混合熵与混合焓的混合效应
时间: 2024-04-24 17:13:22 浏览: 9
混合熵和混合焓都是描述混合物性质的物理量。混合熵是指将两种或更多的物质混合在一起时,系统总熵的变化量。混合焓是指将两种或更多的物质混合在一起时,系统总焓的变化量。
混合效应指的是,当将两种或更多的物质混合在一起时,混合物的混合熵和混合焓的值可能会有所不同于单个组分的值的简单加和。这是因为混合过程中,各组分之间可能会发生相互作用,导致混合物的物理性质发生变化。
例如,在将两种液体混合时,它们之间的相互作用可能会导致混合物的体积、密度、热容等物理性质与简单加和值不同。这种混合效应在物理、化学、生物等领域中都具有重要的应用。
相关问题
sas线性混合效应模型
SAS中的线性混合效应模型是一种统计模型,用于处理具有多层次结构和相关性的数据。它可以用来分析个体间的差异以及组间的变异。在SAS中,可以使用PROC MIXED来拟合线性混合效应模型。
线性混合效应模型包含固定效应和随机效应。固定效应是指与研究问题直接相关的变量,例如处理组别或处理水平。随机效应是指在样本中随机选择的因素,例如受试者或观察单位的随机效应。
使用PROC MIXED,您可以通过指定适当的模型语句来定义线性混合效应模型。例如,您可以使用CLASS语句定义分类变量,使用MODEL语句定义固定效应和随机效应,使用RANDOM语句定义随机效应结构。
然后,您可以运行PROC MIXED来拟合模型,并获得参数估计、方差分析和协方差矩阵等统计结果。PROC MIXED还提供了许多选项和命令,以帮助您进行模型诊断和解释结果。
请注意,这只是对SAS中线性混合效应模型的简要介绍,更详细的信息和示例可以在SAS文档和参考资料中找到。
r语言混合效应模型解读
R语言混合效应模型是用于分析具有多个层次结构的数据的统计模型。它是一种广义线性模型的扩展,主要用于处理数据中存在的层次结构和相关性。
混合效应模型通常包括固定效应和随机效应。固定效应是指在整个样本中保持不变的变量,而随机效应是指在样本中变化的变量。混合效应模型中的随机效应可以捕捉到样本中的层次结构,例如多层次的实验设计或者交叉分类设计。
解读R语言混合效应模型的过程通常包括以下步骤:
首先,需要了解数据的结构并确定需要建模的层次结构。这可以通过检查数据集中的变量来实现。
其次,使用R语言的lme4包或nlme包中的相应函数创建混合效应模型。根据数据的特征,可以选择线性混合效应模型(LMM)或广义线性混合效应模型(GLMM)。
然后,需要对模型进行估计和拟合。通过使用最大似然估计或贝叶斯方法,可以获得各种固定效应和随机效应的估计值。
在得到模型拟合结果后,可以使用summary函数检查模型的显著性和适合度。
最后,可以使用coef函数获取模型的系数估计值,并解读这些估计值来得到关于各项效应的结果。
总而言之,R语言混合效应模型是一种强大的统计工具,用于分析层次结构数据。通过对模型的解读和结果的分析,我们可以了解到在数据集中存在的层次结构与变量之间的关系。
相关推荐
最新推荐
混合云管理平台的研究与实践.docx
混合云管理平台聚焦于异构云资源管理、自动化运维管理、可定制工作流的平台。最终为用户提供一体化的资源管理,自动化资源交付,并为用户提供了方便获取资源的途径。用户可以通过租户自服务门户获取资源并在资源上...
企业混合云架构设计及解决方案.pdf
混合云行业发展趋势分析、为什么使用混合云及关键挑战、阿里云混合云整体解决方案、阿里云混合云典型客户案例
app开发之原生开发、H5开发和混合开发的区别
主要介绍了app开发之原生开发、H5开发和混合开发的区别,需要的朋友可以参考下
C16系列小型化16线混合固态激光雷达使用说明书V1.3.pdf
C16系列小型化16线混合固态激光雷达使用说明书V1.3,里面暂时只有手册,后续我会把驱动,windows显示软件,以及附带的其他数据上传。
SQLServer2005混合模式登录配置(用户登录错误18452,233,4064)
一、错误提示:用户登录失败,该用户与可信SQL Server连接无关联 错误18452 原因是远程登录没配置好,配置方法如下: 1:开启SQL2005远程连接功能 配置工具->SQLServer外围应用配置器->服务和连接的外围应用配置器-...
zigbee-cluster-library-specification
最新的zigbee-cluster-library-specification说明文档。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL数据库性能提升秘籍:揭秘性能下降幕后真凶及解决策略
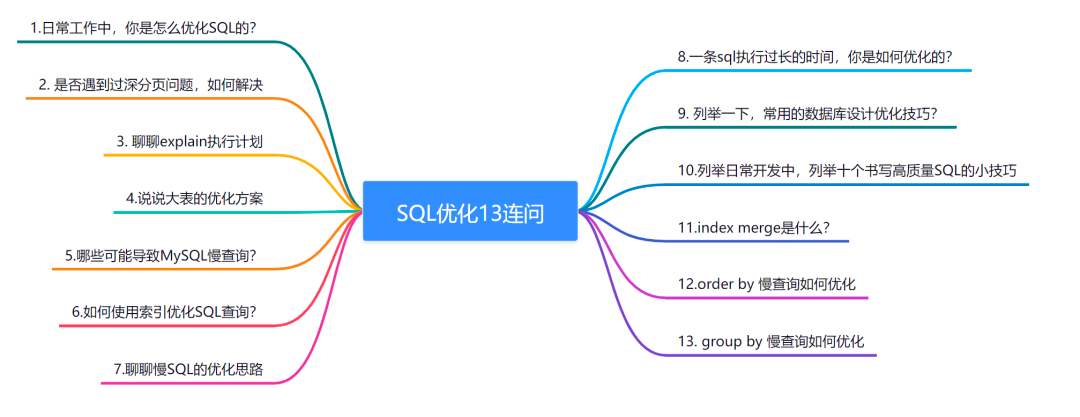
# 1. MySQL数据库性能优化概述**
MySQL数据库性能优化是一项至关重要的任务,可以显著提高应用程序的响应时间和整体用户体验。优化涉及识别和解决影响数据库性能的因素,包括硬件资源瓶颈、软件配置不当和数据库设计缺陷。通过采取适当的优化策略,可以显著提升数据库性能,满足业务需求并提高用户满意度。
# 2. MySQL数据库性能下降的幕后真凶
### 2.1 硬件资源瓶颈
#### 2.1.1 CPU利用率过高
**症状:
如何在unity创建按钮
在 Unity 中创建按钮的步骤如下:
1. 在 Unity 中创建一个 UI Canvas,选择 GameObject -> UI -> Canvas。
2. 在 Canvas 中创建一个按钮,选择 GameObject -> UI -> Button。
3. 在场景视图中调整按钮的位置和大小。
4. 在 Inspector 中设置按钮的文本、颜色、字体等属性。
5. 添加按钮的响应事件,选择按钮,在 Inspector 的 On Click () 中添加相应的方法。
这样就可以创建一个按钮了,你可以在游戏中使用它来触发相应的操作。
JSBSim Reference Manual
JSBSim参考手册,其中包含JSBSim简介,JSBSim配置文件xml的编写语法,编程手册以及一些应用实例等。其中有部分内容还没有写完,估计有生之年很难看到完整版了,但是内容还是很有参考价值的。