buffer IO不如direct IO的原因
时间: 2023-10-25 11:10:26 浏览: 59
Buffer IO和Direct IO在读写磁盘数据时有不同的优缺点。Buffer IO会将数据缓存在操作系统的内存中,使得读写速度更快,但可能会产生数据一致性的问题,因为数据可能会在应用程序和磁盘之间发生缓存不一致。而Direct IO则将数据直接读写到磁盘中,避免了数据缓存不一致的问题,但速度较慢。因此,选择采用哪种方式需根据实际场景进行权衡。
相关问题
如何使用 Java 将数据不经过系统缓存直接写入磁盘中,Direct IO
Java提供了NIO(New Input/Output)库,可以使用NIO来进行Direct IO操作,实现将数据不经过系统缓存直接写入磁盘中。
以下是实现Direct IO的步骤:
1. 使用ByteBuffer类创建一个缓冲区对象。该类提供了allocateDirect()方法来创建直接缓冲区,这个缓冲区不会被JVM管理,而是由操作系统管理。
2. 打开文件通道。通过FileChannel类的open()方法打开文件通道,可以使用通道进行读写操作。
3. 将数据写入缓冲区。使用put()方法将数据写入缓冲区。
4. 将缓冲区的数据写入文件通道。使用FileChannel类的write()方法将缓冲区的数据写入文件通道。
5. 关闭通道和缓冲区。使用close()方法关闭通道和缓冲区。
以下是一个示例代码:
```
import java.io.File;
import java.io.FileOutputStream;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class DirectIOTest {
public static void main(String[] args) {
String filePath = "test.txt";
int bufferSize = 1024 * 1024; //1MB
try {
//创建直接缓冲区
ByteBuffer buffer = ByteBuffer.allocateDirect(bufferSize);
//打开文件通道
FileChannel channel = new FileOutputStream(new File(filePath)).getChannel();
//将数据写入缓冲区
buffer.put("Hello, Direct IO!".getBytes());
//将缓冲区的数据写入文件通道
buffer.flip();
channel.write(buffer);
//关闭通道和缓冲区
channel.close();
buffer.clear();
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
在上述代码中,通过ByteBuffer类的allocateDirect()方法创建了一个1MB的直接缓冲区,使用FileChannel类的open()方法打开文件通道并将数据写入缓冲区,最后将缓冲区的数据写入文件通道。在操作完成后,通过close()方法关闭通道和缓冲区。
rk3588 使用 pcie3.0 4通道 并发多个并行IO请求应用程序编写
下面是一个使用RK3588的PCIe 3.0的4个通道并发多个并行IO请求的应用程序的示例:
```c++
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <fcntl.h>
#include <unistd.h>
#define NUM_THREADS 4 // 线程数
#define IO_SIZE 4096 // 每个IO请求的大小
#define NUM_IO_REQUESTS 8 // 每个线程的IO请求数
void* io_thread(void* arg)
{
int fd = open("/dev/nvme0n1", O_RDWR | O_DIRECT); // 打开设备节点
if (fd < 0)
{
perror("open");
exit(1);
}
char* buffer = aligned_alloc(4096, IO_SIZE); // 分配对齐的缓冲区
if (!buffer)
{
perror("aligned_alloc");
exit(1);
}
for (int i = 0; i < NUM_IO_REQUESTS; i++)
{
// 发送IO请求
ssize_t ret = pread(fd, buffer, IO_SIZE, i * IO_SIZE);
if (ret < 0)
{
perror("pread");
exit(1);
}
}
free(buffer); // 释放缓冲区
close(fd); // 关闭设备节点
pthread_exit(NULL);
}
int main()
{
pthread_t threads[NUM_THREADS];
int rc;
long t;
for (t = 0; t < NUM_THREADS; t++)
{
rc = pthread_create(&threads[t], NULL, io_thread, (void*)t);
if (rc)
{
printf("ERROR; return code from pthread_create() is %d\n", rc);
exit(1);
}
}
pthread_exit(NULL);
}
```
这个程序使用了4个线程,并发地发送每个线程8个IO请求,每个IO请求的大小为4KB。其中,打开的设备节点为"/dev/nvme0n1",可以根据实际情况进行修改。每个线程的IO请求会分别发送到4个通道中,以充分利用PCIe3.0的4个通道并发传输的能力。需要注意的是,这只是一个简单的示例程序,具体实现需要根据实际情况进行调整和优化。
相关推荐
最新推荐
Ubuntu硬盘FIO测试操作规范
* direct=1:测试过程绕过机器自带的 buffer,使测试结果更真实。 * rw=randread:测试随机读的 I/O;rw=randwrite:测试随机写的 I/O;rw=read:测试顺序读的 I/O;rw=write:测试顺序写的 I/O。 * ioengine=libaio...
Java软件开发实战 Java基础与案例开发详解 19-7 综合示例 共10页.pdf
完整版:https://download.csdn.net/download/qq_27595745/89522468
【课程大纲】
1-1 什么是java
1-2 认识java语言
1-3 java平台的体系结构
1-4 java SE环境安装和配置
2-1 java程序简介
2-2 计算机中的程序
2-3 java程序
2-4 java类库组织结构和文档
2-5 java虚拟机简介
2-6 java的垃圾回收器
2-7 java上机练习
3-1 java语言基础入门
3-2 数据的分类
3-3 标识符、关键字和常量
3-4 运算符
3-5 表达式
3-6 顺序结构和选择结构
3-7 循环语句
3-8 跳转语句
3-9 MyEclipse工具介绍
3-10 java基础知识章节练习
4-1 一维数组
4-2 数组应用
4-3 多维数组
4-4 排序算法
4-5 增强for循环
4-6 数组和排序算法章节练习
5-0 抽象和封装
5-1 面向过程的设计思想
5-2 面向对象的设计思想
5-3 抽象
5-4 封装
5-5 属性
5-6 方法的定义
5-7 this关键字
5-8 javaBean
5-9 包 package
5-10 抽象和封装章节练习
6-0 继承和多态
6-1 继承
6-2 object类
6-3 多态
6-4 访问修饰符
6-5 static修饰符
6-6 final修饰符
6-7 abstract修饰符
6-8 接口
6-9 继承和多态 章节练习
7-1 面向对象的分析与设计简介
7-2 对象模型建立
7-3 类之间的关系
7-4 软件的可维护与复用设计原则
7-5 面向对象的设计与分析 章节练习
8-1 内部类与包装器
8-2 对象包装器
8-3 装箱和拆箱
8-4 练习题
9-1 常用类介绍
9-2 StringBuffer和String Builder类
9-3 Rintime类的使用
9-4 日期类简介
9-5 java程序国际化的实现
9-6 Random类和Math类
9-7 枚举
9-8 练习题
10-1 java异常处理
10-2 认识异常
10-3 使用try和catch捕获异常
10-4 使用throw和throws引发异常
10-5 finally关键字
10-6 getMessage和printStackTrace方法
10-7 异常分类
10-8 自定义异常类
10-9 练习题
11-1 Java集合框架和泛型机制
11-2 Collection接口
11-3 Set接口实现类
11-4 List接口实现类
11-5 Map接口
11-6 Collections类
11-7 泛型概述
11-8 练习题
12-1 多线程
12-2 线程的生命周期
12-3 线程的调度和优先级
12-4 线程的同步
12-5 集合类的同步问题
12-6 用Timer类调度任务
12-7 练习题
13-1 Java IO
13-2 Java IO原理
13-3 流类的结构
13-4 文件流
13-5 缓冲流
13-6 转换流
13-7 数据流
13-8 打印流
13-9 对象流
13-10 随机存取文件流
13-11 zip文件流
13-12 练习题
14-1 图形用户界面设计
14-2 事件处理机制
14-3 AWT常用组件
14-4 swing简介
14-5 可视化开发swing组件
14-6 声音的播放和处理
14-7 2D图形的绘制
14-8 练习题
15-1 反射
15-2 使用Java反射机制
15-3 反射与动态代理
15-4 练习题
16-1 Java标注
16-2 JDK内置的基本标注类型
16-3 自定义标注类型
16-4 对标注进行标注
16-5 利用反射获取标注信息
16-6 练习题
17-1 顶目实战1-单机版五子棋游戏
17-2 总体设计
17-3 代码实现
17-4 程序的运行与发布
17-5 手动生成可执行JAR文件
17-6 练习题
18-1 Java数据库编程
18-2 JDBC类和接口
18-3 JDBC操作SQL
18-4 JDBC基本示例
18-5 JDBC应用示例
18-6 练习题
19-1 。。。
100款古风PPT (60)(1).pptx
【ppt素材】工作总结、商业计划书、述职报告、读书分享、家长会、主题班会、端午节、期末、夏至、中国风、卡通、小清新、岗位竞聘、公司介绍、读书分享、安全教育、文明礼仪、儿童故事、绘本、防溺水、夏季安全、科技风、商务、炫酷、企业培训、自我介绍、产品介绍、师德师风、班主任培训、神话故事、巴黎奥运会、世界献血者日、防范非法集资、3D快闪、毛玻璃、人工智能等等各种样式的ppt素材风格。
设计模板、图片素材、PPT模板、视频素材、办公文档、小报模板、表格模板、音效配乐、字体库。
广告设计:海报,易拉宝,展板,宣传单,宣传栏,画册,邀请函,优惠券,贺卡,文化墙,标语,制度,名片,舞台背景,广告牌,证书,明信片,菜单,折页,封面,节目单,门头,美陈,拱门,展架等。
电商设计:主图,直通车,详情页,PC端首页,移动端首页,钻展,优惠券,促销标签,店招,店铺公告等。
图片素材:PNG素材,背景素材,矢量素材,插画,元素,艺术字,UI设计等。
视频素材:AE模板,会声会影,PR模板,视频背景,实拍短片,音效配乐。
办公文档:工作汇报,毕业答辩,企业介绍,总结计划,教学课件,求职简历等PPT/WORD模板。
DS18B20 - 数字温度传感器
DS18B20是一种数字温度传感器,被广泛应用于各种温度监测和控制系统中。它基于单总线协议,具有数字输出和高精度的温度测量能力。以下是对DS18B20的详细介绍:
DS18B20采用了数字温度传感器技术,可以准确测量环境温度并将结果以数字形式输出。它的工作原理基于温度导致的半导体材料电阻值的变化。DS18B20内部集成了温度传感器、模数转换器和单总线接口电路,使得它在一个小型封装中实现了高度集成和功能完整性。
DS18B20的特点之一是其数字输出和单总线接口。它使用单总线协议进行通信,只需要一条数据线连接到主控设备,简化了连接和布线。通过发送特定的指令和接收传感器的响应,主控设备可以读取温度值并进行相应的处理和控制操作。
DS18B20具有高精度的温度测量能力。它可以在范围从-55°C到+125°C内测量温度,并具有0.5°C的温度分辨率。此外,它还具有温度报警功能,可以在温度达到预设阈值时触发警报,提供温度监测和控制的实时反馈。
DS18B20在各种应用中都得到了广泛应用。它适用于温度监测和控制系统,如室内温度监测、恒温控制、温度报警系统等。它还可以用于工业自动化、气象站、电
si2302中文资料-数据手册-参数.pdf
对MOS的应用和参数做了详细的说明附带测试数据
图书馆管理系统数据库设计与功能详解
"图书馆管理系统数据库设计.pdf"
图书馆管理系统数据库设计是一项至关重要的任务,它涉及到图书信息、读者信息、图书流通等多个方面。在这个系统中,数据库的设计需要满足各种功能需求,以确保图书馆的日常运营顺畅。
首先,系统的核心是安全性管理。为了保护数据的安全,系统需要设立权限控制,允许管理员通过用户名和密码登录。管理员具有全面的操作权限,包括添加、删除、查询和修改图书信息、读者信息,处理图书的借出、归还、逾期还书和图书注销等事务。而普通读者则只能进行查询操作,查看个人信息和图书信息,但不能进行修改。
读者信息管理模块是另一个关键部分,它包括读者类型设定和读者档案管理。读者类型设定允许管理员定义不同类型的读者,比如学生、教师,设定他们可借阅的册数和续借次数。读者档案管理则存储读者的基本信息,如编号、姓名、性别、联系方式、注册日期、有效期限、违规次数和当前借阅图书的数量。此外,系统还包括了借书证的挂失与恢复功能,以防止丢失后图书的不当借用。
图书管理模块则涉及图书的整个生命周期,从基本信息设置、档案管理到征订、注销和盘点。图书基本信息设置包括了ISBN、书名、版次、类型、作者、出版社、价格、现存量和库存总量等详细信息。图书档案管理记录图书的入库时间,而图书征订用于订购新的图书,需要输入征订编号、ISBN、订购数量和日期。图书注销功能处理不再流通的图书,这些图书的信息会被更新,不再可供借阅。图书查看功能允许用户快速查找特定图书的状态,而图书盘点则是为了定期核对库存,确保数据准确。
图书流通管理模块是系统中最活跃的部分,它处理图书的借出和归还流程,包括借阅、续借、逾期处理等功能。这个模块确保了图书的流通有序,同时通过记录借阅历史,方便读者查询自己的借阅情况和超期还书警告。
图书馆管理系统数据库设计是一个综合性的项目,涵盖了用户认证、信息管理、图书操作和流通跟踪等多个层面,旨在提供高效、安全的图书服务。设计时需要考虑到系统的扩展性、数据的一致性和安全性,以满足不同图书馆的具体需求。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
表锁问题全解析:深度解读,轻松解决
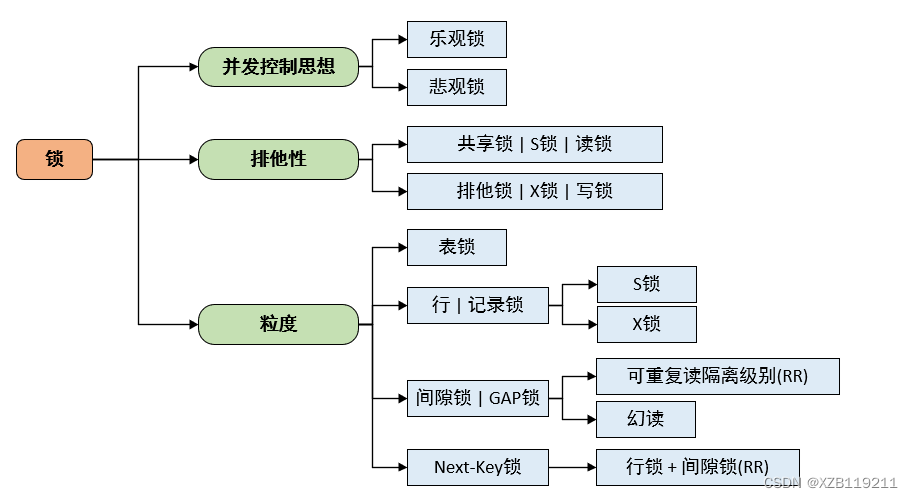
# 1. 表锁基础**
表锁是一种数据库并发控制机制,用于防止多个事务同时修改同一行或表,从而保证数据的一致性和完整性。表锁的工作原理是通过在表或行上设置锁,当一个事务需要访问被锁定的数据时,它必须等待锁被释放。
表锁分为两种类型:行锁和表锁。行锁只锁定被访问的行,而表锁锁定整个表。行锁的粒度更细,可以提高并发性,但开销也更大。表锁的粒度更粗,开销较小,但并发性较低。
表锁还分为共享锁和排他锁。共享锁允许多个事务同时
麻雀搜索算法SSA优化卷积神经网络CNN
麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种生物启发式的优化算法,它模拟了麻雀觅食的行为,用于解决复杂的优化问题,包括在深度学习中调整神经网络参数以提高性能。在卷积神经网络(Convolutional Neural Networks, CNN)中,SSA作为一种全局优化方法,可以应用于网络架构搜索、超参数调优等领域。
在CNN的优化中,SSA通常会:
1. **构建种群**:初始化一组随机的CNN结构或参数作为“麻雀”个体。
2. **评估适应度**:根据每个网络在特定数据集上的性能(如验证集上的精度或损失)来评估其适应度。
3. **觅食行为**:模仿
***物流有限公司仓储配送业务SOP详解
"该文档是***物流有限公司的仓储配送业务SOP管理程序,包含了工作职责、操作流程、各个流程的详细步骤,旨在规范公司的仓储配送管理工作,提高效率和准确性。"
在物流行业中,标准操作程序(SOP)是确保业务流程高效、一致和合规的关键。以下是对文件中涉及的主要知识点的详细解释:
1. **工作职责**:明确各岗位人员的工作职责和责任范围,是确保业务流程顺畅的基础。例如,配送中心主管负责日常业务管理、费用控制、流程监督和改进;发运管理员处理运输调配、计划制定、5S管理;仓管员负责货物的收发存管理、质量控制和5S执行;客户服务员则处理客户指令、运营单据和物流数据管理。
2. **操作流程**:文件详细列出了各项操作流程,包括**入库及出库配送流程**,强调了从接收到发货的完整过程,包括验收、登记、存储、拣选、包装、出库等环节,确保货物的安全和准确性。
3. **仓库装卸作业流程**:详细规定了货物装卸的操作步骤,包括使用设备、安全措施、作业标准,以防止货物损坏并提高作业效率。
4. **货物在途跟踪及异常情况处理流程**:描述了如何监控货物在运输途中的状态,以及遇到异常如延误、丢失或损坏时的应对措施,确保货物安全并及时处理问题。
5. **单据流转及保管流程**:规定了从订单创建到完成的单据处理流程,包括记录、审核、传递和存档,以保持信息的准确性和可追溯性。
6. **存货管理**:涵盖了库存控制策略,如先进先出(FIFO)、定期盘点、库存水平的优化,以避免过度库存或缺货。
7. **仓库标志流程**:明确了仓库内的标识系统,帮助员工快速定位货物,提高作业效率。
8. **仓库5S管理及巡检流程**:5S(整理、整顿、清扫、清洁、素养)是提高仓库环境和工作效率的重要工具,巡检流程则确保了5S的持续实施。
9. **仓库建筑设备设施的维护流程**:强调了设备设施的定期检查、保养和维修,以保证其正常运行,避免因设备故障导致的运营中断。
10. **附件清单**:列出所有相关的附件和表格,便于员工参考和执行。
通过这些详尽的SOP,***物流有限公司能够系统化地管理仓储配送业务,确保服务质量,减少错误,提升客户满意度,并为公司的持续改进提供基础。