之和' sum = 0 # 定义一个3x3的矩阵 matrix = [[0, 1, 0], [0, 21, 0], [0, 12, 0]] # 或者动态创建一个3x3矩阵 matrix2 = [[0 for _ in range(3)] for _ in range(3)] ...
python 使用pandas的dataframe一维数组和二维数组分别按行写入csv或excel
本文将详细讲解如何使用Pandas的DataFrame来处理一维数组和二维数组,并将其按行写入CSV或Excel文件。 首先,我们要了解Pandas DataFrame的基本概念。DataFrame是一个二维表格型数据结构,它具有行和列的索引,可以...
Cyclone IV硬件配置详细文档解析
Cyclone IV是Altera公司(现为英特尔旗下公司)的一款可编程逻辑设备,属于Cyclone系列FPGA(现场可编程门阵列)的一部分。作为硬件设计师,全面了解Cyclone IV配置文档至关重要,因为这直接影响到硬件设计的成功与否。配置文档通常会涵盖器件的详细架构、特性和配置方法,是设计过程中的关键参考材料。
首先,Cyclone IV FPGA拥有灵活的逻辑单元、存储器块和DSP(数字信号处理)模块,这些是设计高效能、低功耗的电子系统的基石。Cyclone IV系列包括了Cyclone IV GX和Cyclone IV E两个子系列,它们在特性上各有侧重,适用于不同应用场景。
在阅读Cyclone IV配置文档时,以下知识点需要重点关注:
1. 设备架构与逻辑资源:
- 逻辑单元(LE):这是构成FPGA逻辑功能的基本单元,可以配置成组合逻辑和时序逻辑。
- 嵌入式存储器:包括M9K(9K比特)和M144K(144K比特)两种大小的块式存储器,适用于数据缓存、FIFO缓冲区和小规模RAM。
- DSP模块:提供乘法器和累加器,用于实现数字信号处理的算法,比如卷积、滤波等。
- PLL和时钟网络:时钟管理对性能和功耗至关重要,Cyclone IV提供了可配置的PLL以生成高质量的时钟信号。
2. 配置与编程:
- 配置模式:文档会介绍多种配置模式,如AS(主动串行)、PS(被动串行)、JTAG配置等。
- 配置文件:在编程之前必须准备好适合的配置文件,该文件通常由Quartus II等软件生成。
- 非易失性存储器配置:Cyclone IV FPGA可使用非易失性存储器进行配置,这些配置在断电后不会丢失。
3. 性能与功耗:
- 性能参数:配置文档将详细说明该系列FPGA的最大工作频率、输入输出延迟等性能指标。
- 功耗管理:Cyclone IV采用40nm工艺,提供了多级节能措施。在设计时需要考虑静态和动态功耗,以及如何利用各种低功耗模式。
4. 输入输出接口:
- I/O标准:支持多种I/O标准,如LVCMOS、LVTTL、HSTL等,文档会说明如何选择和配置适合的I/O标准。
- I/O引脚:每个引脚的多功能性也是重要考虑点,文档会详细解释如何根据设计需求进行引脚分配和配置。
5. 软件工具与开发支持:
- Quartus II软件:这是设计和配置Cyclone IV FPGA的主要软件工具,文档会介绍如何使用该软件进行项目设置、编译、仿真以及调试。
- 硬件支持:除了软件工具,文档还可能包含有关Cyclone IV开发套件和评估板的信息,这些硬件平台可以加速产品原型开发和测试。
6. 应用案例和设计示例:
- 实际应用:文档中可能包含针对特定应用的案例研究,如视频处理、通信接口、高速接口等。
- 设计示例:为了降低设计难度,文档可能会提供一些设计示例,它们可以帮助设计者快速掌握如何使用Cyclone IV FPGA的各项特性。
由于文件列表中包含了三个具体的PDF文件,它们可能分别是针对Cyclone IV FPGA系列不同子型号的特定配置指南,或者是覆盖了特定的设计主题,例如“cyiv-51010.pdf”可能包含了针对Cyclone IV E型号的详细配置信息,“cyiv-5v1.pdf”可能是版本1的配置文档,“cyiv-51008.pdf”可能是关于Cyclone IV GX型号的配置指导。为获得完整的技术细节,硬件设计师应当仔细阅读这三个文件,并结合产品手册和用户指南。
以上信息是Cyclone IV FPGA配置文档的主要知识点,系统地掌握这些内容对于完成高效的设计至关重要。硬件设计师必须深入理解文档内容,并将其应用到实际的设计过程中,以确保最终产品符合预期性能和功能要求。
【WinCC与Excel集成秘籍】:轻松搭建数据交互桥梁(必读指南)
# 摘要
本论文深入探讨了WinCC与Excel集成的基础概念、理论基础和实践操作,并进一步分析了高级应用以及实际案例。在理论部分,文章详细阐述了集成的必要性和优势,介绍了基于OPC的通信机制及不同的数据交互模式,包括DDE技术、VBA应用和OLE DB数据访问方法。实践操作章节中,着重讲解了实现通信的具体步骤,包括DDE通信、VBA的使
华为模拟互联地址配置
### 配置华为设备模拟互联网IP地址
#### 一、进入接口配置模式并分配IP地址
为了使华为设备能够模拟互联网连接,需先为指定的物理或逻辑接口设置有效的公网IP地址。这通常是在广域网(WAN)侧执行的操作。
```shell
[Huawei]interface GigabitEthernet 0/0/0 # 进入特定接口配置视图[^3]
[Huawei-GigabitEthernet0/0/0]ip address X.X.X.X Y.Y.Y.Y # 设置IP地址及其子网掩码,其中X代表具体的IPv4地址,Y表示对应的子网掩码位数
```
这里的`GigabitEth
Java游戏开发简易实现与地图控制教程
标题和描述中提到的知识点主要是关于使用Java语言实现一个简单的游戏,并且重点在于游戏地图的控制。在游戏开发中,地图控制是基础而重要的部分,它涉及到游戏世界的设计、玩家的移动、视图的显示等等。接下来,我们将详细探讨Java在游戏开发中地图控制的相关知识点。
1. Java游戏开发基础
Java是一种广泛用于企业级应用和Android应用开发的编程语言,但它的应用范围也包括游戏开发。Java游戏开发主要通过Java SE平台实现,也可以通过Java ME针对移动设备开发。使用Java进行游戏开发,可以利用Java提供的丰富API、跨平台特性以及强大的图形和声音处理能力。
2. 游戏循环
游戏循环是游戏开发中的核心概念,它控制游戏的每一帧(frame)更新。在Java中实现游戏循环一般会使用一个while或for循环,不断地进行游戏状态的更新和渲染。游戏循环的效率直接影响游戏的流畅度。
3. 地图控制
游戏中的地图控制包括地图的加载、显示以及玩家在地图上的移动控制。Java游戏地图通常由一系列的图像层构成,比如背景层、地面层、对象层等,这些图层需要根据游戏逻辑进行加载和切换。
4. 视图管理
视图管理是指游戏世界中,玩家能看到的部分。在地图控制中,视图通常是指玩家的视野,它需要根据玩家位置动态更新,确保玩家看到的是当前相关场景。使用Java实现视图管理时,可以使用Java的AWT和Swing库来创建窗口和绘制图形。
5. 事件处理
Java游戏开发中的事件处理机制允许对玩家的输入进行响应。例如,当玩家按下键盘上的某个键或者移动鼠标时,游戏需要响应这些事件,并更新游戏状态,如移动玩家角色或执行其他相关操作。
6. 游戏开发工具
虽然Java提供了强大的开发环境,但通常为了提升开发效率和方便管理游戏资源,开发者会使用一些专门的游戏开发框架或工具。常见的Java游戏开发框架有LibGDX、LWJGL(轻量级Java游戏库)等。
7. 游戏地图的编程实现
在编程实现游戏地图时,通常需要以下几个步骤:
- 定义地图结构:包括地图的大小、图块(Tile)的尺寸、地图层级等。
- 加载地图数据:从文件(如图片或自定义的地图文件)中加载地图数据。
- 地图渲染:在屏幕上绘制地图,可能需要对地图进行平滑滚动(scrolling)、缩放(scaling)等操作。
- 碰撞检测:判断玩家或其他游戏对象是否与地图中的特定对象发生碰撞,以决定是否阻止移动等。
- 地图切换:实现不同地图间的切换逻辑。
8. JavaTest01示例
虽然提供的信息中没有具体文件内容,但假设"javaTest01"是Java项目或源代码文件的名称。在这样的示例中,"javaTest01"可能包含了一个或多个类(Class),这些类中包含了实现地图控制逻辑的主要代码。例如,可能存在一个名为GameMap的类负责加载和渲染地图,另一个类GameController负责处理游戏循环和玩家输入等。
通过上述知识点,我们可以看出实现一个简单的Java游戏地图控制不仅需要对Java语言有深入理解,还需要掌握游戏开发相关的概念和技巧。在具体开发过程中,还需要参考相关文档和API,以及可能使用的游戏开发框架和工具的使用指南。
【超市销售数据深度分析】:从数据库挖掘商业价值的必经之路
# 摘要
本文全面探讨了超市销售数据分析的方法与应用,从数据的准备、预处理到探索性数据分析,再到销售预测与市场分析,最后介绍高级数据分析技术在销售领域的应用。通过详细的章节阐述,本文着重于数据收集、清洗、转换、可视化和关联规则挖掘等关键步骤。