''''冷夜''' for name,groupmin in df.groupby("年"): # print(name)#1960-2012 groupmin.sort_values(by=['日最低温(0.1℃)'], inplace=True, ascending=False) #ascending=True从-1000到0到1000排列 Lye=groupmin[groupmin["日最低温(0.1℃)"] <groupmin["日最低温(0.1℃)"].quantile(0.1)] #取每年前10% # print( groupmin) b=list(Lye.count()) #年冷夜天数 # print('年冷夜天数:',b) #冬季 groupmin1L_1=Lye[Lye['月']==1] groupmin1L_2=Lye[Lye['月']==2] groupmin1L_12=Lye[Lye['月']==12] aL1=list(groupmin1L_1.count()) aL2=list(groupmin1L_2.count()) aL12=list(groupmin1L_12.count()) # AL=aL1+aL2+aL12 # print(AL) AL=aL1[0]+aL2[0]+aL12[0] # print(AL) #冬季暖夜 array = np.asarray(AL) # print(array) x=array print(x) fig,ax=plt.subplots() y=range(0,36) ax.plot(y,x,'ro-',lw=1,markersize=2,label='line1') plt.show() ,runfile('C:/Users/不想太忙/Desktop/实验1-4_2023年/shiyan11.py', wdir='C:/Users/不想太忙/Desktop/实验1-4_2023年') 37 Traceback (most recent call last): File ~\Desktop\实验1-4_2023年\shiyan11.py:427 ax.plot(y,x,'ro-',lw=1,markersize=2,label='line1') File D:\fanle\lib\site-packages\matplotlib\axes\_axes.py:1743 in plot lines = [*self._get_lines(*args, data=data, **kwargs)] File D:\fanle\lib\site-packages\matplotlib\axes\_base.py:273 in __call__ yield from self._plot_args(this, kwargs) File D:\fanle\lib\site-packages\matplotlib\axes\_base.py:399 in _plot_args raise ValueError(f"x and y must have same first dimension, but " ValueError: x and y must have same first dimension, but have shapes (36,) and (1,)
时间: 2024-03-03 18:53:17 浏览: 114
根据错误信息显示,发现 `x` 和 `y` 的维度不匹配。`x` 的维度是 `(36,)`,而 `y` 的维度是 `(1,)`,所以会报错。
可以通过以下代码修改:
```python
x = np.asarray([AL])
print(x)
fig, ax = plt.subplots()
y = range(0, 36)
ax.plot(y, x[0], 'ro-', lw=1, markersize=2, label='line1')
plt.show()
```
这里使用 `np.asarray()` 将 `AL` 转换为数组,并且将其外面套一个列表,以便 `x` 和 `y` 的维度匹配。
相关问题
##连接list words=np.concatenate(Red_df.cutword) ##统计词频 word_df= pd.DataFrame({"Word":words}) word_stat=word_df.groupby(by=["Word"]).size().reset_index(name="number") word_stat=word_stat.reset_index().sort_values(by="number",ascending=False) word_stat["wordlen"]=word_stat.Word.apply(len) word_stat #去除长度大于5的词 print(np.where(word_stat.Word.apply(len)<5)) word_stat=word_stat.loc[word_stat.Word.apply(len)<5,:] word_stat=word_stat.sort_values(by="number",ascending=False) word_stat
这段代码看起来像是在对一个列表中的词进行词频统计,并且筛选出长度小于5的词。具体的操作包括:
1. 将一个名为`words`的列表中的所有词进行连接,得到一个大字符串。
2. 将这个大字符串转换为一个DataFrame对象,其中每个词作为一行。
3. 对这个DataFrame按照词进行分组,并统计每个词出现的次数。
4. 添加一列`wordlen`,表示每个词的长度。
5. 筛选出长度小于5的词,并按照出现次数进行降序排序。
请注意,这段代码并没有输出任何结果,只是对数据进行了处理。如果需要查看结果,需要在代码末尾添加输出语句。
import pandas as pd df = pd.read_csv('lending.dat') df['year'] = pd.to_datetime(df['date']).dt.year df_book_count = df[['bid', 'title']].drop_duplicates().merge( df.groupby('bid').size().reset_index(name='count'), on='bid') top5_books = pd.DataFrame() for year in df['year'].unique(): df_year = df[df['year'] == year] if len(df_year) >= 5: # 只有当年份至少有 5 本书籍时,才计算前 5 本最受欢迎的书籍 # 按照每个书籍的借阅次数进行排序,并选择前 5 本书籍 df_year_sorted = df_book_count[df_book_count['bid'].isin(df_year['bid'])].sort_values('count', ascending=False).head(5) # 将年份信息添加到 DataFrame 中 df_year_sorted['year'] = year top5_books = pd.concat([top5_books, df_year_sorted], ignore_index=True) # 输出结果 print(top5_books[['year', 'title', 'count']])统计每年借阅量排前五的图书及其借阅量对其进行新颖的可视化展示
对于这个问题,可以使用Python中的数据可视化工具Matplotlib或者Seaborn来实现。以下是一个简单的例子:
```python
import matplotlib.pyplot as plt
import seaborn as sns
# 使用Seaborn设置样式
sns.set_style("whitegrid")
# 绘制柱状图
fig, ax = plt.subplots(figsize=(10, 6))
sns.barplot(x='year', y='count', hue='title', data=top5_books, ax=ax)
# 设置标题和标签
ax.set_title('Top 5 Books Borrowed Each Year')
ax.set_xlabel('Year')
ax.set_ylabel('Number of Borrows')
# 添加图例
ax.legend(loc='upper right')
# 显示图形
plt.show()
```
这个代码会生成一个柱状图,横轴是年份,纵轴是借阅量,每个颜色代表一本图书。你可以根据实际需要调整图形的大小、颜色、字体等参数。
阅读全文
相关推荐
大家在看
二阶有源带通滤波器设计及参数计算.doc
二阶有源带通滤波器设计及参数计算,有详细的计算过程,应用在全国大学生电子设计竞赛的综合测评里,提取基波,三次谐波,五次谐波
基于Android Studio开发的安卓的通讯录管理app
功能包含:新增联系人、编辑联系人、删除联系人、拨打电话、发送短信等相关操作。 资源包含源码:1、apk安装包 2、演示视频 3、 基本安装环境、4、运行文档 5、以及源代码
seadas海洋遥感软件使用说明
这是一个海洋遥感软件seadas的使用文档,希望这个资料能对学习海洋遥感的朋友有所帮助
DX200 使用說明書.pdf
安川機器人DX200系統控制文檔,包含安川机器人操作说明,安裝解說,基础操作,使用和簡易设置说明。
[ExDui自绘]动态创建控件-易语言
功能简单,动态创建控件 排列
方便自己使用的一个小工具
(图中数据仅测试用而已)
最新推荐
幼儿园安全教育管理.pptx
幼儿园安全教育管理
校园招聘模板 (2).pptx
校园招聘模板 (2)
MATLAB SIMULINK搭建分布式驱动电动汽车模型,七自由度整车模型,包括横摆,纵向,侧向,四个轮胎四个自由度等等,转弯制动工况,包括abs模型 资料详细
MATLAB SIMULINK搭建分布式驱动电动汽车模型,七自由度整车模型,包括横摆,纵向,侧向,四个轮胎四个自由度等等,转弯制动工况,包括abs模型。
资料详细。
恒压供水一拖四(3+1)图纸程序 西门子YH100 1.恒压供水系统,采用西门子S 7-200smart PLC,西门子smart 700 IE触摸屏; 2.全新界面,三台主泵一台辅泵,水泵可自
恒压供水一拖四(3+1)图纸程序 西门子YH100
1.恒压供水系统,采用西门子S
7-200smart PLC,西门子smart 700 IE触摸屏;
2.全新界面,三台主泵一台辅泵,水泵可自由屏蔽;
3.采用循环软启功能,PID控制,恒压更稳定,界面更高端;
4.并且有CAD柜体制作图纸,CAD电气图纸,图纸清晰,规范;
5.程序多年稳定运行,比市场上供水控制器无论质量还是外观画面都好几倍;
6.程序后,按图纸制作柜体,电气图纸接线,把PLC程序和触摸屏程序分别下载进去,调试即可使用;
7.可以改开机界面,加公司logo,等
Pokedex: 探索JS开发的口袋妖怪应用程序
资源摘要信息:"Pokedex是一个基于JavaScript的应用程序,主要功能是收集和展示口袋妖怪的相关信息。该应用程序是用JavaScript语言开发的,是一种运行在浏览器端的动态网页应用程序,可以向用户提供口袋妖怪的各种数据,例如名称、分类、属性等。"
首先,我们需要明确JavaScript的作用。JavaScript是一种高级编程语言,是网页交互的核心,它可以在用户的浏览器中运行,实现各种动态效果。JavaScript的应用非常广泛,包括网页设计、游戏开发、移动应用开发等,它能够处理用户输入,更新网页内容,控制多媒体,动画以及各种数据的交互。
在这个Pokedex的应用中,JavaScript被用来构建一个口袋妖怪信息的数据库和前端界面。这涉及到前端开发的多个方面,包括但不限于:
1. DOM操作:JavaScript可以用来操控文档对象模型(DOM),通过DOM,JavaScript可以读取和修改网页内容。在Pokedex应用中,当用户点击一个口袋妖怪,JavaScript将利用DOM来更新页面,展示该口袋妖怪的详细信息。
2. 事件处理:应用程序需要响应用户的交互,比如点击按钮或链接。JavaScript可以绑定事件处理器来响应这些动作,从而实现更丰富的用户体验。
3. AJAX交互:Pokedex应用程序可能需要与服务器进行异步数据交换,而不重新加载页面。AJAX(Asynchronous JavaScript and XML)是一种在不刷新整个页面的情况下,进行数据交换的技术。JavaScript在这里扮演了发送请求、处理响应以及更新页面内容的角色。
4. JSON数据格式:由于JavaScript有内置的JSON对象,它可以非常方便地处理JSON数据格式。在Pokedex应用中,从服务器获取的数据很可能是JSON格式的口袋妖怪信息,JavaScript可以将其解析为JavaScript对象,并在应用中使用。
5. 动态用户界面:JavaScript可以用来创建动态用户界面,如弹出窗口、下拉菜单、滑动效果等,为用户提供更加丰富的交互体验。
6. 数据存储:JavaScript可以使用Web Storage API(包括localStorage和sessionStorage)在用户的浏览器上存储数据。这样,即使用户关闭浏览器或页面,数据也可以被保留,这对于用户体验来说是非常重要的,尤其是对于一个像Pokedex这样的应用程序,用户可能希望保存他们查询过的口袋妖怪信息。
此外,该应用程序被标记为“JavaScript”,这意味着它可能使用了JavaScript的最新特性或者流行的库和框架,例如React、Vue或Angular。这些现代的JavaScript框架能够使前端开发更加高效、模块化和易于维护。例如,React允许开发者构建可复用的UI组件,Vue则提供了数据驱动和组件化的编程方式,而Angular则是一个全面的前端框架,提供了模板、依赖注入、客户端路由等功能。
在文件名称列表中提到了"Pokedex-main",这很可能是应用程序的主文件或者项目的根目录名称。在这种情况下,主文件可能包含程序的入口点,即整个JavaScript应用程序开始执行的地方,它通常会包含对其他JavaScript文件的引用,以及初始化应用程序的代码。
综上所述,Pokedex作为一个JavaScript应用程序,涉及了前端开发的多个关键技术和概念。通过JavaScript,开发者能够实现一个功能丰富、响应用户交互、动态更新内容的应用程序,为用户提供口袋妖怪的详细信息和互动体验。
【提升R-Studio恢复效率】:RAID 5数据恢复的高级技巧与成功率
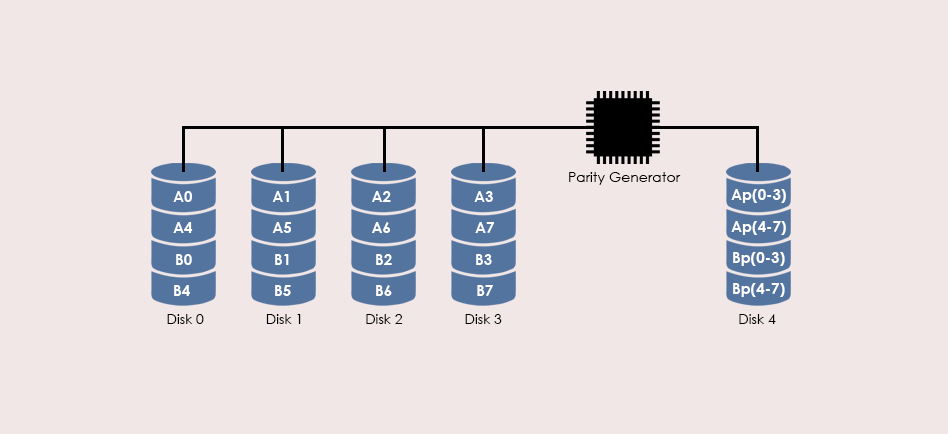
# 摘要
RAID 5作为一种广泛应用于数据存储的冗余阵列技术,能够提供较好的数据保护和性能平衡。本文首先概述了RAID 5数据恢复的重要性,随后介绍了RAID 5的基础理论,包括其工作原理、故障类型及数据恢复前的准备工作。接着,文章深入探讨了提升RAID 5数据恢复成功率的高级技巧,涵盖了硬件级别和软件工具的应用,以及文件系统结构和数据一致性检查。通过实际案例分析,
帮我写一段Python代码:sin波生成,设定rate,fin,size,幅值
当然可以。在Python中,我们可以使用`numpy`库来创建正弦波,并通过`tqdm`库添加进度条。下面是一个简单的示例代码,它会生成指定频率(rate)、持续时间(fin),以及样本大小(size)的正弦波,幅度可以自定义:
```python
import numpy as np
from tqdm import trange
# 定义函数生成sin波
def generate_sine_wave(rate=44100, fin=5, size=None, amplitude=1):
# 检查参数是否合理
if size is None:
size =
Laravel实用工具包:laravel-helpers概述
资源摘要信息:"Laravel开发-laravel-helpers 是一个针对Laravel框架开发者的实用程序包,它提供了许多核心功能的便捷访问器(getters)和修改器(setters)。这个包的设计初衷是为了提高开发效率,使得开发者能够快速地使用Laravel框架中常见的一些操作,而无需重复编写相同的代码。使用此包可以简化代码量,减少出错的几率,并且当开发者没有提供自定义实例时,它将自动回退到Laravel的原生外观,确保了功能的稳定性和可用性。"
知识点:
1. Laravel框架概述:
Laravel是一个基于PHP的开源Web应用框架,遵循MVC(Model-View-Controller)架构模式。它旨在通过提供一套丰富的工具来快速开发Web应用程序,同时保持代码的简洁和优雅。Laravel的特性包括路由、会话管理、缓存、模板引擎、数据库迁移等。
2. Laravel核心包:
Laravel的核心包是指那些构成框架基础的库和组件。它们包括但不限于路由(Routing)、请求(Request)、响应(Response)、视图(View)、数据库(Database)、验证(Validation)等。这些核心包提供了基础功能,并且可以被开发者在项目中广泛地使用。
3. Laravel的getters和setters:
在面向对象编程(OOP)中,getters和setters是指用来获取和设置对象属性值的方法。在Laravel中,这些通常指的是辅助函数或者服务容器中注册的方法,用于获取或设置框架内部的一些配置信息和对象实例。
4. Laravel外观模式:
外观(Facade)模式是软件工程中常用的封装技术,它为复杂的子系统提供一个简化的接口。在Laravel框架中,外观模式广泛应用于其核心类库,使得开发者可以通过简洁的类方法调用来执行复杂的操作。
5. 使用laravel-helpers的优势:
laravel-helpers包作为一个辅助工具包,它将常见的操作封装成易于使用的函数,使开发者在编写Laravel应用时更加便捷。它省去了编写重复代码的麻烦,降低了项目的复杂度,从而加快了开发进程。
6. 自定义实例和回退机制:
在laravel-helpers包中,如果开发者没有提供特定的自定义实例,该包能够自动回退到使用Laravel的原生外观。这种设计使得开发者在不牺牲框架本有功能的前提下,能够享受到额外的便利性。
7. Laravel开发实践:
在实际的开发过程中,开发者可以通过引入laravel-helpers包来简化代码的编写。例如,该包可能提供了一系列用于验证输入数据的快速方法,或者是一些处理常见任务的辅助函数,如快速生成响应、执行数据库查询、发送邮件等。
8. 开源贡献和社区支持:
laravel-helpers作为一个开源包,它的维护和更新依赖于社区的贡献。开发者在使用过程中也可以参与到包的开发与改进中,为Laravel社区做出贡献,并从社区中获取帮助和反馈。
总结而言,laravel-helpers包通过提供一系列的getters和setters工具函数,极大地提升了Laravel开发的效率与便利性。它不仅遵循了Laravel的核心设计理念,还通过回退机制保证了与框架原生功能的兼容性。对于希望优化其开发流程的Laravel开发者来说,这无疑是一个宝贵的资源。
【R-Studio技术路径】:从RAID 5数据恢复基础到高级操作

# 摘要
随着信息技术的发展,数据丢失问题日益突出,RAID 5作为常见的数据存储解决方案,其数据恢复技术显得尤为重要。本文首先介绍了RAID 5数据恢复的基础知识,然后详细解析了R-Studio软件的界面和核心功能,重点探讨了其在RAID 5数据恢复中的应用实践,包括磁盘镜像创建、数据提取、数据重组策略及一致性验证。进一步,本文还涉及了R-Studio的进阶技术,如脚本编
如果我想要排除从这周周一开始的数据,应该怎么改,<date_sub(next_day(now(), 'Mon'), 7)吗?
要排除从这周周一开始的数据,你可以使用以下SQL语句:
```sql
WHERE date_column < date_sub(next_day(date_sub(current_date, dayofweek(current_date) - 2), 'Mon'), 7)
```
解释一下这个语句:
1. `current_date` 获取当前日期。
2. `dayofweek(current_date) - 2` 计算出本周周一的日期。
3. `date_sub(current_date, dayofweek(current_date) - 2)` 获取本周周一的日期。
4. `nex