python网络爬虫源代码
时间: 2023-05-10 12:02:16 浏览: 97
Python是一种功能强大的编程语言,可以用于编写各种应用程序,包括网络爬虫。网络爬虫是一种可以自动从互联网上抓取数据的程序,它可以用于数据挖掘、搜索引擎优化、市场情报等多个领域。
Python网络爬虫源代码的编写过程包括以下几个步骤:
第一步,请求目标网站。使用Python中的requests库向目标网站发送http请求,并获取返回的网页内容。请求过程中需要设置请求头,以模拟浏览器访问,避免被目标网站封禁。
第二步,解析网页内容。使用Python中的正则表达式或者第三方库BeautifulSoup对网页进行解析,以提取自己需要的数据。正则表达式用于提取规则比较固定的数据,而BeautifulSoup则适用于提取HTML结构化数据。
第三步,保存数据。将提取到的数据保存到本地或者数据库中,以便后续的数据分析和使用。保存方式可以选择CSV、JSON或者数据库等多种方式。
第四步,设置爬虫规则。为了避免被目标网站封禁,需要设置合理的爬虫规则,包括时间间隔、请求频率、请求头等等。还需要遵守robots协议,禁止爬取受保护的数据。
第五步,创建多个线程或进程。为了提高爬取效率,需要使用多线程或者多进程的方式进行爬取。多线程方式可以使用Python中的threading模块,而多进程则可以使用multiprocessing模块。
以上就是Python网络爬虫源代码的基本编写过程。不过需要注意的是,在实际使用中还需要考虑目标网站的反爬虫策略,以及自身爬虫的合法性和道德性。
相关问题
python爬虫万能代码-python网络爬虫源代码(可直接抓取图片)
下面是一个简单的 Python 网络爬虫源代码,可以抓取网页内容和图片:
```python
import requests
from bs4 import BeautifulSoup
import os
# 爬取网页内容
url = 'https://www.example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
# 爬取图片
img_url = 'https://www.example.com/image.jpg'
response = requests.get(img_url)
img_name = os.path.basename(img_url)
with open(img_name, 'wb') as f:
f.write(response.content)
```
需要注意的是,爬取网页内容和图片时需要考虑网站的版权和法律问题,避免侵犯他人权益。同时,爬虫对网站的访问量也会产生一定压力,应该遵循网站的访问规则和礼仪。
python网络爬虫淘宝源代码
以下是一个简单的Python网络爬虫淘宝的源代码:
```python
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price , title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 2
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
```
相关推荐
最新推荐
基于python的网络爬虫设计
以世纪佳缘网为例,思考自己所需要的数据资源,并以此为基础设计...通过python的urllib2函数进行世纪佳缘网源代码的获取。用正则表达式分析源代码,找到所需信息导入excel。连接数据库,将爬下的数据存储在数据库中。
81个Python爬虫源代码+九款开源爬虫工具.doc
81个Python爬虫源代码+九款开源爬虫工具,81个Python爬虫源代码,内容包含新闻、视频、中介、招聘、图片资源等网站的爬虫资源
安卓桌面应用EyeRoom.zip
android 源码学习.
资料部分来源于合法的互联网渠道收集和整理,供大家学习参考与交流。本人不对所涉及的版权问题或内容负法律责任。如有侵权,请通知本人删除。感谢CSDN官方提供大家交流的平台
2023年中国辣条食品行业创新及消费需求洞察报告.pptx
随着时间的推移,中国辣条食品行业在2023年迎来了新的发展机遇和挑战。根据《2023年中国辣条食品行业创新及消费需求洞察报告》,辣条食品作为一种以面粉、豆类、薯类等原料为基础,添加辣椒、调味料等辅料制成的食品,在中国市场拥有着广阔的消费群体和市场潜力。
在行业概述部分,报告首先介绍了辣条食品的定义和分类,强调了辣条食品的多样性和口味特点,满足消费者不同的口味需求。随后,报告回顾了辣条食品行业的发展历程,指出其经历了从传统手工制作到现代化机械生产的转变,市场规模不断扩大,产品种类也不断增加。报告还指出,随着消费者对健康饮食的关注增加,辣条食品行业也开始向健康、营养的方向发展,倡导绿色、有机的生产方式。
在行业创新洞察部分,报告介绍了辣条食品行业的创新趋势和发展动向。报告指出,随着科技的不断进步,辣条食品行业在生产工艺、包装设计、营销方式等方面都出现了新的创新,提升了产品的品质和竞争力。同时,报告还分析了未来可能出现的新产品和新技术,为行业发展提供了新的思路和机遇。
消费需求洞察部分则重点关注了消费者对辣条食品的需求和偏好。报告通过调查和分析发现,消费者在选择辣条食品时更加注重健康、营养、口味的多样性,对产品的品质和安全性提出了更高的要求。因此,未来行业需要加强产品研发和品牌建设,提高产品的营养价值和口感体验,以满足消费者不断升级的需求。
在市场竞争格局部分,报告对行业内主要企业的市场地位、产品销量、市场份额等进行了分析比较。报告发现,中国辣条食品行业竞争激烈,主要企业之间存在着激烈的价格战和营销竞争,产品同质化严重。因此,企业需要加强品牌建设,提升产品品质,寻求差异化竞争的突破口。
最后,在行业发展趋势与展望部分,报告对未来辣条食品行业的发展趋势进行了展望和预测。报告认为,随着消费者对健康、有机食品的需求增加,辣条食品行业将进一步向健康、营养、绿色的方向发展,加强与农业合作,推动产业升级。同时,随着科技的不断进步,辣条食品行业还将迎来更多的创新和发展机遇,为行业的持续发展注入新的动力。
综上所述,《2023年中国辣条食品行业创新及消费需求洞察报告》全面深入地分析了中国辣条食品行业的发展现状、创新动向和消费需求,为行业的未来发展提供了重要的参考和借鉴。随着消费者消费观念的不断升级和科技的持续发展,中国辣条食品行业有望迎来更加广阔的发展空间,实现可持续发展和行业繁荣。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
学习率衰减策略及调参技巧:在CNN中的精准应用指南
# 1. 学习率衰减策略概述
学习率衰减是深度学习中常用的优化技巧,旨在调整模型训练时的学习率,以提高模型性能和收敛速度。在训练迭代过程中,通过逐步减小学习率的数值,模型在接近收敛时可以更精细地调整参数,避免在局部最优点处震荡。学习率衰减策略种类繁多,包括固定衰减率、指数衰减、阶梯衰减和余弦衰减等,每种方法都有适用的场景和优势。掌握不同学习率衰减策略,可以帮助深度学习从业者更好地训练和调优模型。
# 2. 深入理解学习率衰减
学习率衰减在深度学习中扮演着重要的角色,能够帮助模型更快地收敛,并提高训练效率和泛化能力。在本章节中,我们将深入理解学习率衰减的基本概念、原理以及常见方法。
##
如何让restTemplate call到一个mock的数据
要使用 `RestTemplate` 调用一个模拟的数据,你可以使用 `MockRestServiceServer` 类来模拟服务端的响应。下面是一个示例代码:
```java
import org.springframework.http.HttpMethod;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.test
2023年半导体行业20强品牌.pptx
2023年半导体行业20强品牌汇报人文小库于2024年1月10日提交了《2023年半导体行业20强品牌》的报告,报告内容主要包括品牌概述、产品线分析、技术创新、市场趋势和品牌策略。根据报告显示的数据和分析,可以看出各品牌在半导体行业中的综合实力和发展情况。
在品牌概述部分,文小库对2023年半导体行业20强品牌进行了排名,主要根据市场份额、技术创新能力和品牌知名度等多个指标进行评估。通过综合评估,得出了各品牌在半导体行业中的排名,并分析了各品牌的市场份额变化情况,了解了各品牌在市场中的竞争态势和发展趋势。此外,还对各品牌的品牌影响力进行了分析,包括对行业发展的推动作用和对消费者的影响力等方面进行评估,从品牌知名度和品牌价值两个维度来评判各品牌的实力。
在产品线分析部分,报告详细描述了微处理器在半导体行业中的核心地位,这是主要应用于计算机、手机、平板等智能终端设备中的关键产品。通过对产品线进行详细分析,可以了解各品牌在半导体领域中的产品布局和市场表现,为后续的市场策略制定提供了重要的参考信息。
在技术创新方面,报告也对各品牌在技术创新方面的表现进行了评估,这是半导体行业发展的关键驱动力之一。通过分析各品牌在技术研发、产品设计和生产制造等方面的创新能力,可以评判各品牌在未来发展中的竞争优势和潜力,为品牌策略的制定提供重要依据。
在市场趋势和品牌策略方面,报告分析了半导体行业的发展趋势和竞争格局,为各品牌制定市场策略和品牌推广提供了重要参考。针对未来市场发展的趋势,各品牌需要不断加强技术创新、提升品牌影响力,以及制定有效的市场推广策略,来保持在行业中的竞争优势。
综上所述,在2023年半导体行业20强品牌报告中,通过对各品牌的综合排名、产品线分析、技术创新、市场趋势和品牌策略等方面的评估和分析,展现了各品牌在半导体行业中的实力和发展状态,为半导体行业的未来发展提供了重要的参考和指导。
"互动学习:行动中的多样性与论文攻读经历"
多样性她- 事实上SCI NCES你的时间表ECOLEDO C Tora SC和NCESPOUR l’Ingén学习互动,互动学习以行动为中心的强化学习学会互动,互动学习,以行动为中心的强化学习计算机科学博士论文于2021年9月28日在Villeneuve d'Asq公开支持马修·瑟林评审团主席法布里斯·勒菲弗尔阿维尼翁大学教授论文指导奥利维尔·皮耶昆谷歌研究教授:智囊团论文联合主任菲利普·普雷教授,大学。里尔/CRISTAL/因里亚报告员奥利维耶·西格德索邦大学报告员卢多维奇·德诺耶教授,Facebook /索邦大学审查员越南圣迈IMT Atlantic高级讲师邀请弗洛里安·斯特鲁布博士,Deepmind对于那些及时看到自己错误的人...3谢谢你首先,我要感谢我的两位博士生导师Olivier和Philippe。奥利维尔,"站在巨人的肩膀上"这句话对你来说完全有意义了。从科学上讲,你知道在这篇论文的(许多)错误中,你是我可以依
量化与剪枝技术在CNN模型中的神奇应用及效果评估
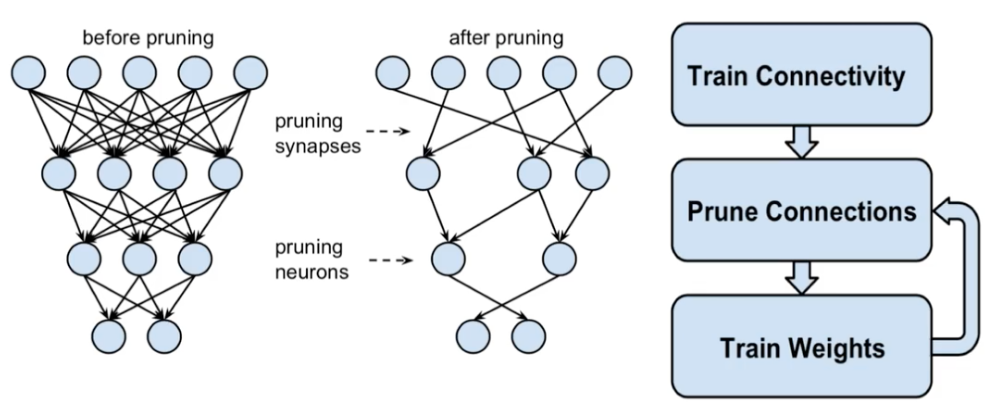
# 1. 量化与剪枝技术在CNN模型中的概览
在深度学习领域,量化与剪枝技术作为优化模型的重要手段,近年来备受关注。量化技术主要通过减少模型参数的位数,降低模型的计算复杂度,进而提升模型的推理速度。而剪枝技术则通过去除冗余的连接和神经元,减小模型的规模,提高模型的泛化能力和效率。本章将对这两项技术进行综述,为后续章节的深入探讨奠定基础。
# 2. 深入理解量化技术
### 2.1 量化技术概述
量化技术