代码解释:data.numDemand=length(data.Demand(:,3));
时间: 2024-03-19 19:42:01 浏览: 29
这段代码的作用是计算一个名为`data`的结构体中`Demand`矩阵的第三列的长度(即该列中元素的个数),并将结果保存在`numDemand`变量中。
其中,`data.Demand`表示结构体`data`中名为`Demand`的矩阵,`:`表示该矩阵的所有行,`3`表示该矩阵的第三列。因此,`data.Demand(:,3)`表示`Demand`矩阵的所有行中的第三列。
最终,`length()`函数会计算`data.Demand(:,3)`的长度,即该列中元素的个数,并将结果赋值给`numDemand`变量。
相关问题
解释代码:data.numACenter=length(data.Center(:,1));
这段代码的作用是计算一个名为`data`的结构体中`Center`矩阵的第一列的长度(即该列中元素的个数),并将结果保存在`numACenter`变量中。
其中,`data.Center`表示结构体`data`中名为`Center`的矩阵,`:`表示该矩阵的所有行,`1`表示该矩阵的第一列。因此,`data.Center(:,1)`表示`Center`矩阵的所有行中的第一列。
最终,`length()`函数会计算`data.Center(:,1)`的长度,即该列中元素的个数,并将结果赋值给`numACenter`变量。
约瑟夫环改错class Node: def __init__(self,data): self.data=data self.next=Noneclass linklist: def __init__(self): self.head=None self.data=None def isEmpty(self): if self.head: return False else: return True def length(self): if self.isEmpty(): return 0 else: t = self.head n = 1 while t.next: if t.next == self.head: break t = t.next n = n + 1 return n def addhead(self,data): node = Node(data) if self.isEmpty(): self.head = node self.tail = self.head else: node.next = self.head self.head = node self.tail.next = self.head def addtail(self,data): node=Node(data) if self.isEmpty(): self.addhead(data) else: t=self.head n=1 l=self.length() while n<l: n=n+1 t=t.next t.next=node node.next=self.head self.tail=node def delete(self,index): if self.isEmpty(): print("The linked list is empty") else: t = self.head l = self.length() if index == 0: self.head = t.next self.tail.next = self.head elif index == l - 1: n = 1 while n < l - 1: t = t.next n = n + 1 t.next = self.head self.tail = t elif index > l - 1: print("Out of range") elif index < 0: print("Wrong operation") else: n = 1 while n < index - 1: t = t.next n = n + 1 a = t.next.next t.next = a def insert(self,data,index): l = self.length() if index == 0 or self.isEmpty(): self.addhead(data) elif index >= l: self.addtail(data) else: node = Node(data) t = self.head n = 1 while n < index - 1: t = t.next n = n + 1 a = t.next t.next = node node.next = a def search(self,a): t=self.head for i in range(a): t=t.next return t.data def form(self,datalist): self.addhead(datalist[0]) for i in range(1,len(datalist)): self.addtail(datalist[i]) t = self.head while t.next != self.head: t = t.nextn,p=map(int,input().split(' '))data=[]p=p-1for i in range(1,n+1): data.append(i)print(data)datalist=[]for i in range(len(data)): datalist.append(int(data[i]))link=linklist()link.form(datalist)a=pb=[]while link.length()>0: b.append(link.search(a)) link.delete(a) a=a+p while a>=link.length(): a=a-link.length()print(b)
改错如下:
```python
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkList:
def __init__(self):
self.head = None
self.tail = None
def isEmpty(self):
if self.head:
return False
else:
return True
def length(self):
if self.isEmpty():
return 0
else:
t = self.head
n = 1
while t.next:
if t.next == self.head:
break
t = t.next
n += 1
return n
def addhead(self, data):
node = Node(data)
if self.isEmpty():
self.head = node
self.tail = self.head
else:
node.next = self.head
self.head = node
self.tail.next = self.head
def addtail(self, data):
node = Node(data)
if self.isEmpty():
self.addhead(data)
else:
t = self.head
n = 1
l = self.length()
while n < l:
n += 1
t = t.next
t.next = node
node.next = self.head
self.tail = node
def delete(self, index):
if self.isEmpty():
print("The linked list is empty")
else:
t = self.head
l = self.length()
if index == 0:
self.head = t.next
self.tail.next = self.head
elif index == l - 1:
n = 1
while n < l - 1:
t = t.next
n += 1
t.next = self.head
self.tail = t
elif index > l - 1:
print("Out of range")
elif index < 0:
print("Wrong operation")
else:
n = 1
while n < index:
t = t.next
n += 1
a = t.next.next
t.next = a
def insert(self, data, index):
l = self.length()
if index == 0 or self.isEmpty():
self.addhead(data)
elif index >= l:
self.addtail(data)
else:
node = Node(data)
t = self.head
n = 1
while n < index:
t = t.next
n += 1
a = t.next
t.next = node
node.next = a
def search(self, a):
t = self.head
for i in range(a):
t = t.next
return t.data
def form(self, datalist):
self.addhead(datalist[0])
for i in range(1, len(datalist)):
self.addtail(datalist[i])
t = self.head
while t.next != self.head:
t = t.next
n, p = map(int, input().split(' '))
data = [i for i in range(1, n+1)]
print(data)
datalist = []
for i in range(len(data)):
datalist.append(data[i])
link = LinkList()
link.form(datalist)
a = p-1
b = []
while link.length() > 0:
b.append(link.search(a))
link.delete(a)
a += p-1
while a >= link.length():
a -= link.length()
print(b)
```
相关推荐
最新推荐
JSONException:com.alibaba.fastjson.JSONException: expect ‘:’ at 0, actual = 已解决
3. **添加引号**:如果`result`是动态生成的非标准JSON格式,可以尝试在输出前将其包装在方括号中,使其变成一个JSON数组。例如,`result = "[" + result + "]"`。但请注意,这仅仅是一种临时解决方案,因为这可能...
MySQL 启动报错:File ./mysql-bin.index not found (Errcode: 13)
3. **重启MySQL**:更改权限后,尝试再次启动MySQL服务。如果问题仍未解决,可能需要检查其他相关配置文件,如my.cnf,确认二进制日志的位置是否正确设置。 4. **检查配置**:确保MySQL配置文件中的相关配置项,如`...
layui: layer.open加载窗体时出现遮罩层的解决方法
3. **自定义遮罩层样式**: 如果不希望完全去除遮罩层,而是想自定义它的样式,可以在全局 CSS 文件中设置 `.layui-layer-shade` 类的样式,调整颜色、透明度等属性。 4. **控制遮罩层关闭**: 如果希望在特定...
Python requests.post方法中data与json参数区别详解
在使用该方法时,我们可能会遇到两个关键参数:`data`和`json`,它们都用于传递POST请求的数据,但它们之间存在一些重要的区别。 首先,`data`参数通常用于发送表单类型的数据,即`application/x-...
Spring Data JPA实现动态条件与范围查询实例代码
import org.springframework.data.jpa.domain.Specification; public class ProductSpecification implements Specification<Product> { private final Range<Integer> priceRange; public ProductSpecification...
解决Eclipse配置与导入Java工程常见问题
"本文主要介绍了在Eclipse中配置和导入Java工程时可能遇到的问题及解决方法,包括工作空间切换、项目导入、运行配置、构建路径设置以及编译器配置等关键步骤。"
在使用Eclipse进行Java编程时,可能会遇到各种配置和导入工程的问题。以下是一些基本的操作步骤和解决方案:
1. **切换或创建工作空间**:
- 当Eclipse出现问题时,首先可以尝试切换到新的工作空间。通过菜单栏选择`File > Switch Workspace > Other`,然后选择一个新的位置作为你的工作空间。这有助于排除当前工作空间可能存在的配置问题。
2. **导入项目**:
- 如果你有现有的Java项目需要导入,可以选择`File > Import > General > Existing Projects into Workspace`,然后浏览并选择你要导入的项目目录。确保项目结构正确,尤其是`src`目录,这是存放源代码的地方。
3. **配置运行配置**:
- 当你需要运行项目时,如果出现找不到库的问题,可以在Run Configurations中设置。在`Run > Run Configurations`下,找到你的主类,确保`Main class`设置正确。如果使用了`System.loadLibrary()`加载本地库,需要在`Arguments`页签的`VM Arguments`中添加`-Djava.library.path=库路径`。
4. **调整构建路径**:
- 在项目上右键点击,选择`Build Path > Configure Build Path`来管理项目的依赖项。
- 在`Libraries`选项卡中,你可以添加JRE系统库,如果需要更新JRE版本,可以选择`Add Library > JRE System Library`,然后选择相应的JRE版本。
- 如果有外部的jar文件,可以在`Libraries`中选择`Add External Jars`,将jar文件添加到构建路径,并确保在`Order and Export`中将其勾选,以便在编译和运行时被正确引用。
5. **设置编译器兼容性**:
- 在项目属性中,选择`Java Compiler`,可以设置编译器的兼容性级别。如果你的目标是Java 1.6,那么将`Compiler Compliance Level`设置为1.6。注意,不同的Java版本可能有不同的语法特性,因此要确保你的编译器设置与目标平台匹配。
这些步骤可以帮助解决Eclipse中常见的Java项目配置问题。当遇到错误时,记得检查每个环节,确保所有配置都符合你的项目需求。同时,保持Eclipse及其插件的更新,也可以避免很多已知的问题。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
【错误处理与调试】:Python操作MySQL的常见问题与解决之道
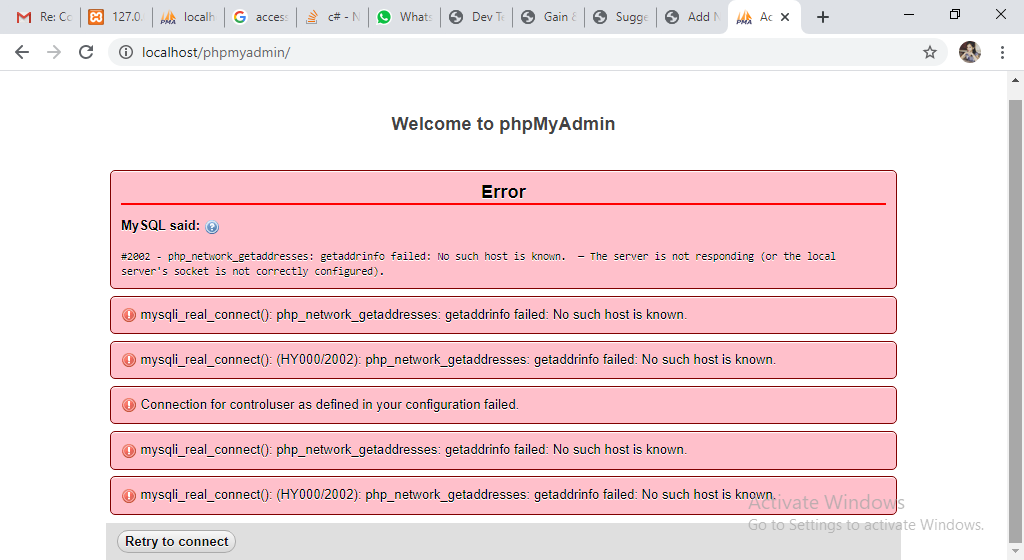
# 1. Python与MySQL交互基础
在当今的数据驱动世界中,Python与MySQL的交互变得尤为重要。作为一款广泛使用的动态编程语言,Python具有简洁明了的语法,且易于学习,它在数据分析、科学计算以及Web开发等多个领域中都表现出色。而MySQL作为流行的开源关系数据库管理系统,广泛应用于网站后端数据存储与管理。
首先,要实现Python与MySQL的交互,
#include<stdio.h> void main() { char c; scanf("%c",&c); print("%d\n",c); }
你提供的代码是C语言的简单程序,用于从标准输入读取一个字符,并试图打印该字符的ASCII码值。然而,程序中存在一个小错误。在C语言中,函数`printf`用于输出,而不是`print`。下面是修正后的代码:
```c
#include<stdio.h>
void main()
{
char c;
scanf("%c", &c);
printf("%d\n", c);
}
```
这段代码的作用如下:
1. 包含标准输入输出库`stdio.h`,它提供了输入输出函数的声明。
2. 定义`main`函数,它是每个C程序的入口点。
3. 声明一个`char`类型的变量`
真空发生器:工作原理与抽吸性能分析
"真空发生器是一种利用正压气源产生负压的设备,适用于需要正负压转换的气动系统,常见应用于工业自动化多个领域,如机械、电子、包装等。真空发生器主要通过高速喷射压缩空气形成卷吸流动,从而在吸附腔内制造真空。其工作原理基于流体力学的连续性和伯努利理想能量方程,通过改变截面面积和流速来调整压力,达到产生负压的目的。根据喷管出口的马赫数,真空发生器可以分为亚声速、声速和超声速三种类型,其中超声速喷管型通常能提供最大的吸入流量和最高的吸入口压力。真空发生器的主要性能参数包括空气消耗量、吸入流量和吸入口处的压力。"
真空发生器是工业生产中不可或缺的元件,其工作原理基于喷管效应,利用压缩空气的高速喷射,在喷管出口形成负压。当压缩空气通过喷管时,由于喷管截面的收缩,气流速度增加,根据连续性方程(A1v1=A2v2),截面增大导致流速减小,而伯努利方程(P1+1/2ρv1²=P2+1/2ρv2²)表明流速增加会导致压力下降,当喷管出口流速远大于入口流速时,出口压力会低于大气压,产生真空。这种现象在Laval喷嘴(先收缩后扩张的超声速喷管)中尤为明显,因为它能够更有效地提高流速,实现更高的真空度。
真空发生器的性能主要取决于几个关键参数:
1. 空气消耗量:这是指真空发生器从压缩空气源抽取的气体量,直接影响到设备的运行成本和效率。
2. 吸入流量:指设备实际吸入的空气量,最大吸入流量是在无阻碍情况下,吸入口直接连通大气时的流量。
3. 吸入口处压力:表示吸入口的真空度,是评估真空发生器抽吸能力的重要指标。
在实际应用中,真空发生器常与吸盘结合,用于吸附和搬运各种物料,特别是对易碎、柔软、薄的非铁非金属材料或球形物体,因其抽吸量小、真空度要求不高的特点而备受青睐。深入理解真空发生器的抽吸机理和影响其性能的因素,对于优化气路设计和选择合适的真空发生器具有重要意义,可以提升生产效率,降低成本,并确保作业过程的稳定性和可靠性。