dobble zookeeper怎样使用
时间: 2023-05-04 09:00:30 浏览: 49
b'dobble'是一个开源软件,它可以用来检测Zookeeper集群的数据一致性问题。使用b'dobble'时,需要先安装并配置好Zookeeper集群,然后运行b'dobble'的命令来进行数据一致性检测。通过检测结果,可以帮助管理员发现和解决Zookeeper集群中出现的数据不一致问题。
相关问题
Could not find or load main class org.apache.zookeeper.server.quorum.QuorumPeerMain
The error message you mentioned, "Could not find or load main class org.apache.zookeeper.server.quorum.QuorumPeerMain," indicates that the Java Virtual Machine (JVM) is unable to find or load the main class required to start the ZooKeeper server.
To resolve this issue, you can try the following steps:
1. Check if ZooKeeper is properly installed and configured on your system. Make sure you have the necessary dependencies and environment variables set up correctly.
2. Verify that the classpath is set correctly. The classpath should include the directory where the ZooKeeper JAR file is located. You can check and adjust the classpath using the `CLASSPATH` environment variable or by using command-line options when running your Java program.
3. Ensure that you have the correct version of ZooKeeper. Double-check if the version of ZooKeeper you are trying to run is compatible with your system and any other dependencies.
4. If you are running ZooKeeper in a distributed mode, ensure that the configuration files are correctly set up, including the `zoo.cfg` file.
If none of these steps resolve the issue, please provide more details about your setup, such as the operating system, Java version, and any specific commands or steps you have taken.
利用编程从HBASE中读取学生成绩,并实现计算每个学生成绩平均分和每门课程成绩平均分,用MapReduce方法,使用Java API编程
以下是从HBase中读取学生成绩并计算平均分的Java代码示例:
```java
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
public class HBaseAverageScore {
private static Configuration conf = null;
private static Connection conn = null;
private static Admin admin = null;
private static Table table = null;
// 初始化HBase配置
static {
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "localhost");
try {
conn = ConnectionFactory.createConnection(conf);
admin = conn.getAdmin();
table = conn.getTable(TableName.valueOf("scores"));
} catch (IOException e) {
e.printStackTrace();
}
}
// 关闭资源
private static void close() {
if (admin != null) {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (table != null) {
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 从HBase中读取学生成绩
public static class HBaseMapper extends TableMapper<Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text keyText = new Text();
private IntWritable valueInt = new IntWritable();
// 读取学生成绩
public void map(ImmutableBytesWritable row, Result value, Context context) throws IOException, InterruptedException {
for (Cell cell : value.rawCells()) {
String[] items = Bytes.toString(CellUtil.cloneQualifier(cell)).split("_");
String course = items[0];
String student = Bytes.toString(CellUtil.cloneRow(cell));
int score = Bytes.toInt(CellUtil.cloneValue(cell));
// 计算每个学生的平均分
keyText.set(student);
valueInt.set(score);
context.write(keyText, valueInt);
// 计算每门课程的平均分
keyText.set(course);
valueInt.set(score);
context.write(keyText, valueInt);
}
}
}
// 计算平均分
public static class HBaseReducer extends Reducer<Text, IntWritable, Text, DoubleWritable> {
private DoubleWritable result = new DoubleWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
for (IntWritable val : values) {
sum += val.get();
count++;
}
double average = (double) sum / count;
result.set(average);
context.write(key, result);
}
}
// 主函数
public static void main(String[] args) throws Exception {
// 配置MapReduce作业
Job job = Job.getInstance(conf, "HBaseAverageScore");
job.setJarByClass(HBaseAverageScore.class);
Scan scan = new Scan();
scan.setCaching(500);
scan.setCacheBlocks(false);
FilterList filters = new FilterList(FilterList.Operator.MUST_PASS_ALL);
filters.addFilter(new FamilyFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("info"))));
scan.setFilter(filters);
TableMapReduceUtil.initTableMapperJob("scores", scan, HBaseMapper.class, Text.class, IntWritable.class, job);
job.setReducerClass(HBaseReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
FileOutputFormat.setOutputPath(job, new Path(args[0]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
close();
}
}
```
在该代码中,我们使用了HBase的Java API来读取学生成绩数据,并使用MapReduce方法计算每个学生的平均分和每门课程的平均分。具体实现中,我们首先使用TableMapper来读取HBase表中的数据,并将其转换成MapReduce作业所需的键值对格式。然后,我们使用Reducer来计算每个学生和每门课程的平均分。最后,我们将计算结果输出到指定路径下的文件中。
需要注意的是,由于HBase是一种分布式数据库,因此我们需要配置HBase的相关参数,如zookeeper的地址等。另外,由于HBase的表结构是动态的,我们需要对表的列族和列名进行相应的过滤和处理,以便正确地读取数据。
相关推荐
最新推荐
MATLAB算法插值与拟合代码
MATLAB算法插值与拟合代码提取方式是百度网盘分享地址
基于二级计算机系统建立无取向硅钢轧制模型的研究
随着计算机的发展及轧制自动化程度的提高,计算机控制系统在带钢热连轧生产线 中发挥着越来越重要的作用。硅钢作为钢中的艺术品,对轧制精度要求极高,传统的计 算机控制系统轧制模型并不能适应硅钢高精度轧制的生产要求,因此,开发设计精确的 轧制模型显得尤为重要。
本文以包钢CSP热连轧计算机控制系统为研究对象,针对原有轧制模型生产硅钢无 法达到成品厚度要求精度的问题,以新品种硅钢50SW800为研究对象,开发了适应性 较好的厚度精度控制轧制力模型与轧制力自学习模型,实际运行良好。主要工作及结论 如下:
通过分析大量硅钢轧制的重要工艺参数的变化规律,剔除温度、张力、摩擦力等影 响参数,主要针对带钢的变形抗力进行研究,采用微单元的塑性变形方程式,进行硅钢 变形抗力参数的计算,并利用在轧制时材料化学元素、变形率、温度、实际轧制压力、 理论轧制压力等数据通过多元线性回归得出新的轧制压力修正系数,最终成功构建了轧 制力模型,最终将该轧制力模型用于硅钢的轧制力设定预计算,首坯轧制偏差降低60%。
uAI - AI Assistant 1.3.7人工智能助手Unity插件unitypackage项目源码C#
uAI - AI Assistant 1.3.7人工智能助手Unity插件unitypackage项目源码C#
支持Unity版本2020.3.45或更高
uAI Assistant 是 Unity 的扩展,提供了一套强大的工具,由 OpenAI 最新的 GPT-4 Turbo 提供支持,具有 128k 上下文窗口、3.5 AI 模型以及 Dall-E 2 和 Dall-E 3。
uAI Assistant 中包含的 DemoScene 使用 Unity 包管理器中的 TextMeshPro 包作为 UI 文本。确保在导入此包之前导入它。
还要导入“TMP Essential Resources”,因为 DemoScene 使用“LiberationSans.ttf”字体。有关说明,请参阅文档。
uAI 助手?
uAI Assistant 是 Unity 游戏引擎的强大扩展,它使用 GPT AI 帮助游戏开发人员轻松创建专业代码和引人入胜的游戏内容。
您需要 OpenAI 密钥才能使用 uAI Assistant!请阅读我们的文档以获取更多说明。
让你的纹理变得无缝
使用 AI 创建
2024年全球液化天然气船用发电机组行业总体规模、主要企业国内外市场占有率及排名.docx
2024年全球液化天然气船用发电机组行业总体规模、主要企业国内外市场占有率及排名
AX3_model_extras-1.5.3-py3-none-any.whl.zip
AX3_model_extras-1.5.3-py3-none-any.whl.zip
医院人力资源规划PPT模板.pptx
医院人力资源规划是为了实现医院的战略目标,通过对现有人力资源进行分析和预测,确定未来一段时间内所需要的人力资源数量、结构和质量的过程。医院人力资源规划需要充分考虑医院的发展战略、业务需求、市场竞争状况以及政策法规等因素,以确保人力资源的有效配置和利用。通过制定科学合理的人力资源规划,医院可以提前预测和解决可能出现的人力资源短缺或过剩问题,降低人力资源管理风险,提高组织绩效。医院人力资源规划应具有灵活性和可持续性,能够根据外部环境的变化和医院内部发展的需要进行适时调整,以实现人力资源的长期稳定发展。
医院人力资源规划对于医院的长期发展具有重要意义。它有助于合理配置人力资源,提高医疗服务质量,降低人力成本,从而提升医院的竞争力和市场地位。通过科学的医院人力资源规划,可以确保医院拥有足够的合格人员,从而保障医院的正常运转和发展。同时,人力资源规划还可以帮助医院建立健全的人才储备和晋升机制,激励员工持续提升自身能力和业绩,为医院的可持续发展奠定基础。
在医院人力资源规划中,人力资源需求分析是一个关键环节。通过对医院各部门和岗位的人力需求情况进行详细调研和分析,可以确定医院未来一段时间内所需的人才数量和结构,并制定相应的招聘计划和培训方案。人力资源招聘与配置是确保医院人力资源充足和合理配置的重要步骤。医院需要根据实际需求和岗位要求,制定招聘标准,通过多种途径吸引和选拔优秀人才,并将其分配到适合的岗位上,以发挥其最大潜能。
在医院人力资源规划中,培训与发展策略的制定非常重要。医院需要根据员工的实际情况和发展需求,制定个性化的培训计划,提供各种培训资源和机会,帮助员工不断提升自身素质和技能,适应医院的发展需求。绩效评估与激励措施是医院人力资源管理的关键环节。通过建立科学合理的绩效评估体系,可以客观、公正地评价员工的工作表现,为员工提供激励机制,激发其工作热情和创造力,促进医院整体绩效的提升。
在最后的总结中,医院人力资源规划的成功实施需要医院领导层的高度重视和支持,需要各部门之间的密切合作和协调,还需要全体员工的积极参与和配合。只有通过全员共同努力,才能确保医院人力资源规划的顺利实施,为医院的长期发展和持续成功奠定良好基础。医院人力资源规划是医院管理工作的重要组成部分,它不仅关系到医院的发展和竞争力,也关系到员工的个人发展和幸福感。希望医院人力资源规划可以不断完善和优化,为医院的可持续发展和员工的幸福生活做出积极贡献。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
Scrapy中的去重与增量爬取技术探究
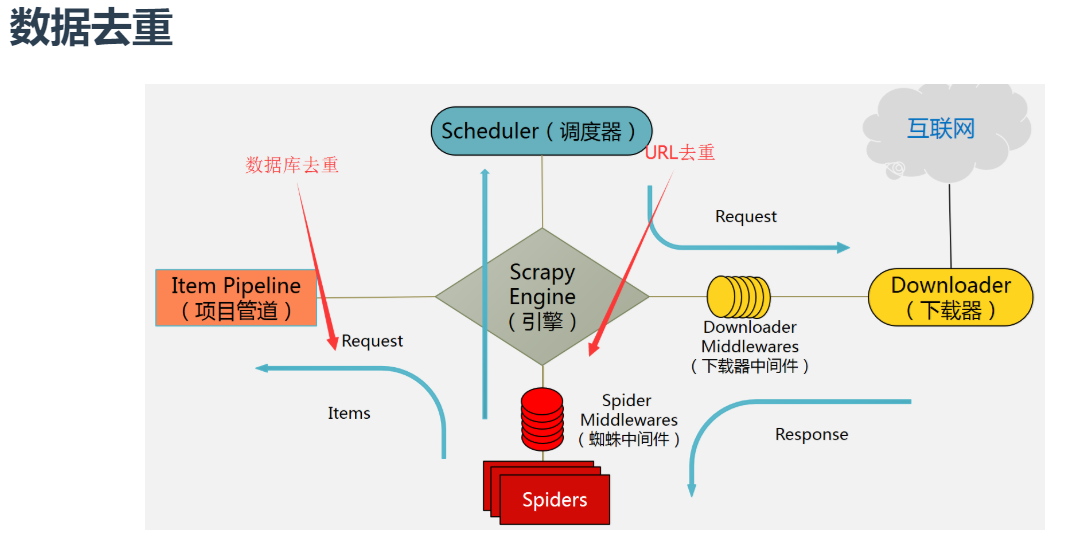
# 1. 爬虫框架介绍
网络爬虫,简单来说就是一种自动获取网页信息的程序,能够模拟浏览器请求并解析网页内容。爬虫框架则是一种可以帮助用户快速开发爬虫程序的工具,提供了一系列功能组件,简化了爬虫程序的开发流程。
爬虫框架的作用主要在于提供了网络请求、页面解析、数据存储等功能,让开发者能够专注于业务逻辑的实现,而不必过多关注底层细节。使用爬虫框架可以提高开发效率,降
qt 窗口设置Qt::WindowStaysOnTopHint之后,QCombox无法弹出
当窗口设置了Qt::WindowStaysOnTopHint标志后,QComboBox可能无法弹出。这是因为Qt::WindowStaysOnTopHint会将窗口置于其他窗口之上,包括弹出菜单窗口。
解决这个问题的一个方法是,将Qt::WindowStaysOnTopHint标志应用于QComboBox的弹出菜单。这样可以确保弹出菜单始终在最顶层显示,而不受窗口置顶标志的影响。
以下是一个示例代码:
```cpp
// 创建QComboBox对象
QComboBox* comboBox = new QComboBox(parent);
// 获取弹出菜单窗口
QMenu* menu
毕业论文ssm412影院在线售票系统.docx
本毕业论文以《ssm412影院在线售票系统》为主题,主要目的是为了介绍并实现一个电影院售票网站,以提高管理效率并促进电影产业的发展。论文主要包括摘要、背景意义、论文结构安排、开发技术介绍、需求分析、可行性分析、功能分析、业务流程分析、数据库设计、ER图、数据字典、数据流图、详细设计、系统截图、测试、总结、致谢、参考文献等内容。
在摘要部分,指出随着社会的发展,管理工作的科学化变得至关重要,而电影院售票网站的建设正是符合管理工作科学化的需要。通过介绍现有的研究现状和系统设计目标,论文概述了对电影院售票网站的研究内容和意义。
在背景意义部分,阐明了管理工作的科学化对于信息存储准确、快速和完善的重要性。而电影院作为一种娱乐文化形式,特别适合在互联网上进行售票,以提高用户体验和管理效率。因此,建设一个电影院售票网站是符合时代潮流和社会需求的。
在论文结构安排部分,详细列出了论文各个章节的内容和安排,包括开发技术介绍、需求分析、可行性分析、功能分析、业务流程分析、数据库设计、ER图、数据字典、数据流图、详细设计、系统截图、测试等内容,以便读者了解整体的论文结构和内容安排。
在开发技术介绍部分,介绍了采用了SSM框架作为开发技术,以实现一个电影院售票网站。通过SSM框架的应用,实现了管理员和用户前台的各项功能模块,包括首页、个人中心、用户管理、电影类型管理、放映厅管理、正在上映管理、即将上映管理、系统管理、订单管理等功能。
在需求分析、可行性分析、功能分析和业务流程分析部分,通过详细的研究和分析,确定了系统的需求、功能和业务流程,为系统设计和实现提供了具体的指导和依据。
在数据库设计、ER图、数据字典和数据流图部分,详细设计了系统的数据库结构和数据流向,以确保系统的数据存储和处理的准确性和完整性。
在详细设计和系统截图部分,展示了系统的具体设计和实现过程,包括界面设计、功能实现和用户操作流程,以便读者了解系统的整体架构和运行流程。
在测试和总结部分,对系统进行了详细的测试和评估,总结了系统的优点和不足之处,并提出了改进建议和展望。
在致谢和参考文献部分,感谢所有给予支持和帮助的人员和机构,并列出了参考文献,以便读者查阅相关资料和研究。
综上所述,本毕业论文全面介绍了《ssm412影院在线售票系统》的设计与实现过程,通过详细的研究和分析,实现了一个功能完善的电影院售票网站,为电影产业的发展和管理工作的科学化提供了有力支持和借鉴。