Algorithm 1: The online LyDROO algorithm for solving (P1). input : Parameters V , {γi, ci}Ni=1, K, training interval δT , Mt update interval δM ; output: Control actions xt,ytKt=1; 1 Initialize the DNN with random parameters θ1 and empty replay memory, M1 ← 2N; 2 Empty initial data queue Qi(1) = 0 and energy queue Yi(1) = 0, for i = 1,··· ,N; 3 fort=1,2,...,Kdo 4 Observe the input ξt = ht, Qi(t), Yi(t)Ni=1 and update Mt using (8) if mod (t, δM ) = 0; 5 Generate a relaxed offloading action xˆt = Πθt ξt with the DNN; 6 Quantize xˆt into Mt binary actions xti|i = 1, · · · , Mt using the NOP method; 7 Compute Gxti,ξt by optimizing resource allocation yit in (P2) for each xti; 8 Select the best solution xt = arg max G xti , ξt and execute the joint action xt , yt ; { x ti } 9 Update the replay memory by adding (ξt,xt); 10 if mod (t, δT ) = 0 then 11 Uniformly sample a batch of data set {(ξτ , xτ ) | τ ∈ St } from the memory; 12 Train the DNN with {(ξτ , xτ ) | τ ∈ St} and update θt using the Adam algorithm; 13 end 14 t ← t + 1; 15 Update {Qi(t),Yi(t)}N based on xt−1,yt−1 and data arrival observation At−1N using (5) and (7). i=1 i i=1 16 end With the above actor-critic-update loop, the DNN consistently learns from the best and most recent state-action pairs, leading to a better policy πθt that gradually approximates the optimal mapping to solve (P3). We summarize the pseudo-code of LyDROO in Algorithm 1, where the major computational complexity is in line 7 that computes Gxti,ξt by solving the optimal resource allocation problems. This in fact indicates that the proposed LyDROO algorithm can be extended to solve (P1) when considering a general non-decreasing concave utility U (rit) in the objective, because the per-frame resource allocation problem to compute Gxti,ξt is a convex problem that can be efficiently solved, where the detailed analysis is omitted. In the next subsection, we propose a low-complexity algorithm to obtain G xti, ξt. B. Low-complexity Algorithm for Optimal Resource Allocation Given the value of xt in (P2), we denote the index set of users with xti = 1 as Mt1, and the complementary user set as Mt0. For simplicity of exposition, we drop the superscript t and express the optimal resource allocation problem that computes G xt, ξt as following (P4) : maximize j∈M0 ajfj/φ − Yj(t)κfj3 + i∈M1 {airi,O − Yi(t)ei,O} (28a) τ,f,eO,rO 17 ,算法建立的模型是什么
时间: 2023-06-16 14:05:48 浏览: 189

java.lang.RuntimeException: Unsupported algorithm: HmacSHA1解决方法
该算法建立了一个基于深度强化学习的在线优化框架,用于解决移动边缘计算网络中的资源优化问题。具体来说,它使用一个深度神经网络作为演员,学习如何产生最优的决策,同时使用一个临时记忆库来存储之前的状态和行动,用于训练一个深度神经网络作为评论家,评估当前策略的质量。此外,该算法还提出了一种低复杂度的算法来求解最优的资源分配问题。
阅读全文
相关推荐
最新推荐
中文翻译论文:The wake-sleep algorithm for unsupervised neural networks
"中文翻译论文:The wake-sleep algorithm for unsupervised neural networks" 本文介绍了一个在随机神经元组成的多层网络上的无监督学习算法,称为wake-sleep算法。该算法由Hinton提出,主要用于解决多层神经网络...
2023全球人工智能研究院观点报告:生成式人工智能对企业的影响和商业前景
内容概要:报告详细介绍了生成式人工智能对企业和消费者的影响及其商业前景。生成式人工智能通过生成与训练数据相似的新颖数据,提升了人工智能从‘赋能者’到‘协作者’的角色。报告讨论了生成式人工智能的技术基础,如Transformers,以及在消费者和企业中的应用案例。文中指出,生成式人工智能可以优化企业的工作流程,提高效率和创新能力,但同时强调了安全性、数据隐私和道德等问题。
适合人群:企业高管、技术领导者、数据科学家、产品经理等。
使用场景及目标:帮助企业理解和评估生成式人工智能的商业潜力,优化内部流程,提高效率和创新力,以及防范潜在的风险。
其他说明:生成式人工智能正处于快速发展的初期阶段,各行业都有广阔的应用前景,但需要注意监管和风险管理。
2024年第三季度深圳房地产市场回顾-CBRE.pdf
2024年第三季度深圳房地产市场回顾-CBRE
【java毕业设计】springboot南皮站化验室(springboot+vue+mysql+说明文档).zip
项目经过测试均可完美运行!
环境说明:
开发语言:java
框架:ssm
jdk版本:jdk1.8
数据库:mysql 5.7+
数据库工具:Navicat11+
管理工具:maven
开发工具:idea/eclipse
部署容器:tomcat7+
【路径规划】基于matlab单障碍物和多障碍物的机器人避达问题仿真【Matlab仿真 7339期】.md
CSDN Matlab武动乾坤上传的资料均有对应的代码,代码均可运行,亲测可用,适合小白;
1、代码压缩包内容
主函数:main.m;
调用函数:其他m文件;无需运行
运行结果效果图;
2、代码运行版本
Matlab 2019b;若运行有误,根据提示修改;若不会,私信博主;
3、运行操作步骤
步骤一:将所有文件放到Matlab的当前文件夹中;
步骤二:双击打开main.m文件;
步骤三:点击运行,等程序运行完得到结果;
4、仿真咨询
如需其他服务,可私信博主或扫描博客文章底部QQ名片;
4.1 博客或资源的完整代码提供
4.2 期刊或参考文献复现
4.3 Matlab程序定制
4.4 科研合作
构建基于Django和Stripe的SaaS应用教程
资源摘要信息: "本资源是一套使用Django框架开发的SaaS应用程序,集成了Stripe支付处理和Neon PostgreSQL数据库,前端使用了TailwindCSS进行设计,并通过GitHub Actions进行自动化部署和管理。"
知识点概述:
1. Django框架: Django是一个高级的Python Web框架,它鼓励快速开发和干净、实用的设计。它是一个开源的项目,由经验丰富的开发者社区维护,遵循“不要重复自己”(DRY)的原则。Django自带了一个ORM(对象关系映射),可以让你使用Python编写数据库查询,而无需编写SQL代码。
2. SaaS应用程序: SaaS(Software as a Service,软件即服务)是一种软件许可和交付模式,在这种模式下,软件由第三方提供商托管,并通过网络提供给用户。用户无需将软件安装在本地电脑上,可以直接通过网络访问并使用这些软件服务。
3. Stripe支付处理: Stripe是一个全面的支付平台,允许企业和个人在线接收支付。它提供了一套全面的API,允许开发者集成支付处理功能。Stripe处理包括信用卡支付、ACH转账、Apple Pay和各种其他本地支付方式。
4. Neon PostgreSQL: Neon是一个云原生的PostgreSQL服务,它提供了数据库即服务(DBaaS)的解决方案。Neon使得部署和管理PostgreSQL数据库变得更加容易和灵活。它支持高可用性配置,并提供了自动故障转移和数据备份。
5. TailwindCSS: TailwindCSS是一个实用工具优先的CSS框架,它旨在帮助开发者快速构建可定制的用户界面。它不是一个传统意义上的设计框架,而是一套工具类,允许开发者组合和自定义界面组件而不限制设计。
6. GitHub Actions: GitHub Actions是GitHub推出的一项功能,用于自动化软件开发工作流程。开发者可以在代码仓库中设置工作流程,GitHub将根据代码仓库中的事件(如推送、拉取请求等)自动执行这些工作流程。这使得持续集成和持续部署(CI/CD)变得简单而高效。
7. PostgreSQL: PostgreSQL是一个对象关系数据库管理系统(ORDBMS),它使用SQL作为查询语言。它是开源软件,可以在多种操作系统上运行。PostgreSQL以支持复杂查询、外键、触发器、视图和事务完整性等特性而著称。
8. Git: Git是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。Git由Linus Torvalds创建,旨在快速高效地处理从小型到大型项目的所有内容。Git是Django项目管理的基石,用于代码版本控制和协作开发。
通过上述知识点的结合,我们可以构建出一个具备现代Web应用程序所需所有关键特性的SaaS应用程序。Django作为后端框架负责处理业务逻辑和数据库交互,而Neon PostgreSQL提供稳定且易于管理的数据库服务。Stripe集成允许处理多种支付方式,使用户能够安全地进行交易。前端使用TailwindCSS进行快速设计,同时GitHub Actions帮助自动化部署流程,确保每次代码更新都能够顺利且快速地部署到生产环境。整体来看,这套资源涵盖了从前端到后端,再到部署和支付处理的完整链条,是构建现代SaaS应用的一套完整解决方案。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
R语言数据处理与GoogleVIS集成:一步步教你绘图
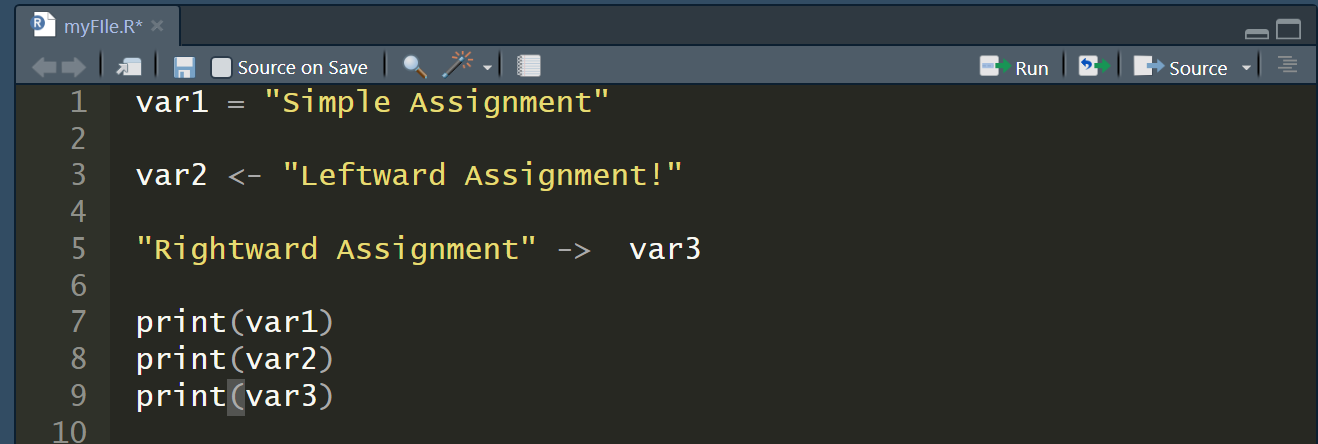
# 1. R语言数据处理基础
在数据分析领域,R语言凭借其强大的统计分析能力和灵活的数据处理功能成为了数据科学家的首选工具。本章将探讨R语言的基本数据处理流程,为后续章节中利用R语言与GoogleVIS集成进行复杂的数据可视化打下坚实的基础。
## 1.1 R语言概述
R语言是一种开源的编程语言,主要用于统计计算和图形表示。它以数据挖掘和分析为核心,拥有庞大的社区支持和丰富的第
如何使用Matlab实现PSO优化SVM进行多输出回归预测?请提供基本流程和关键步骤。
在研究机器学习和数据预测领域时,掌握如何利用Matlab实现PSO优化SVM算法进行多输出回归预测,是一个非常实用的技能。为了帮助你更好地掌握这一过程,我们推荐资源《PSO-SVM多输出回归预测与Matlab代码实现》。通过学习此资源,你可以了解到如何使用粒子群算法(PSO)来优化支持向量机(SVM)的参数,以便进行多输入多输出的回归预测。
参考资源链接:[PSO-SVM多输出回归预测与Matlab代码实现](https://wenku.csdn.net/doc/3i8iv7nbuw?spm=1055.2569.3001.10343)
首先,你需要安装Matlab环境,并熟悉其基本操作。接
Symfony2框架打造的RESTful问答系统icare-server
资源摘要信息:"icare-server是一个基于Symfony2框架开发的RESTful问答系统。Symfony2是一个使用PHP语言编写的开源框架,遵循MVC(模型-视图-控制器)设计模式。本项目完成于2014年11月18日,标志着其开发周期的结束以及初步的稳定性和可用性。"
Symfony2框架是一个成熟的PHP开发平台,它遵循最佳实践,提供了一套完整的工具和组件,用于构建可靠的、可维护的、可扩展的Web应用程序。Symfony2因其灵活性和可扩展性,成为了开发大型应用程序的首选框架之一。
RESTful API( Representational State Transfer的缩写,即表现层状态转换)是一种软件架构风格,用于构建网络应用程序。这种风格的API适用于资源的表示,符合HTTP协议的方法(GET, POST, PUT, DELETE等),并且能够被多种客户端所使用,包括Web浏览器、移动设备以及桌面应用程序。
在本项目中,icare-server作为一个问答系统,它可能具备以下功能:
1. 用户认证和授权:系统可能支持通过OAuth、JWT(JSON Web Tokens)或其他安全机制来进行用户登录和权限验证。
2. 问题的提交与管理:用户可以提交问题,其他用户或者系统管理员可以对问题进行管理,比如标记、编辑、删除等。
3. 回答的提交与管理:用户可以对问题进行回答,回答可以被其他用户投票、评论或者标记为最佳答案。
4. 分类和搜索:问题和答案可能按类别进行组织,并提供搜索功能,以便用户可以快速找到他们感兴趣的问题。
5. RESTful API接口:系统提供RESTful API,便于开发者可以通过标准的HTTP请求与问答系统进行交互,实现数据的读取、创建、更新和删除操作。
Symfony2框架对于RESTful API的开发提供了许多内置支持,例如:
- 路由(Routing):Symfony2的路由系统允许开发者定义URL模式,并将它们映射到控制器操作上。
- 请求/响应对象:处理HTTP请求和响应流,为开发RESTful服务提供标准的方法。
- 验证组件:可以用来验证传入请求的数据,并确保数据的完整性和正确性。
- 单元测试:Symfony2鼓励使用PHPUnit进行单元测试,确保RESTful服务的稳定性和可靠性。
对于使用PHP语言的开发者来说,icare-server项目的完成和开源意味着他们可以利用Symfony2框架的优势,快速构建一个功能完备的问答系统。通过学习icare-server项目的代码和文档,开发者可以更好地掌握如何构建RESTful API,并进一步提升自身在Web开发领域的专业技能。同时,该项目作为一个开源项目,其代码结构、设计模式和实现细节等都可以作为学习和实践的最佳范例。
由于icare-server项目完成于2014年,使用的技术栈可能不是最新的,因此在考虑实际应用时,开发者可能需要根据当前的技术趋势和安全要求进行相应的升级和优化。例如,PHP的版本更新可能带来新的语言特性和改进的安全措施,而Symfony2框架本身也在不断地发布新版本和更新补丁,因此维护一个长期稳定的问答系统需要开发者对技术保持持续的关注和学习。