train["Age"] = train["Age"].fillna(-0.5) test["Age"] = test["Age"].fillna(-0.5) bins = [-1, 0, 5, 12, 18, 24, 35, 60, np.inf] #将年龄分为八组 labels = ['Unknown', 'Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Senior'] train['AgeGroup'] = pd.cut(train["Age"], bins, labels = labels) test['AgeGroup'] = pd.cut(test["Age"], bins, labels = labels)
时间: 2024-01-20 20:02:20 浏览: 74
这段代码对训练数据集 `train` 和测试数据集 `test` 中的 `Age` 列进行处理,将其分成 8 个年龄段,并新建一个名为 `AgeGroup` 的列来存储每个乘客所属的年龄段。具体来说,代码中的操作包括:
1. 使用 `.fillna(-0.5)` 将缺失值填充为 -0.5,这是因为后面使用 `pd.cut()` 函数时需要将缺失值分到“未知”年龄段,而 -0.5 可以作为一个特殊的标记。
2. 定义一个数组 `bins`,其中包含了每个年龄段的上下限。这里使用了一个特殊的值 `np.inf` 表示正无穷大,以确保最后一个年龄段包含所有剩余的年龄。
3. 定义一个数组 `labels`,其中包含了每个年龄段对应的标签,即 "Unknown"(未知)、"Baby"(婴儿)、"Child"(儿童)、"Teenager"(少年)、"Student"(学生)、"Young Adult"(年轻成年人)、"Adult"(成年人)和 "Senior"(老年人)。
4. 使用 `pd.cut()` 函数将 `Age` 列的数据按照 `bins` 中的上下限进行分组,并将每个分组对应的标签存储到 `AgeGroup` 列中。
这个操作可以将连续型的年龄列转换为离散型的年龄段,对于一些机器学习算法来说,这种离散化的处理方式可能更加适用。
相关问题
import numpy as np import pandas as pd import matplotlib.pyplot as plt from decision_tree_classifier import DecisionTreeClassifier from random_forest_classifier import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score #读取数据 df = pd.read_csv('adult.csv',encoding='gbk') df.head() col_names=['age','workclass','fnlwgt','education','educational-num','marital-status','occupation','relationship','race','gender','capital-gain','capital-loss','hours-per-week','native-country','income'] df.columns = col_names categorical = ['workclass','education','marital-status','occupation','relationship','race','gender','native-country','income'] # print(f'分类特征:\n{categorical}') # for var in categorical: # print(df[var].value_counts()) #缺失值处理 df['occupation'].replace('?', np.NaN, inplace=True) df['workclass'].replace('?', np.NaN, inplace=True) df['native-country'].replace('?', np.NaN, inplace=True) df.isnull().sum() df['income'].value_counts() plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] df.isnull().sum() df['workclass'].fillna(df['workclass'].mode()[0], inplace=True) df['occupation'].fillna(df['occupation'].mode()[0], inplace=True) df['native-country'].fillna(df['native-country'].mode()[0], inplace=True) df = pd.get_dummies(df,columns=categorical,drop_first=True) print(df.head()) y = df.loc[:,'income_>50K'] X = np.array(df.loc[:,['age', 'educational-num', 'hours-per-week']]) y = np.array(y) x = np.array(X) y = y.reshape(-1,1) X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1234) from sklearn.ensemble import RandomForestClassifier rtree = RandomForestClassifier(n_estimators=100,max_depth=5,max_features=0.2,max_samples=50,random_state=1234) X_train = np.array(X_train) rtree.fit(X_train, y_train) X_test = np.array(X_test) y_pred = rtree.predict(X_test) accuracy = accuracy_score(y_test,y_pred) print("accuracy={}".format((accuracy)))我这个代码如何更换特征向量
如果想更换特征向量,只需要修改以下代码段:
```
X = np.array(df.loc[:,['age', 'educational-num', 'hours-per-week']])
y = np.array(y)
```
将 `['age', 'educational-num', 'hours-per-week']` 替换为你想要的特征向量即可。注意要保证特征向量的格式正确,即为一个列表形式。另外,如果更换特征向量后发现模型表现不佳,可以再考虑增加或减少特征,或者对特征进行预处理等操作。
train = pd.read_csv('train.csv') #读取数值 train = train.replace(np.NaN,0) #缺失值处理 train = train.dropna() #丢弃空值 test = pd.read_csv('test.csv') #读取数值 test = test.replace(np.NaN,0) #缺失值处理 test = test.dropna() #丢弃空值 y_train= train.loc[:,'Survived'] x_train= train.loc[:,['PassengerId','Pclass','Age','Fare']] x_train['male'] = train['Sex'].map({'male':1,'female':0}) y_test= test.loc[:,'Survived'] x_test= test.loc[:,['PassengerId','Pclass','Age','Fare']] x_test['male'] = test['Sex'].map({'male':1,'female':0})
这段代码的功能是读取两个 csv 文件,分别为 `train.csv` 和 `test.csv`,然后对缺失值进行处理,使用 `dropna()` 丢弃空值。接下来,将 `train` 的标签值 `Survived` 赋给 `y_train`,将 `train` 中的 `PassengerId`, `Pclass`, `Age`, `Fare` 的数据赋给 `x_train`,并将 `Sex` 中的 `male` 映射为 1,`female` 映射为 0。最后,将 `test` 的标签值 `Survived` 赋给 `y_test`,将 `test` 中的 `PassengerId`, `Pclass`, `Age`, `Fare` 的数据赋给 `x_test`,并将 `Sex` 中的 `male` 映射为 1,`female` 映射为 0。这段代码主要是针对一个数据集进行数据预处理,从而为后续的机器学习模型提供干净的数据。
相关推荐
最新推荐
AzurePyblobLogging-1.0.8-py3-none-any.whl.zip
AzurePyblobLogging-1.0.8-py3-none-any.whl.zip
解决Eclipse配置与导入Java工程常见问题
"本文主要介绍了在Eclipse中配置和导入Java工程时可能遇到的问题及解决方法,包括工作空间切换、项目导入、运行配置、构建路径设置以及编译器配置等关键步骤。"
在使用Eclipse进行Java编程时,可能会遇到各种配置和导入工程的问题。以下是一些基本的操作步骤和解决方案:
1. **切换或创建工作空间**:
- 当Eclipse出现问题时,首先可以尝试切换到新的工作空间。通过菜单栏选择`File > Switch Workspace > Other`,然后选择一个新的位置作为你的工作空间。这有助于排除当前工作空间可能存在的配置问题。
2. **导入项目**:
- 如果你有现有的Java项目需要导入,可以选择`File > Import > General > Existing Projects into Workspace`,然后浏览并选择你要导入的项目目录。确保项目结构正确,尤其是`src`目录,这是存放源代码的地方。
3. **配置运行配置**:
- 当你需要运行项目时,如果出现找不到库的问题,可以在Run Configurations中设置。在`Run > Run Configurations`下,找到你的主类,确保`Main class`设置正确。如果使用了`System.loadLibrary()`加载本地库,需要在`Arguments`页签的`VM Arguments`中添加`-Djava.library.path=库路径`。
4. **调整构建路径**:
- 在项目上右键点击,选择`Build Path > Configure Build Path`来管理项目的依赖项。
- 在`Libraries`选项卡中,你可以添加JRE系统库,如果需要更新JRE版本,可以选择`Add Library > JRE System Library`,然后选择相应的JRE版本。
- 如果有外部的jar文件,可以在`Libraries`中选择`Add External Jars`,将jar文件添加到构建路径,并确保在`Order and Export`中将其勾选,以便在编译和运行时被正确引用。
5. **设置编译器兼容性**:
- 在项目属性中,选择`Java Compiler`,可以设置编译器的兼容性级别。如果你的目标是Java 1.6,那么将`Compiler Compliance Level`设置为1.6。注意,不同的Java版本可能有不同的语法特性,因此要确保你的编译器设置与目标平台匹配。
这些步骤可以帮助解决Eclipse中常见的Java项目配置问题。当遇到错误时,记得检查每个环节,确保所有配置都符合你的项目需求。同时,保持Eclipse及其插件的更新,也可以避免很多已知的问题。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
【错误处理与调试】:Python操作MySQL的常见问题与解决之道
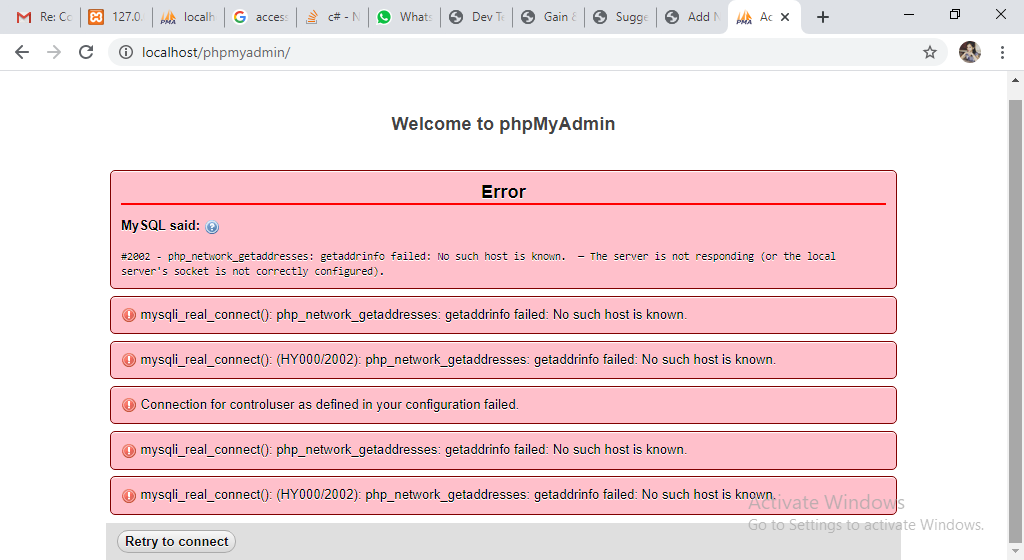
# 1. Python与MySQL交互基础
在当今的数据驱动世界中,Python与MySQL的交互变得尤为重要。作为一款广泛使用的动态编程语言,Python具有简洁明了的语法,且易于学习,它在数据分析、科学计算以及Web开发等多个领域中都表现出色。而MySQL作为流行的开源关系数据库管理系统,广泛应用于网站后端数据存储与管理。
首先,要实现Python与MySQL的交互,
#include<stdio.h> void main() { char c; scanf("%c",&c); print("%d\n",c); }
你提供的代码是C语言的简单程序,用于从标准输入读取一个字符,并试图打印该字符的ASCII码值。然而,程序中存在一个小错误。在C语言中,函数`printf`用于输出,而不是`print`。下面是修正后的代码:
```c
#include<stdio.h>
void main()
{
char c;
scanf("%c", &c);
printf("%d\n", c);
}
```
这段代码的作用如下:
1. 包含标准输入输出库`stdio.h`,它提供了输入输出函数的声明。
2. 定义`main`函数,它是每个C程序的入口点。
3. 声明一个`char`类型的变量`
真空发生器:工作原理与抽吸性能分析
"真空发生器是一种利用正压气源产生负压的设备,适用于需要正负压转换的气动系统,常见应用于工业自动化多个领域,如机械、电子、包装等。真空发生器主要通过高速喷射压缩空气形成卷吸流动,从而在吸附腔内制造真空。其工作原理基于流体力学的连续性和伯努利理想能量方程,通过改变截面面积和流速来调整压力,达到产生负压的目的。根据喷管出口的马赫数,真空发生器可以分为亚声速、声速和超声速三种类型,其中超声速喷管型通常能提供最大的吸入流量和最高的吸入口压力。真空发生器的主要性能参数包括空气消耗量、吸入流量和吸入口处的压力。"
真空发生器是工业生产中不可或缺的元件,其工作原理基于喷管效应,利用压缩空气的高速喷射,在喷管出口形成负压。当压缩空气通过喷管时,由于喷管截面的收缩,气流速度增加,根据连续性方程(A1v1=A2v2),截面增大导致流速减小,而伯努利方程(P1+1/2ρv1²=P2+1/2ρv2²)表明流速增加会导致压力下降,当喷管出口流速远大于入口流速时,出口压力会低于大气压,产生真空。这种现象在Laval喷嘴(先收缩后扩张的超声速喷管)中尤为明显,因为它能够更有效地提高流速,实现更高的真空度。
真空发生器的性能主要取决于几个关键参数:
1. 空气消耗量:这是指真空发生器从压缩空气源抽取的气体量,直接影响到设备的运行成本和效率。
2. 吸入流量:指设备实际吸入的空气量,最大吸入流量是在无阻碍情况下,吸入口直接连通大气时的流量。
3. 吸入口处压力:表示吸入口的真空度,是评估真空发生器抽吸能力的重要指标。
在实际应用中,真空发生器常与吸盘结合,用于吸附和搬运各种物料,特别是对易碎、柔软、薄的非铁非金属材料或球形物体,因其抽吸量小、真空度要求不高的特点而备受青睐。深入理解真空发生器的抽吸机理和影响其性能的因素,对于优化气路设计和选择合适的真空发生器具有重要意义,可以提升生产效率,降低成本,并确保作业过程的稳定性和可靠性。
"互动学习:行动中的多样性与论文攻读经历"
多样性她- 事实上SCI NCES你的时间表ECOLEDO C Tora SC和NCESPOUR l’Ingén学习互动,互动学习以行动为中心的强化学习学会互动,互动学习,以行动为中心的强化学习计算机科学博士论文于2021年9月28日在Villeneuve d'Asq公开支持马修·瑟林评审团主席法布里斯·勒菲弗尔阿维尼翁大学教授论文指导奥利维尔·皮耶昆谷歌研究教授:智囊团论文联合主任菲利普·普雷教授,大学。里尔/CRISTAL/因里亚报告员奥利维耶·西格德索邦大学报告员卢多维奇·德诺耶教授,Facebook /索邦大学审查员越南圣迈IMT Atlantic高级讲师邀请弗洛里安·斯特鲁布博士,Deepmind对于那些及时看到自己错误的人...3谢谢你首先,我要感谢我的两位博士生导师Olivier和Philippe。奥利维尔,"站在巨人的肩膀上"这句话对你来说完全有意义了。从科学上讲,你知道在这篇论文的(许多)错误中,你是我可以依
Python多线程与MySQL:数据一致性和性能优化挑战的解决方案

# 1. 多线程与MySQL基础
本章将探讨多线程编程与MySQL数据库的基础知识,为后续章节涉及的复杂主题打下坚实的理论基础。我们将首先了解线程的定义、作用以及如何在应用中实现多线程。随后,我们将介绍MySQL作为数据库系统的作用及其基本操作。
## 1.1
DATEDIFF(u1.actmonth, t2.latest_usage) = 1
这个表达式`DATEDIFF(u1.actmonth, t2.latest_usage) = 1`是在比较两个日期之间的月差(假设`actmonth`字段表示第一个日期的月份,而`latest_usage`字段表示第二个日期的最新使用时间)。如果结果等于1,这意味着第一个日期比第二个日期晚了一个月。
具体来说,`DATEDIFF`通常是一个SQL函数,用于计算两个日期间的差异(在这种情况下是按月计数),如果`DATEDIFF(u1.actmonth, t2.latest_usage)`的结果为1,那意味着u1的活动发生在t2最近一次使用的日期之后一个月。
举个例子:
```sql
SEL
爱立信RBS6201开站流程详解
"爱立信RBS6201开站流程"
爱立信RBS6201是一款用于移动通信的基站系统,主要用于提供2G GSM 900MHz频段的服务。开站流程是建立和配置这样一个站点的关键步骤,涉及到硬件安装、软件配置以及系统测试。以下是对该流程的详细解释:
1. **准备工作**
- **工具准备**:确保拥有必要的工具,如安装OMT40F软件的笔记本电脑、CF卡读卡器、六角螺丝刀、发光二极管以及安装锁频软件的手机,这些都是进行安装和调试的基础。
- **知识准备**:了解RBS6201模块结构,例如Optix PTN950的相关知识,这有助于理解设备的内部工作原理。
- **相关制度**:遵守电信行业的安全规定和操作规程,确保操作的合规性。
2. **数据包模板制作**
- 使用OMT软件创建IDB(Install Data Base),这是配置网络的基础。
- 配置Transmission Setup,选择E1接口,并在Cabinet Setup中设定机柜类型为6201RUS,电源系统通常为-48VDC,气候系统为标准设置。
- 定义Antenna Sector Setup,依据实际需求选择扇区数量、频率和RUS设置。
- 在TRX Mapping Setup中设置SiteCell Configuration,例如选择222。
- 通过RBS configuration wizard设定所有参数,包括SAU、RUS、DUG等的位置,SAU告警设置以及主从DUG配置。
3. **硬件检查**
- **综合配线架**:检查传输线的连接,确保正确无误。
- **BTS配电**:验证电源供应,确保所有设备能够正常供电。
- **PTN**:确认PTN设备的配置与连接,它是传输网络的关键部分。
- **RUS&DUG**:检查RUS(Remote Unit Site)和DUG(Digital Unit Group)的安装和连接状态。
4. **传输检测**
- **环回检测**:通过环回测试确认传输线路的完好性,观察ETA指示灯是否长亮。
- **收发检测**:使用发光二极管进行收发功能的测试,确保信号传输正常。
- **BSC端确认**:与BSC(Base Station Controller)端的工程师协作,通过拔插传输线头进行通信验证。
5. **数据包创建**
- 按照特定顺序关闭RUS、DUG和风扇等模块,然后断开EC(Equipment Cabinet)和ET(Equipment Terminal)的连接,以便进行数据包的创建和更新。
整个流程强调了从硬件安装到软件配置的全面检查,以及与网络核心部分的通信验证,确保RBS6201基站可以顺利接入网络并提供服务。每个步骤都需要精确执行,任何遗漏或错误都可能导致站点无法正常运行。在执行这些步骤时,操作人员应具备相应的专业知识,并遵循操作手册,以保证系统的稳定性和可靠性。