yolov7各个模型解读
时间: 2024-11-05 11:11:26 浏览: 73
YOLOv7(You Only Look Once Version 7)是YOLO(You Only Look Once)系列的最新版本,它是一个实时物体检测算法。YOLO系列以其快速的速度和相对较高的准确度而闻名,Yolov7进一步提升了性能:
1. **网络结构**:Yolov7采用了一种更大规模、更深的Darknet架构,包括更多的残差连接(Residual Connections),以及更多的卷积层,这有助于捕获更复杂的图像特征。
2. **主干网络**:它通常基于 CSPDarknet53(Cross Stage Partial Network)或者更大的版本,如CSPDarknet63,这种设计允许在保持计算效率的同时提高精度。
3. **分块检测**(SPP Blocks):YOLOv7包含空间金字塔池化(Spatial Pyramid Pooling)模块,用于处理不同尺度的目标,提高了对目标大小变化的适应性。
4. **多尺度预测**:通过引入不同大小的anchor boxes(先验框)和特征图,YOLOv7可以在不同分辨率下同时进行预测,增强了检测性能。
5. **Mosaic数据增强**:这是一种训练数据增强技术,将四个小图片拼接成大图,增加了模型对于真实世界场景多样性的理解。
6. **Focal Loss优化**:类似RetinaNet的Focal Loss,降低了正负样本不平衡带来的影响,有助于提升小型和难以区分的目标检测。
**相关问题--:**
1. YOLOv7相比前代有哪些显著改进?
2. 它如何处理目标遮挡的问题?
3. 在实际应用中,YOLOv7的性能如何与其他知名算法如SSD或R-CNN比较?
阅读全文
相关推荐
大家在看
alertmanager-0.19.0.linux-amd64.tar.gz
prometheus的alermanager报警组件
5G分组核心网专题.pptx
5G分组核心网专题
LTE Signaling & Protocol Analysis Focus: E-UTRAN and UE
非常不错,采用问答的方式来学习LTE和EPC,本章主要关注于UE和RAN部分。
This eBook is a must for everybody who requires a detailed understanding of the protocols and signaling procedures within E-UTRAN and the EPC. In that respect the clear focus of this course is on the protocols of the UE and the E-UTRAN.
The eBook starts with a review of the LTE physical layer and the concepts and protocol stacks of E-UTRAN.
This part concludes with the review of the EPS network architecture.
Immediately afterwards we jump into real-life call flows and scenarios and confront the student with the look & feel of the LTE protocol suite. This part ends with an assessment of what will be the focus of the following chapters.
The next chapters are dedicated to the different protocols EMM, ESM, MAC, RLC, RRC, S1-AP, X2-AP, SGs-AP and S101-AP.
The eBook concludes with the presentation and analysis of LTE signaling flows and real-life call flows.
r3epthook-master.zip
VT ept进行hook,可以隐藏hook
LITE-ON FW spec PS-2801-9L rev A01_20161118.pdf
LITE-ON FW spec PS-2801-9L
最新推荐
燃料电池汽车Cruise整车仿真模型(燃料电池电电混动整车仿真模型) 1.基于Cruise与MATLAB Simulink联合仿真完成整个模型搭建,策略为多点恒功率(多点功率跟随)式控制策略,策略模
燃料电池汽车Cruise整车仿真模型(燃料电池电电混动整车仿真模型)。
1.基于Cruise与MATLAB Simulink联合仿真完成整个模型搭建,策略为多点恒功率(多点功率跟随)式控制策略,策略模型具备燃料电池系统电堆控制,电机驱动,再生制动等功能,实现燃料电池车辆全部工作模式,基于项目开发,策略准确;
2.模型物超所值,Cruise模型与Simulink策略有不懂的随时交流;
注:请确定是否需要再买,这种技术类文件出一概不 ;附赠Cruise与Simulink联合仿真的方法心得体会(大概十几页)。
并列关系-关系图表-鲜艳红色 -3.pptx
图表分类ppt
实际项目中三菱fx5u编写的中型程序,用了st fbd ld 混合编程,程序内容完整,控制十来个轴 ,结构清晰 ,用到了结构体,全局变量 ,适合进阶学习
实际项目中三菱fx5u编写的中型程序,用了st fbd ld 混合编程,程序内容完整,控制十来个轴 ,结构清晰 ,用到了结构体,全局变量 ,适合进阶学习
并列关系-关系图表-简约折纸-3.pptx
图表分类ppt
甘特图-商业图表-稳重色彩 3.pptx
图表分类ppt
租赁合同编写指南及下载资源
资源摘要信息:《租赁合同》是用于明确出租方与承租方之间的权利和义务关系的法律文件。在实际操作中,一份详尽的租赁合同对于保障交易双方的权益至关重要。租赁合同应当包括但不限于以下要点:
1. 双方基本信息:租赁合同中应明确出租方(房东)和承租方(租客)的名称、地址、联系方式等基本信息。这对于日后可能出现的联系、通知或法律诉讼具有重要意义。
2. 房屋信息:合同中需要详细说明所租赁的房屋的具体信息,包括房屋的位置、面积、结构、用途、设备和家具清单等。这些信息有助于双方对租赁物有清晰的认识。
3. 租赁期限:合同应明确租赁开始和结束的日期,以及租期的长短。租赁期限的约定关系到租金的支付和合同的终止条件。
4. 租金和押金:租金条款应包括租金金额、支付周期、支付方式及押金的数额。同时,应明确规定逾期支付租金的处理方式,以及押金的退还条件和时间。
5. 维修与保养:在租赁期间,房屋的维护和保养责任应明确划分。通常情况下,房东负责房屋的结构和主要设施维修,而租客需负责日常维护及保持房屋的清洁。
6. 使用与限制:合同应规定承租方可以如何使用房屋以及可能的限制。例如,禁止非法用途、允许或禁止宠物、是否可以转租等。
7. 终止与续租:租赁合同应包括租赁关系的解除条件,如提前通知时间、违约责任等。同时,双方可以在合同中约定是否可以续租,以及续租的条件。
8. 解决争议的条款:合同中应明确解决可能出现的争议的途径,包括适用法律、管辖法院等,有助于日后纠纷的快速解决。
9. 其他可能需要的条款:根据具体情况,合同中可能还需要包括关于房屋保险、税费承担、合同变更等内容。
下载资源链接:【下载自www.glzy8.com管理资源吧】Rental contract.DOC
该资源为一份租赁合同模板,对需要进行房屋租赁的个人或机构提供了参考价值。通过对合同条款的详细列举和解释,该文档有助于用户了解和制定自己的租赁合同,从而在房屋租赁交易中更好地保护自己的权益。感兴趣的用户可以通过提供的链接下载文档以获得更深入的了解和实际操作指导。
【项目管理精英必备】:信息系统项目管理师教程习题深度解析(第四版官方教材全面攻略)
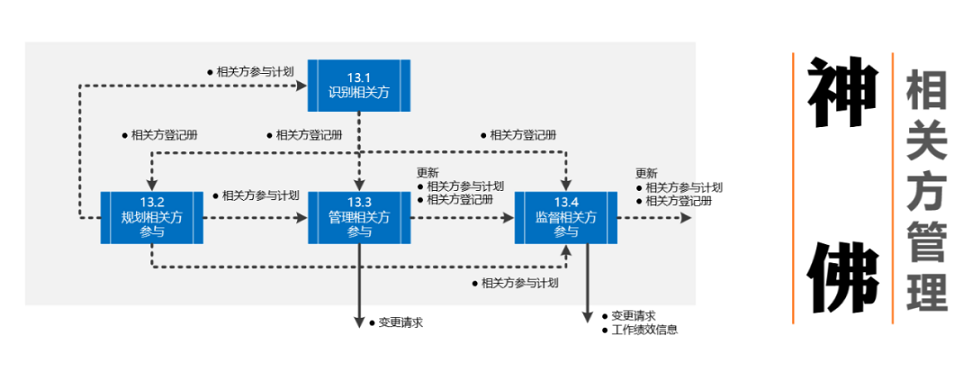
# 摘要
信息系统项目管理是确保项目成功交付的关键活动,涉及一系列管理过程和知识领域。本文深入探讨了信息系统项目管理的各个方面,包括项目管理过程组、知识领域、实践案例、管理工具与技术,以及沟通和团队协作。通过分析不同的项目管理方法论(如瀑布、迭代、敏捷和混合模型),并结合具体案例,文章阐述了项目管理的最佳实践和策略。此外,本文还涵盖了项目管理中的沟通管理、团队协作的重要性,
最具代表性的改进过的UNet有哪些?
UNet是一种广泛用于图像分割任务的卷积神经网络结构,它的特点是结合了下采样(编码器部分)和上采样(解码器部分),能够保留细节并生成精确的边界。为了提高性能和适应特定领域的需求,研究者们对原始UNet做了许多改进,以下是几个最具代表性的变种:
1. **DeepLab**系列:由Google开发,通过引入空洞卷积(Atrous Convolution)、全局平均池化(Global Average Pooling)等技术,显著提升了分辨率并保持了特征的多样性。
2. **SegNet**:采用反向传播的方式生成全尺寸的预测图,通过上下采样过程实现了高效的像素级定位。
3. **U-Net+
惠普P1020Plus驱动下载:办公打印新选择
资源摘要信息: "最新惠普P1020Plus官方驱动"
1. 惠普 LaserJet P1020 Plus 激光打印机概述:
惠普 LaserJet P1020 Plus 是惠普公司针对家庭、个人办公以及小型办公室(SOHO)市场推出的一款激光打印机。这款打印机的设计注重小巧体积和便携操作,适合空间有限的工作环境。其紧凑的设计和高效率的打印性能使其成为小型企业或个人用户的理想选择。
2. 技术特点与性能:
- 预热技术:惠普 LaserJet P1020 Plus 使用了0秒预热技术,能够极大减少打印第一张页面所需的等待时间,首页输出时间不到10秒。
- 打印速度:该打印机的打印速度为每分钟14页,适合处理中等规模的打印任务。
- 月打印负荷:月打印负荷高达5000页,保证了在高打印需求下依然能稳定工作。
- 标配硒鼓:标配的2000页打印硒鼓能够为用户提供较长的使用周期,减少了更换耗材的频率,节约了长期使用成本。
3. 系统兼容性:
驱动程序支持的操作系统包括 Windows Vista 64位版本。用户在使用前需要确保自己的操作系统版本与驱动程序兼容,以保证打印机的正常工作。
4. 市场表现:
惠普 LaserJet P1020 Plus 在上市之初便获得了市场的广泛认可,创下了百万销量的辉煌成绩,这在一定程度上证明了其可靠性和用户对其性能的满意。
5. 驱动程序文件信息:
压缩包内包含了适用于该打印机的官方驱动程序文件 "lj1018_1020_1022-HB-pnp-win64-sc.exe"。该文件是安装打印机驱动的执行程序,用户需要下载并运行该程序来安装驱动。
另一个文件 "jb51.net.txt" 从命名上来看可能是一个文本文件,通常这类文件包含了关于驱动程序的安装说明、版本信息或是版权信息等。由于具体内容未提供,无法确定确切的信息。
6. 使用场景:
由于惠普 LaserJet P1020 Plus 的打印速度和负荷能力,它适合那些需要快速、频繁打印文档的用户,例如行政助理、会计或小型法律事务所。它的紧凑设计也使得这款打印机非常适合在桌面上使用,从而不占用过多的办公空间。
7. 后续支持与维护:
用户在购买后可以通过惠普官方网站获取最新的打印机驱动更新以及技术支持。在安装新驱动之前,建议用户先卸载旧的驱动程序,以避免版本冲突或不必要的错误。
8. 其它注意事项:
- 用户在使用打印机时应注意按照官方提供的维护说明定期进行清洁和保养,以确保打印质量和打印机的使用寿命。
- 如果在打印过程中遇到任何问题,应先检查打印机设置、驱动程序是否正确安装以及是否有足够的打印纸张和墨粉。
综上所述,惠普 LaserJet P1020 Plus 是一款性能可靠、易于使用的激光打印机,特别适合小型企业或个人用户。正确的安装和维护可以确保其稳定和高效的打印能力,满足日常办公需求。
数字电路实验技巧:10大策略,让你的实验效率倍增!
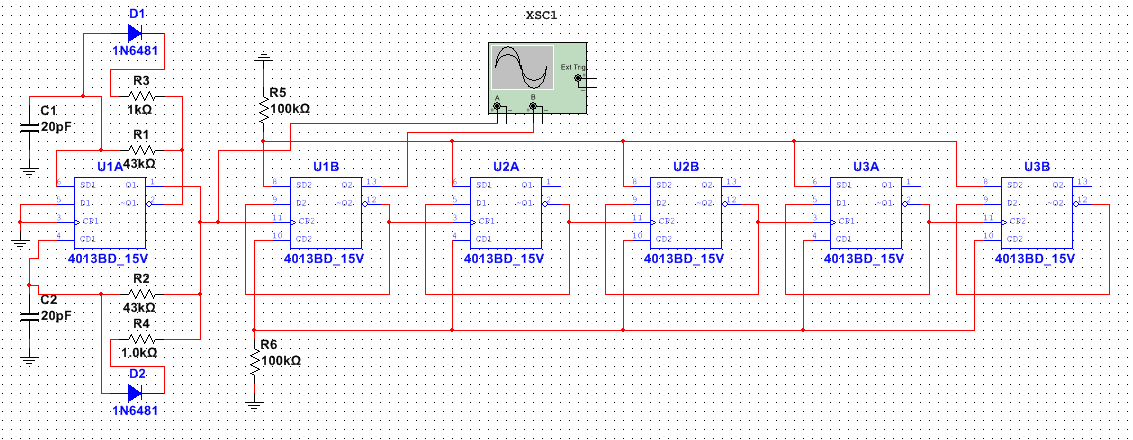
# 摘要
本论文详细介绍了数字电路实验的基础理论、设备使用、设计原则、实践操作、调试与故障排除以及报告撰写与成果展示。首先探讨了数字电路实验所需的基本理论和实验设备的种类与使用技巧,包括测量和故障诊断方法。接着,深入分析了电路设计的原则,涵盖设计流程、逻辑简化、优化策略及实验方案的制定。在实践操作章节中,具体