倒排索引的合并和拆分代码实现
时间: 2023-05-18 07:07:05 浏览: 65
倒排索引的合并和拆分是搜索引擎中非常重要的一部分。在合并时,需要将多个倒排索引文件合并成一个,以便于搜索引擎进行查询。而在拆分时,需要将一个较大的倒排索引文件拆分成多个较小的文件,以便于存储和管理。
以下是倒排索引的合并和拆分的代码实现:
合并代码实现:
1. 首先,需要将所有的倒排索引文件读入内存中。
2. 然后,将所有的倒排索引文件按照词项进行排序。
3. 接着,使用归并排序的方式将所有的倒排索引文件合并成一个文件。
4. 最后,将合并后的倒排索引文件写入磁盘中。
拆分代码实现:
1. 首先,需要将需要拆分的倒排索引文件读入内存中。
2. 然后,按照一定的规则将倒排索引文件拆分成多个较小的文件。
3. 接着,将拆分后的倒排索引文件写入磁盘中。
需要注意的是,在进行倒排索引的合并和拆分时,需要考虑到磁盘空间的限制,以及合并和拆分的效率问题。因此,在实际应用中,需要根据具体情况进行优化。
相关问题
代码实现索引的合并和拆分
索引的合并和拆分可以通过使用 Elasticsearch 的 API 来实现。具体实现方法如下:
1. 索引的合并
使用 Elasticsearch 的 reindex API 可以将多个索引合并成一个索引。具体实现方法如下:
```
POST _reindex
{
"source": {
"index": ["index1", "index2"]
},
"dest": {
"index": "new_index"
}
}
```
其中,source.index 指定了需要合并的索引列表,dest.index 指定了合并后的新索引名称。
2. 索引的拆分
使用 Elasticsearch 的 split API 可以将一个索引拆分成多个索引。具体实现方法如下:
```
POST /source_index/_split/new_index
{
"settings": {
"index.number_of_shards": 2
}
}
```
其中,source_index 指定了需要拆分的索引名称,new_index 指定了拆分后的新索引名称,index.number_of_shards 指定了新索引的分片数。
注意:以上代码仅供参考,具体实现方法需要根据实际情况进行调整。
python代码实现索引的合并和拆分
索引的合并和拆分可以使用 Pandas 库来实现。下面是示例代码:
合并索引:
```python
import pandas as pd
# 创建两个 DataFrame
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}, index=['a', 'b', 'c'])
df2 = pd.DataFrame({'C': [7, 8, 9], 'D': [10, 11, 12]}, index=['a', 'b', 'c'])
# 合并索引
merged = pd.concat([df1, df2], axis=1)
print(merged)
```
输出结果:
```
A B C D
a 1 4 7 10
b 2 5 8 11
c 3 6 9 12
```
拆分索引:
```python
import pandas as pd
# 创建一个 DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}, index=pd.MultiIndex.from_tuples([('a', 'x'), ('b', 'y'), ('c', 'z')]))
# 拆分索引
split = df.reset_index(level=1)
print(split)
```
输出结果:
```
level_1 A B
a x 1 4
b y 2 5
c z 3 6
```
注意:以上代码仅供参考,具体实现方式可能因数据结构和需求而异。
相关推荐
最新推荐
c++实现合并文件以及拆分实例代码
主要介绍了c++实现合并文件以及拆分实例代码,小编觉得还是挺不错的,具有一定借鉴价值,需要的朋友可以参考下
C#实现合并及拆分PDF文件的方法
主要为大家详细介绍了C#合并及拆分PDF文件的方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
PDF拆分合并工具(免费).doc
免费进行PDF拆分合并,不需要会员,免安装,程序非常简洁实用,可同时合并拆分多个文件,无文件大小限制。百度网盘下载链接,安装该软件即可使用,压缩包版无需安装可直接使用。
奥维合并拆分轨迹.docx
奥维地图里关于合并、拆分轨迹说明,主要就是用鼠标配合键盘控制键,一看明白!
VBA对excel合并、拆分
使用VBA对excel进行合并、拆分进行了完善,适合多文件,多sheet的合并,希望对大家用帮助
zigbee-cluster-library-specification
最新的zigbee-cluster-library-specification说明文档。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL数据库性能提升秘籍:揭秘性能下降幕后真凶及解决策略
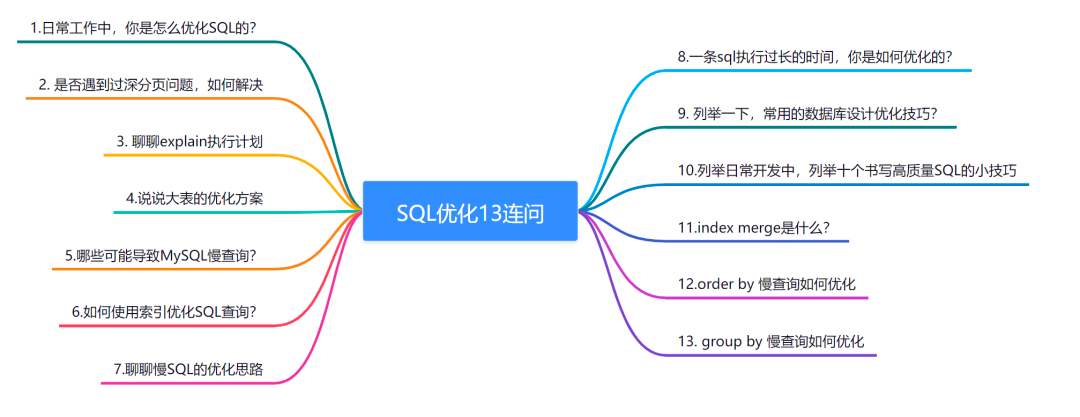
# 1. MySQL数据库性能优化概述**
MySQL数据库性能优化是一项至关重要的任务,可以显著提高应用程序的响应时间和整体用户体验。优化涉及识别和解决影响数据库性能的因素,包括硬件资源瓶颈、软件配置不当和数据库设计缺陷。通过采取适当的优化策略,可以显著提升数据库性能,满足业务需求并提高用户满意度。
# 2. MySQL数据库性能下降的幕后真凶
### 2.1 硬件资源瓶颈
#### 2.1.1 CPU利用率过高
**症状:
如何在unity创建按钮
在 Unity 中创建按钮的步骤如下:
1. 在 Unity 中创建一个 UI Canvas,选择 GameObject -> UI -> Canvas。
2. 在 Canvas 中创建一个按钮,选择 GameObject -> UI -> Button。
3. 在场景视图中调整按钮的位置和大小。
4. 在 Inspector 中设置按钮的文本、颜色、字体等属性。
5. 添加按钮的响应事件,选择按钮,在 Inspector 的 On Click () 中添加相应的方法。
这样就可以创建一个按钮了,你可以在游戏中使用它来触发相应的操作。
JSBSim Reference Manual
JSBSim参考手册,其中包含JSBSim简介,JSBSim配置文件xml的编写语法,编程手册以及一些应用实例等。其中有部分内容还没有写完,估计有生之年很难看到完整版了,但是内容还是很有参考价值的。