启动PM2时报错,自定义的配置pid_file不生效,报错信息:no such file or directory, open '/home/maoyan/.pm2/pm2.pid'
时间: 2024-01-25 10:02:59 浏览: 21
这个错误信息提示说找不到 '/home/maoyan/.pm2/pm2.pid' 这个文件,可能是因为 PM2 在启动时默认会在用户的 home 目录下生成一个 .pm2 文件夹,并在该文件夹下创建 pm2.pid 文件来存储进程的 PID。但是,由于您自定义了 pid_file 的路径,PM2 就无法在默认的路径下找到这个文件了。
解决方法:
1. 确认自定义的 pid_file 路径是否正确。
2. 如果路径正确,请手动创建该文件并授权。
3. 如果路径不正确,则修改配置文件中的 pid_file 路径,保证路径正确。
4. 最后重新启动 PM2,检查是否能正常启动。
相关问题
server: { cors: true, open: true, // port: 9999, proxy: { '^/api': { target: "https://m.maoyan.com/ajax", changeOrigin: true, rewrite: (path) => path.replace(/^\/api/, ""), } } }是什么
这段代码是在使用 Vite 构建工具时,配置启动的本地开发服务器时设置的选项,具体含义如下:
- `cors: true`: 允许跨域请求,即允许在本地启动的开发服务器向其他域名的服务器发起请求。
- `open: true`: 自动打开浏览器。
- `proxy`: 代理设置,用于将本地请求转发到远程服务器,方便开发调试。
- `'^/api'`: 匹配以 `/api` 开头的请求路径。
- `target: "https://m.maoyan.com/ajax"`: 将匹配到的请求转发到目标服务器 https://m.maoyan.com/ajax。
- `changeOrigin: true`: 将代理的源地址更改为目标地址,即代理请求的 Host 头部会设置为目标地址,而不是源地址。
- `rewrite: (path) => path.replace(/^\/api/, "")`: 重写请求路径,将匹配到的 `/api` 前缀替换为空字符串,即将请求路径中的 `/api` 前缀去掉,以便向目标服务器发起正确的请求。
总的来说,这段代码的作用是在本地启动一个开发服务器,并将以 `/api` 开头的请求代理到目标服务器 https://m.maoyan.com/ajax,以方便在开发时调试本地代码。
请从知名的电影评论网站猫眼上面获取排名前列的电影名称、导演和演员、评分、排名、图片等信息: 1.目标网站: https://movie.douban.com/;
很抱歉,您的问题似乎有些混淆。题目中提到的是猫眼电影网站,而您提供的链接是豆瓣电影网站。如果您需要从猫眼电影网站上获取排名前列的电影信息,可以使用 Python 的 requests 库和 BeautifulSoup 库进行网络爬虫编程,具体步骤如下:
1. 打开猫眼电影网站 https://maoyan.com/,找到排行榜页面 https://maoyan.com/board。
2. 使用 requests 库发送 GET 请求获取页面内容,代码如下:
```
import requests
url = 'https://maoyan.com/board'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
html = response.text
```
3. 使用 BeautifulSoup 库解析页面内容,获取需要的电影信息,代码如下:
```
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
movies = soup.find_all('div', {'class': 'movie-item-info'})
for movie in movies:
name = movie.find('a').text.strip()
actors = movie.find('p', {'class': 'star'}).text.strip()
release_time = movie.find('p', {'class': 'releasetime'}).text.strip()
score = movie.find('i', {'class': 'integer'}).text + movie.find('i', {'class': 'fraction'}).text
rank = movie.find('i', {'class': 'board-index'}).text
print(rank, name, actors, release_time, score)
```
4. 如果需要获取电影海报图片,可以使用 requests 库下载图片,代码如下:
```
img_url = movie.find('img')['data-src']
response = requests.get(img_url, headers=headers)
with open(f'{name}.jpg', 'wb') as f:
f.write(response.content)
```
注意:在进行网络爬虫编程时,需要遵守网站的相关规定和法律法规,不得用于商业用途和侵犯用户隐私等行为。
相关推荐
用正则表达式.?board-index.?>(.?).?data-src="(.?)".?name.?a.?>(.?)
.?star.?>(.?).?releasetime.?>(.?).?integer.?>(.?).?fraction.?>(.?).?爬取猫眼电影排行:爬取猫眼电影TOP100的所有信息。网址:https://www.maoyan.com/board/4 用正则表达式.?board-index.?>(.?).?data-src="(.?)".?name.?a.?>(.?)
.?star.?>(.?).?releasetime.?>(.?).?integer.?>(.?).?fraction.?>(.?).?爬取猫眼电影TOP100的所有信息。网址:https://www.maoyan.com/board/4 最新推荐
网络安全network-security-mind-map.zip
【资源简介】
第一章 网络安全概述
第二章 扫描与防御技术
第三章 网络监听及防御技术
第四章 口令破解与防御技术
第五章 欺骗攻击及防御技术
第六章 拒绝服务攻击与防御技术
第七章 缓冲区溢出攻击及防御技术
第八章 Web攻击及防御技术
第九章 木马攻击与防御技术
第十章 计算机病毒
第十一章 网络安全发展及未来
分布式锁与信号量.md
附件是分布式锁与信号量介绍和对比,文件绿色安全,请大家放心下载,仅供交流学习使用,无任何商业目的!
zigbee-cluster-library-specification
最新的zigbee-cluster-library-specification说明文档。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MATLAB结构体与对象编程:构建面向对象的应用程序,提升代码可维护性和可扩展性
# 1. MATLAB结构体基础**
MATLAB结构体是一种数据结构,用于存储和组织相关数据。它由一系列域组成,每个域都有一个名称和一个值。结构体提供了对数据的灵活访问和管理,使其成为组织和处理复杂数据集的理想选择。
MATLAB中创建结构体非常简单,使用struct函数即可。例如:
```matlab
myStruct
详细描述一下STM32F103C8T6怎么与DHT11连接
STM32F103C8T6可以通过单总线协议与DHT11连接。连接步骤如下:
1. 将DHT11的VCC引脚连接到STM32F103C8T6的5V电源引脚;
2. 将DHT11的GND引脚连接到STM32F103C8T6的GND引脚;
3. 将DHT11的DATA引脚连接到STM32F103C8T6的GPIO引脚,可以选择任一GPIO引脚,需要在程序中配置;
4. 在程序中初始化GPIO引脚,将其设为输出模式,并输出高电平,持续至少18ms,以激活DHT11;
5. 将GPIO引脚设为输入模式,等待DHT11响应,DHT11会先输出一个80us的低电平,然后输出一个80us的高电平,
JSBSim Reference Manual
JSBSim参考手册,其中包含JSBSim简介,JSBSim配置文件xml的编写语法,编程手册以及一些应用实例等。其中有部分内容还没有写完,估计有生之年很难看到完整版了,但是内容还是很有参考价值的。
"互动学习:行动中的多样性与论文攻读经历"
多样性她- 事实上SCI NCES你的时间表ECOLEDO C Tora SC和NCESPOUR l’Ingén学习互动,互动学习以行动为中心的强化学习学会互动,互动学习,以行动为中心的强化学习计算机科学博士论文于2021年9月28日在Villeneuve d'Asq公开支持马修·瑟林评审团主席法布里斯·勒菲弗尔阿维尼翁大学教授论文指导奥利维尔·皮耶昆谷歌研究教授:智囊团论文联合主任菲利普·普雷教授,大学。里尔/CRISTAL/因里亚报告员奥利维耶·西格德索邦大学报告员卢多维奇·德诺耶教授,Facebook /索邦大学审查员越南圣迈IMT Atlantic高级讲师邀请弗洛里安·斯特鲁布博士,Deepmind对于那些及时看到自己错误的人...3谢谢你首先,我要感谢我的两位博士生导师Olivier和Philippe。奥利维尔,"站在巨人的肩膀上"这句话对你来说完全有意义了。从科学上讲,你知道在这篇论文的(许多)错误中,你是我可以依
MATLAB结构体与数据库交互:无缝连接数据存储与处理,实现数据管理自动化
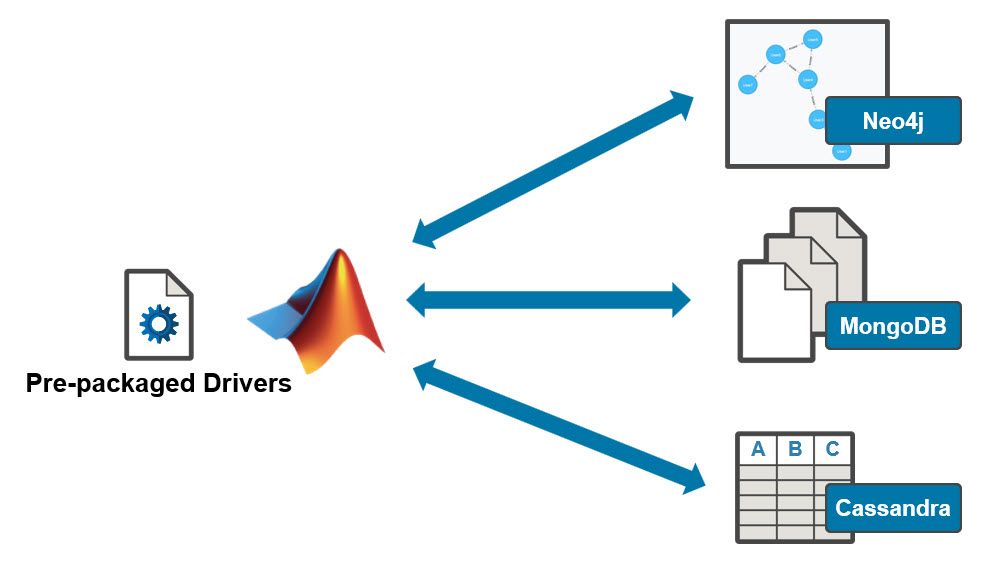
# 1. MATLAB结构体与数据库交互概述**
MATLAB结构体与数据库交互是一种强大的
Link your Unity
project to C# script in Visual Studio. Can you provide me with some guidance on this?
Yes, I can definitely help you with that! To link your Unity project to C# script in Visual Studio, you first need to make sure that you have both Unity and Visual Studio installed on your computer. Then, you can