任意输入四个字符,求其中最小字符并输出 c语言格式
时间: 2024-05-22 21:16:15 浏览: 74
#include <stdio.h>
#include <ctype.h>
int main() {
char c1, c2, c3, c4;
printf("请输入四个字符:\n");
scanf("%c %c %c %c", &c1, &c2, &c3, &c4);
char min_char = c1;
if (c2 < min_char) {
min_char = c2;
}
if (c3 < min_char) {
min_char = c3;
}
if (c4 < min_char) {
min_char = c4;
}
printf("最小字符是:%c\n", tolower(min_char));
return 0;
}
相关问题
利用C语言编写一个完整代码。具体要求为:从键盘任意输入一个带空格由英文字母构成的文本字符串,例如“ilikelearningdatastructurecourse”,首先根据该字符串创建Huffman树,之后进行Huffman编码,然后把该字符串的Huffman编码结果向屏幕输出。能够利用前述的Huffman编码结果对某0-1码流进行解码得到字符串,并作出详细注释
以下是实现以上功能的完整代码,我会尽量详细注释,以方便您理解。
```c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
/* 定义二叉树节点结构体 */
typedef struct TreeNode {
char data; /* 节点存储的字符 */
int weight; /* 节点权重(出现次数) */
struct TreeNode *left; /* 左子节点 */
struct TreeNode *right; /* 右子节点 */
} TreeNode;
/* 定义哈夫曼树结构体 */
typedef struct HuffmanTree {
TreeNode *root; /* 根节点 */
} HuffmanTree;
/* 哈夫曼编码表结构体 */
typedef struct HuffmanCode {
char data; /* 字符 */
char *code; /* 编码 */
struct HuffmanCode *next; /* 指向下一个编码表节点的指针 */
} HuffmanCode;
/* 定义哈夫曼编码表链表结构体 */
typedef struct HuffmanCodeList {
HuffmanCode *head; /* 头节点指针 */
HuffmanCode *tail; /* 尾节点指针 */
} HuffmanCodeList;
/* 创建一个新的二叉树节点 */
TreeNode *newNode(char data, int weight) {
TreeNode *node = (TreeNode*)malloc(sizeof(TreeNode));
node->data = data;
node->weight = weight;
node->left = NULL;
node->right = NULL;
return node;
}
/* 按照节点权重从小到大排序的比较函数 */
int cmp(const void *a, const void *b) {
TreeNode **pa = (TreeNode**)a;
TreeNode **pb = (TreeNode**)b;
return (*pa)->weight - (*pb)->weight;
}
/* 从文本字符串中创建哈夫曼树 */
HuffmanTree *createHuffmanTree(char *str) {
int len = strlen(str);
int count[26] = {0}; /* 统计每个字母出现的次数 */
for (int i = 0; i < len; i++) {
if (isalpha(str[i])) {
count[str[i] - 'a']++;
}
}
/* 将每个出现过的字母作为一个节点,构成森林 */
TreeNode *forest[26];
int forestSize = 0;
for (int i = 0; i < 26; i++) {
if (count[i] > 0) {
forest[forestSize++] = newNode(i + 'a', count[i]);
}
}
/* 不断将森林中的节点合并,直到只剩下一棵树为止 */
while (forestSize > 1) {
/* 找到森林中权重最小的两个节点 */
qsort(forest, forestSize, sizeof(TreeNode*), cmp);
TreeNode *left = forest[0];
TreeNode *right = forest[1];
/* 创建一个新的节点,作为这两个节点的父节点 */
TreeNode *parent = newNode('\0', left->weight + right->weight);
parent->left = left;
parent->right = right;
/* 将这个新的节点加入森林中 */
forest[0] = parent;
for (int i = 1; i < forestSize - 1; i++) {
forest[i] = forest[i + 1];
}
forestSize--;
}
/* 最后剩下的这棵树即为哈夫曼树 */
HuffmanTree *tree = (HuffmanTree*)malloc(sizeof(HuffmanTree));
tree->root = forest[0];
return tree;
}
/* 递归生成哈夫曼编码表 */
void generateHuffmanCodeList(TreeNode *node, HuffmanCodeList *list, char *code, int depth) {
if (node == NULL) {
return;
}
/* 当前节点是叶子节点,将它的字符和编码加入编码表中 */
if (node->left == NULL && node->right == NULL) {
HuffmanCode *huffmanCode = (HuffmanCode*)malloc(sizeof(HuffmanCode));
huffmanCode->data = node->data;
huffmanCode->code = (char*)malloc(sizeof(char) * (depth + 1));
huffmanCode->code[depth] = '\0';
strncpy(huffmanCode->code, code, depth);
if (list->head == NULL) {
list->head = huffmanCode;
list->tail = huffmanCode;
} else {
list->tail->next = huffmanCode;
list->tail = huffmanCode;
}
}
/* 分别处理左子树和右子树 */
code[depth] = '0';
generateHuffmanCodeList(node->left, list, code, depth + 1);
code[depth] = '1';
generateHuffmanCodeList(node->right, list, code, depth + 1);
}
/* 生成哈夫曼编码表 */
HuffmanCodeList *generateHuffmanCode(HuffmanTree *tree) {
char code[26] = {0};
HuffmanCodeList *list = (HuffmanCodeList*)malloc(sizeof(HuffmanCodeList));
list->head = NULL;
list->tail = NULL;
generateHuffmanCodeList(tree->root, list, code, 0);
return list;
}
/* 根据哈夫曼编码表,将文本字符串编码为一个0-1串 */
char *encode(HuffmanCodeList *list, char *str) {
int len = strlen(str);
int codeLen = 0;
char *code = (char*)malloc(sizeof(char) * (len * 10)); /* 最多需要10倍的空间 */
code[0] = '\0';
for (int i = 0; i < len; i++) {
if (isalpha(str[i])) {
/* 在编码表中查找当前字符的编码 */
HuffmanCode *huffmanCode = list->head;
while (huffmanCode != NULL && huffmanCode->data != str[i]) {
huffmanCode = huffmanCode->next;
}
if (huffmanCode != NULL) {
/* 将编码拼接到0-1串中 */
strcat(code, huffmanCode->code);
codeLen += strlen(huffmanCode->code);
}
}
}
/* 将0-1串的长度写在字符串的前四个字节中 */
char *result = (char*)malloc(sizeof(char) * (codeLen / 8 + 5));
result[0] = codeLen >> 24 & 0xff;
result[1] = codeLen >> 16 & 0xff;
result[2] = codeLen >> 8 & 0xff;
result[3] = codeLen & 0xff;
for (int i = 0; i < codeLen; i += 8) {
char byte = 0;
for (int j = 0; j < 8; j++) {
byte <<= 1;
if (code[i + j] == '1') {
byte |= 1;
}
}
result[i / 8 + 4] = byte;
}
result[codeLen / 8 + 4] = '\0';
free(code);
return result;
}
/* 根据哈夫曼编码表,将0-1串解码为文本字符串 */
char *decode(HuffmanCodeList *list, char *code) {
int len = (code[0] << 24) | (code[1] << 16) | (code[2] << 8) | code[3];
char *str = (char*)malloc(sizeof(char) * (len + 1));
int pos = 4;
int strPos = 0;
while (pos < (len + 4) / 8 + 4) {
/* 将一个字节拆分为8个二进制位 */
char byte = code[pos++];
for (int i = 7; i >= 0 && strPos < len; i--) {
int bit = (byte >> i) & 1;
/* 在编码表中查找当前0-1子串对应的字符 */
HuffmanCode *huffmanCode = list->head;
while (huffmanCode != NULL && strlen(huffmanCode->code) <= strPos && strncmp(huffmanCode->code, str + strPos - strlen(huffmanCode->code), strlen(huffmanCode->code)) != 0) {
huffmanCode = huffmanCode->next;
}
if (huffmanCode != NULL && strlen(huffmanCode->code) > strPos && huffmanCode->code[strPos] == '0' + bit) {
/* 匹配成功 */
str[strPos++] = huffmanCode->data;
} else {
/* 匹配失败 */
i++;
}
}
}
str[len] = '\0';
return str;
}
int main() {
char str[1000];
printf("请输入一个带空格由英文字母构成的文本字符串:\n");
fgets(str, sizeof(str), stdin);
str[strlen(str) - 1] = '\0'; /* 去掉末尾的换行符 */
/* 创建哈夫曼树 */
HuffmanTree *tree = createHuffmanTree(str);
/* 生成哈夫曼编码表 */
HuffmanCodeList *list = generateHuffmanCode(tree);
/* 将文本字符串编码为0-1串 */
char *code = encode(list, str);
printf("编码结果:\n");
for (int i = 0; i < (strlen(code) + 7) / 8; i++) {
printf("%02x ", code[i] & 0xff);
}
printf("\n");
/* 将0-1串解码为文本字符串 */
char *decodedStr = decode(list, code);
printf("解码结果:%s\n", decodedStr);
/* 释放内存 */
TreeNode *node = tree->root;
free(tree);
while (node != NULL) {
TreeNode *next = node->left;
if (next == NULL) {
next = node->right;
free(node);
}
node = next;
}
HuffmanCode *huffmanCode = list->head;
while (huffmanCode != NULL) {
HuffmanCode *next = huffmanCode->next;
free(huffmanCode->code);
free(huffmanCode);
huffmanCode = next;
}
free(code);
free(decodedStr);
return 0;
}
```
以上代码是一个完整的实现,可以从键盘输入一个带空格由英文字母构成的文本字符串,创建对应的哈夫曼树,然后进行哈夫曼编码,并输出编码结果。同时,也实现了将哈夫曼编码结果解码为原始字符串的功能。
需要注意的是,由于哈夫曼编码结果是一个0-1串,所以在输出时需要进行一些转换。我在代码中采用了十六进制输出的方式,每个字节用两个十六进制数表示。在解码时,需要将0-1串中的每一个字节拆分成8个二进制位,并在编码表中查找对应的字符。如果匹配成功,则将该字符加入解码结果中;否则,将当前二进制位重新加入待匹配的子串中,继续匹配下一个二进制位。
帮我用C语言实现查找最近点 Description 给定一组二维点,每个点对应一个字符。给定任意一个位置,输出距离其最近点到它的距离。 【注意】输出要求:四位小数,输出4位小数的方式:printf("%.4f\n", x),为了保证精度,请大家用double进行输入和计算。 Input 第一行两个数:点的个数N以及查询的个数M 接下来N行,每行2个浮点数和一个字符,代表点的坐标以及其对应的字符 接下来M行,每行2个浮点数,代表希望查询的位置 数据范围满足 N<=10000, M<=10000 Output M行,每行为点集中距离查询位置最近的距离,精确到小数点后4位。
以下是基于kd-tree算法实现的C语言代码,实现查找最近点:
```c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#define MAXN 10005
typedef struct Point {
double x, y;
char c;
} Point;
typedef struct Node {
Point p;
struct Node *lc, *rc;
} Node;
int n, m;
Point points[MAXN];
Node *root;
int cmp(const void *a, const void *b) {
Point *p1 = (Point *)a;
Point *p2 = (Point *)b;
if (p1->x != p2->x)
return p1->x < p2->x ? -1 : 1;
return p1->y < p2->y ? -1 : 1;
}
void build_kd_tree(Node **p, int l, int r, int depth) {
if (l >= r) return;
int mid = l + r >> 1;
*p = (Node *)malloc(sizeof(Node));
(*p)->p = points[mid];
build_kd_tree(&(*p)->lc, l, mid, depth + 1);
build_kd_tree(&(*p)->rc, mid + 1, r, depth + 1);
if (depth & 1)
qsort(&points[l], r - l, sizeof(Point), cmp);
else
qsort(&points[l], r - l, sizeof(Point), cmp);
}
double dist(Point *p1, Point *p2) {
double dx = p1->x - p2->x, dy = p1->y - p2->y;
return sqrt(dx * dx + dy * dy);
}
double query_kd_tree(Node *p, Point *q, double d, int depth) {
if (!p) return d;
double d1 = dist(&p->p, q);
if (d1 < d) d = d1;
double dl = query_kd_tree(p->lc, q, d, depth + 1);
double dr = query_kd_tree(p->rc, q, d, depth + 1);
if (depth & 1) {
if (q->y - d < p->p.y)
d = fmin(d, dl);
if (q->y + d > p->p.y)
d = fmin(d, dr);
} else {
if (q->x - d < p->p.x)
d = fmin(d, dl);
if (q->x + d > p->p.x)
d = fmin(d, dr);
}
return d;
}
int main() {
scanf("%d%d", &n, &m);
for (int i = 0; i < n; ++i)
scanf("%lf%lf%*c%c", &points[i].x, &points[i].y, &points[i].c);
build_kd_tree(&root, 0, n, 0);
for (int i = 0; i < m; ++i) {
Point q;
scanf("%lf%lf", &q.x, &q.y);
printf("%.4f\n", query_kd_tree(root, &q, 1e10, 0));
}
return 0;
}
```
该算法中,首先将二维平面上的点按照x轴或y轴的大小排序,然后以中间点为根节点,递归构建kd-tree。在查询过程中,根据当前节点所在深度的奇偶性,判断需要遍历左子树或右子树,并且在遍历过程中,通过比较当前节点和查询点之间的距离和当前最小距离,来决定是否需要更新最小距离。
阅读全文
相关推荐
大家在看
AWS(亚马逊)云解决方案架构师面试三面作业全英文作业PPT
笔者参加亚马逊面试三面的作业,希望大家参考,少走弯路。
形成停止条件-c#导出pdf格式
(1)形成开始条件
(2)发送从机地址(Slave Address)
(3)命令,显示数据的传送
(4)形成停止条件
PS 1 1 1 0 0 1 A1 A0 A
Slave_Address
A
Command/Register
ACK ACK
A
Data(n)
ACK
D3 D2 D1 D0 D3 D2 D1 D0
图12
9 I2C 串行接口
本芯片由I2C协议2线串行接口来进行数据传送的,包含一个串行数据线SDA和时钟线SCL,两线内
置上拉电阻,总线空闲时为高电平。
每次数据传输时由控制器产生一个起始信号,采用同步串行传送数据,TM1680每接收一个字节数
据后都回应一个ACK应答信号。发送到SDA 线上的每个字节必须为8 位,每次传输可以发送的字节数量
不受限制。每个字节后必须跟一个ACK响应信号,在不需要ACK信号时,从SCL信号的第8个信号下降沿
到第9个信号下降沿为止需输入低电平“L”。当数据从最高位开始传送后,控制器通过产生停止信号
来终结总线传输,而数据发送过程中重新发送开始信号,则可不经过停止信号。
当SCL为高电平时,SDA上的数据保持稳定;SCL为低电平时允许SDA变化。如果SCL处于高电平时,
SDA上产生下降沿,则认为是起始信号;如果SCL处于高电平时,SDA上产生的上升沿认为是停止信号。
如下图所示:
SDA
SCL
开始条件
ACK ACK
停止条件
1 2 7 8 9 1 2 93-8
数据保持 数据改变
图13
时序图
1 写命令操作
PS 1 1 1 0 0 1 A1 A0 A 1
Slave_Address Command 1
ACK
A
Command i
ACK
X X X X X X X 1 X X X X X X XA
ACK ACK
A
图14
如图15所示,从器件的8位从地址字节的高6位固定为111001,接下来的2位A1、A0为器件外部的地
址位。
MSB LSB
1 1 1 0 0 1 A1 A0
图15
2 字节写操作
A PS A
Slave_Address
ACK
0 A
Address byte
ACK
Data byte
1 1 1 0 0 1 A1 A0 A6 A5 A4 A3 A2 A1 A0 D3 D2 D1 D0 D3 D2 D1 D0
ACK
图16
python大作业基于python实现的心电检测源码+数据+详细注释.zip
python大作业基于python实现的心电检测源码+数据+详细注释.zip
【1】项目代码完整且功能都验证ok,确保稳定可靠运行后才上传。欢迎下载使用!在使用过程中,如有问题或建议,请及时私信沟通,帮助解答。
【2】项目主要针对各个计算机相关专业,包括计科、信息安全、数据科学与大数据技术、人工智能、通信、物联网等领域的在校学生、专业教师或企业员工使用。
【3】项目具有较高的学习借鉴价值,不仅适用于小白学习入门进阶。也可作为毕设项目、课程设计、大作业、初期项目立项演示等。
【4】如果基础还行,或热爱钻研,可基于此项目进行二次开发,DIY其他不同功能,欢迎交流学习。
【备注】
项目下载解压后,项目名字和项目路径不要用中文,否则可能会出现解析不了的错误,建议解压重命名为英文名字后再运行!有问题私信沟通,祝顺利!
python大作业基于python实现的心电检测源码+数据+详细注释.zippython大作业基于python实现的心电检测源码+数据+详细注释.zippython大作业基于python实现的心电检测源码+数据+详细注释.zippython大作业基于python实现的心电检测源码+数据+详细注释.zippython大作业基于python实现的心电检测源码+数据+详细注释.zippython大作业基于python实现的心电检测源码+数据+详细注释.zippython大作业基于python实现的心电检测源码+数据+详细注释.zippython大作业基于python实现的心电检测源码+数据+详细注释.zippython大作业基于python实现的心电检测源码+数据+详细注释.zippython大作业基于python实现的心电检测源码+数据+详细注释.zippython大作业基于python实现的心电检测源码+数据+详细注释.zip
python大作业基于python实现的心电检测源码+数据+详细注释.zip
IEC 62133-2-2021最新中文版.rar
IEC 62133-2-2021最新中文版.rar
SAP各模块字段与表的对应关系
SAP各模块字段与表对应在个模块的关系以及描述
最新推荐
C语言实现输入一个字符串后打印出该字符串中字符的所有排列
在C语言中,实现输入一个字符串并打印出其所有字符排列的方法涉及到经典的排列组合问题,通常采用递归的方式来解决。这种算法称为全排列(Permutation)算法,它能生成一个集合的所有可能排列。这里我们将详细讲解...
java输入字符串并将每个字符输出的方法
本文分享了一篇java输入字符串并将每个字符输出的方法,使用了Scanner类来读取用户输入的字符串,然后使用for循环遍历字符串的每个字符,并使用charAt()方法来获取字符串中的每个字符,最后使用System.out.println()...
C语言中查找字符在字符串中出现的位置的方法
在C语言中,查找字符在字符串中出现的位置是常见的任务,这可以通过标准库提供的`strchr()`和`strrchr()`函数来实现。这两个函数都包含在`<string.h>`头文件中,它们的主要区别在于查找的方向:`strchr()`从字符串的...
C语言实现将字符串转换为数字的方法
在C语言中,将字符串转换为数字是一项常见的任务,这对于处理用户输入或解析文本数据至关重要。本文主要讨论了如何利用C语言的标准库函数将字符串转换为整数、长整数和浮点数。 首先,我们关注`atoi()`函数,它是...
C语言字符串快速压缩算法代码
本题目的目标是实现一个字符串快速压缩算法,它将连续重复的字符进行压缩,遵循"字符重复次数+字符"的格式。例如,"xxxyyyyyyz"会被压缩成"3x6yz"。下面我们将详细讨论这个算法的实现及其涉及的关键知识点。 首先,...
Pokedex: 探索JS开发的口袋妖怪应用程序
资源摘要信息:"Pokedex是一个基于JavaScript的应用程序,主要功能是收集和展示口袋妖怪的相关信息。该应用程序是用JavaScript语言开发的,是一种运行在浏览器端的动态网页应用程序,可以向用户提供口袋妖怪的各种数据,例如名称、分类、属性等。"
首先,我们需要明确JavaScript的作用。JavaScript是一种高级编程语言,是网页交互的核心,它可以在用户的浏览器中运行,实现各种动态效果。JavaScript的应用非常广泛,包括网页设计、游戏开发、移动应用开发等,它能够处理用户输入,更新网页内容,控制多媒体,动画以及各种数据的交互。
在这个Pokedex的应用中,JavaScript被用来构建一个口袋妖怪信息的数据库和前端界面。这涉及到前端开发的多个方面,包括但不限于:
1. DOM操作:JavaScript可以用来操控文档对象模型(DOM),通过DOM,JavaScript可以读取和修改网页内容。在Pokedex应用中,当用户点击一个口袋妖怪,JavaScript将利用DOM来更新页面,展示该口袋妖怪的详细信息。
2. 事件处理:应用程序需要响应用户的交互,比如点击按钮或链接。JavaScript可以绑定事件处理器来响应这些动作,从而实现更丰富的用户体验。
3. AJAX交互:Pokedex应用程序可能需要与服务器进行异步数据交换,而不重新加载页面。AJAX(Asynchronous JavaScript and XML)是一种在不刷新整个页面的情况下,进行数据交换的技术。JavaScript在这里扮演了发送请求、处理响应以及更新页面内容的角色。
4. JSON数据格式:由于JavaScript有内置的JSON对象,它可以非常方便地处理JSON数据格式。在Pokedex应用中,从服务器获取的数据很可能是JSON格式的口袋妖怪信息,JavaScript可以将其解析为JavaScript对象,并在应用中使用。
5. 动态用户界面:JavaScript可以用来创建动态用户界面,如弹出窗口、下拉菜单、滑动效果等,为用户提供更加丰富的交互体验。
6. 数据存储:JavaScript可以使用Web Storage API(包括localStorage和sessionStorage)在用户的浏览器上存储数据。这样,即使用户关闭浏览器或页面,数据也可以被保留,这对于用户体验来说是非常重要的,尤其是对于一个像Pokedex这样的应用程序,用户可能希望保存他们查询过的口袋妖怪信息。
此外,该应用程序被标记为“JavaScript”,这意味着它可能使用了JavaScript的最新特性或者流行的库和框架,例如React、Vue或Angular。这些现代的JavaScript框架能够使前端开发更加高效、模块化和易于维护。例如,React允许开发者构建可复用的UI组件,Vue则提供了数据驱动和组件化的编程方式,而Angular则是一个全面的前端框架,提供了模板、依赖注入、客户端路由等功能。
在文件名称列表中提到了"Pokedex-main",这很可能是应用程序的主文件或者项目的根目录名称。在这种情况下,主文件可能包含程序的入口点,即整个JavaScript应用程序开始执行的地方,它通常会包含对其他JavaScript文件的引用,以及初始化应用程序的代码。
综上所述,Pokedex作为一个JavaScript应用程序,涉及了前端开发的多个关键技术和概念。通过JavaScript,开发者能够实现一个功能丰富、响应用户交互、动态更新内容的应用程序,为用户提供口袋妖怪的详细信息和互动体验。
【提升R-Studio恢复效率】:RAID 5数据恢复的高级技巧与成功率
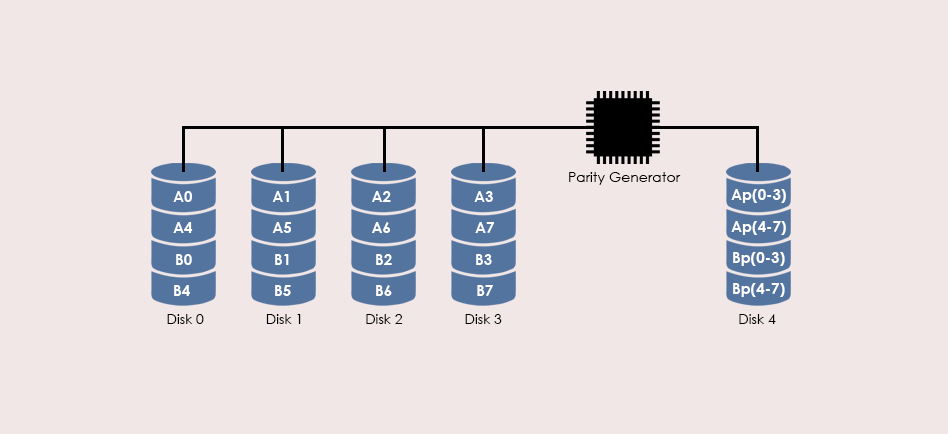
# 摘要
RAID 5作为一种广泛应用于数据存储的冗余阵列技术,能够提供较好的数据保护和性能平衡。本文首先概述了RAID 5数据恢复的重要性,随后介绍了RAID 5的基础理论,包括其工作原理、故障类型及数据恢复前的准备工作。接着,文章深入探讨了提升RAID 5数据恢复成功率的高级技巧,涵盖了硬件级别和软件工具的应用,以及文件系统结构和数据一致性检查。通过实际案例分析,
帮我写一段Python代码:sin波生成,设定rate,fin,size,幅值
当然可以。在Python中,我们可以使用`numpy`库来创建正弦波,并通过`tqdm`库添加进度条。下面是一个简单的示例代码,它会生成指定频率(rate)、持续时间(fin),以及样本大小(size)的正弦波,幅度可以自定义:
```python
import numpy as np
from tqdm import trange
# 定义函数生成sin波
def generate_sine_wave(rate=44100, fin=5, size=None, amplitude=1):
# 检查参数是否合理
if size is None:
size =
Laravel实用工具包:laravel-helpers概述
资源摘要信息:"Laravel开发-laravel-helpers 是一个针对Laravel框架开发者的实用程序包,它提供了许多核心功能的便捷访问器(getters)和修改器(setters)。这个包的设计初衷是为了提高开发效率,使得开发者能够快速地使用Laravel框架中常见的一些操作,而无需重复编写相同的代码。使用此包可以简化代码量,减少出错的几率,并且当开发者没有提供自定义实例时,它将自动回退到Laravel的原生外观,确保了功能的稳定性和可用性。"
知识点:
1. Laravel框架概述:
Laravel是一个基于PHP的开源Web应用框架,遵循MVC(Model-View-Controller)架构模式。它旨在通过提供一套丰富的工具来快速开发Web应用程序,同时保持代码的简洁和优雅。Laravel的特性包括路由、会话管理、缓存、模板引擎、数据库迁移等。
2. Laravel核心包:
Laravel的核心包是指那些构成框架基础的库和组件。它们包括但不限于路由(Routing)、请求(Request)、响应(Response)、视图(View)、数据库(Database)、验证(Validation)等。这些核心包提供了基础功能,并且可以被开发者在项目中广泛地使用。
3. Laravel的getters和setters:
在面向对象编程(OOP)中,getters和setters是指用来获取和设置对象属性值的方法。在Laravel中,这些通常指的是辅助函数或者服务容器中注册的方法,用于获取或设置框架内部的一些配置信息和对象实例。
4. Laravel外观模式:
外观(Facade)模式是软件工程中常用的封装技术,它为复杂的子系统提供一个简化的接口。在Laravel框架中,外观模式广泛应用于其核心类库,使得开发者可以通过简洁的类方法调用来执行复杂的操作。
5. 使用laravel-helpers的优势:
laravel-helpers包作为一个辅助工具包,它将常见的操作封装成易于使用的函数,使开发者在编写Laravel应用时更加便捷。它省去了编写重复代码的麻烦,降低了项目的复杂度,从而加快了开发进程。
6. 自定义实例和回退机制:
在laravel-helpers包中,如果开发者没有提供特定的自定义实例,该包能够自动回退到使用Laravel的原生外观。这种设计使得开发者在不牺牲框架本有功能的前提下,能够享受到额外的便利性。
7. Laravel开发实践:
在实际的开发过程中,开发者可以通过引入laravel-helpers包来简化代码的编写。例如,该包可能提供了一系列用于验证输入数据的快速方法,或者是一些处理常见任务的辅助函数,如快速生成响应、执行数据库查询、发送邮件等。
8. 开源贡献和社区支持:
laravel-helpers作为一个开源包,它的维护和更新依赖于社区的贡献。开发者在使用过程中也可以参与到包的开发与改进中,为Laravel社区做出贡献,并从社区中获取帮助和反馈。
总结而言,laravel-helpers包通过提供一系列的getters和setters工具函数,极大地提升了Laravel开发的效率与便利性。它不仅遵循了Laravel的核心设计理念,还通过回退机制保证了与框架原生功能的兼容性。对于希望优化其开发流程的Laravel开发者来说,这无疑是一个宝贵的资源。
【R-Studio技术路径】:从RAID 5数据恢复基础到高级操作

# 摘要
随着信息技术的发展,数据丢失问题日益突出,RAID 5作为常见的数据存储解决方案,其数据恢复技术显得尤为重要。本文首先介绍了RAID 5数据恢复的基础知识,然后详细解析了R-Studio软件的界面和核心功能,重点探讨了其在RAID 5数据恢复中的应用实践,包括磁盘镜像创建、数据提取、数据重组策略及一致性验证。进一步,本文还涉及了R-Studio的进阶技术,如脚本编