利用Python写一篇野生菌识别
时间: 2024-02-16 08:10:43 浏览: 23
好的,我可以为您提供一个基于Python的野生菌识别的代码示例。请注意,这只是一个示例,实际的菌种识别可能需要更复杂和精细的算法和数据集。
首先,您需要一个图像处理库,例如OpenCV和SciPy。您还需要一个机器学习库,例如Scikit-learn。
以下是一个简单的示例代码,可以用于识别野生蘑菇:
```python
import cv2
import numpy as np
import scipy
from sklearn.cluster import KMeans
from sklearn.svm import SVC
# 加载野生蘑菇图像
img = cv2.imread('mushroom.jpg')
# 转换为HSV颜色空间
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# 提取色相(Hue)通道
hue = hsv[:,:,0]
# 使用K-means算法对像素点进行聚类,获取颜色特征
kmeans = KMeans(n_clusters=3, random_state=0).fit(hue.reshape(-1, 1))
colors = kmeans.cluster_centers_.astype(np.uint8)
# 计算每个像素点的颜色特征
features = np.zeros((img.shape[0], img.shape[1], colors.shape[1]), dtype=np.float32)
for i in range(colors.shape[0]):
mask = np.where(hue == colors[i])[0]
features[..., i] = np.sum(hsv.reshape(-1, 3)[mask], axis=0)
# 训练SVM分类器
X_train = features.reshape(-1, features.shape[-1])
y_train = np.zeros(X_train.shape[0], dtype=np.uint8)
y_train[:1000] = 1 # 假设前1000个样本是野生蘑菇
clf = SVC(kernel='linear', C=1.0, random_state=0).fit(X_train, y_train)
# 加载测试图像
test_img = cv2.imread('test_mushroom.jpg')
test_hsv = cv2.cvtColor(test_img, cv2.COLOR_BGR2HSV)
# 提取测试图像的颜色特征
test_features = np.zeros((test_img.shape[0], test_img.shape[1], colors.shape[1]), dtype=np.float32)
for i in range(colors.shape[0]):
mask = np.where(test_hsv[:,:,0] == colors[i])[0]
test_features[..., i] = np.sum(test_hsv.reshape(-1, 3)[mask], axis=0)
# 预测测试图像是否为野生蘑菇
X_test = test_features.reshape(-1, test_features.shape[-1])
y_pred = clf.predict(X_test)
# 输出结果
if y_pred.sum() > 0:
print('这是一种野生蘑菇')
else:
print('这不是野生蘑菇')
```
在这个示例中,我们首先将图像转换为HSV颜色空间,并提取色相(Hue)通道。然后,我们使用K-means算法对颜色进行聚类,获取颜色特征。接下来,我们计算每个像素点的颜色特征,并使用SVM分类器对野生蘑菇进行分类。最后,我们加载测试图像,并使用相同的方法提取测试图像的颜色特征,并使用训练好的分类器进行预测。
相关推荐
最新推荐
python实现基于SVM手写数字识别功能
主要为大家详细介绍了python实现基于SVM手写数字识别功能,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
手写数字识别(python底层实现)报告.docx
(1)认识MNIST数据集的数据格式,对...(2)利用python语言从零开始搭建多层感知机网络; (3) 通过调整参数提高多层感知机网络的准确度,并对实验结果进行评估; (4)程序的语句要求有注释,以增强程序可读性。
Python利用逻辑回归模型解决MNIST手写数字识别问题详解
主要介绍了Python利用逻辑回归模型解决MNIST手写数字识别问题,结合实例形式详细分析了Python MNIST手写识别问题原理及逻辑回归模型解决MNIST手写识别问题相关操作技巧,需要的朋友可以参考下
Python实现识别手写数字 Python图片读入与处理
主要为大家详细介绍了Python实现识别手写数字,Python图片的读入与处理,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
基于Python+Open CV的手势识别算法设计
手势识别在设计智能高效的人机界面方面具有至关重要的作用, 目前手势识别已应用到手语识别、智能监控、到虚拟现实等各个领域,手势识别的原理都是利用各种传感器(例如红外、摄像头等)对手部的形态进行捕捉并进行...
zigbee-cluster-library-specification
最新的zigbee-cluster-library-specification说明文档。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL数据库性能提升秘籍:揭秘性能下降幕后真凶及解决策略
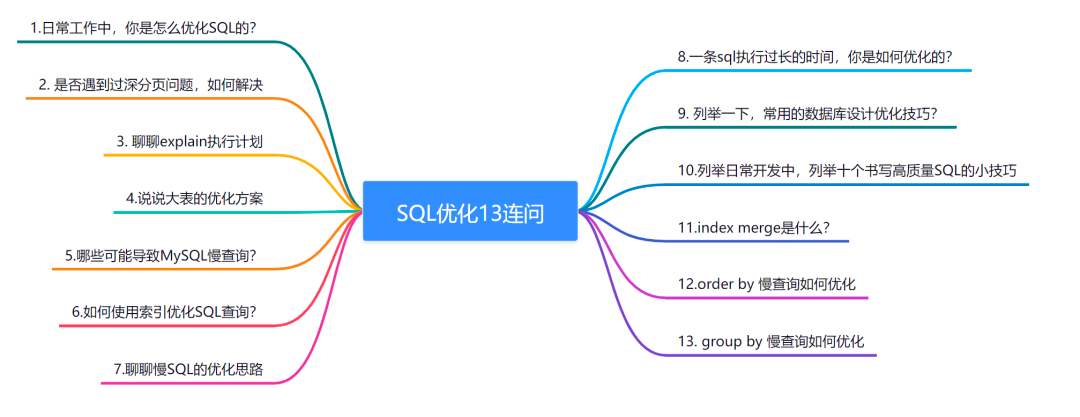
# 1. MySQL数据库性能优化概述**
MySQL数据库性能优化是一项至关重要的任务,可以显著提高应用程序的响应时间和整体用户体验。优化涉及识别和解决影响数据库性能的因素,包括硬件资源瓶颈、软件配置不当和数据库设计缺陷。通过采取适当的优化策略,可以显著提升数据库性能,满足业务需求并提高用户满意度。
# 2. MySQL数据库性能下降的幕后真凶
### 2.1 硬件资源瓶颈
#### 2.1.1 CPU利用率过高
**症状:
如何在unity创建按钮
在 Unity 中创建按钮的步骤如下:
1. 在 Unity 中创建一个 UI Canvas,选择 GameObject -> UI -> Canvas。
2. 在 Canvas 中创建一个按钮,选择 GameObject -> UI -> Button。
3. 在场景视图中调整按钮的位置和大小。
4. 在 Inspector 中设置按钮的文本、颜色、字体等属性。
5. 添加按钮的响应事件,选择按钮,在 Inspector 的 On Click () 中添加相应的方法。
这样就可以创建一个按钮了,你可以在游戏中使用它来触发相应的操作。
JSBSim Reference Manual
JSBSim参考手册,其中包含JSBSim简介,JSBSim配置文件xml的编写语法,编程手册以及一些应用实例等。其中有部分内容还没有写完,估计有生之年很难看到完整版了,但是内容还是很有参考价值的。