使用python完成以下步骤:1,使用cv2库读取四张图片并存储它们的曝光时间在一个数组内;2,随机从中选取100个点;3,生成一个A*x=B形式的线性方程组,并使用SVD解法解出来它;4,返回crf
时间: 2024-05-01 18:16:26 浏览: 98
函数,该函数输入一张图片和线性方程组的解,输出对应的crf函数。
以下是代码实现:
import cv2
import numpy as np
# 读取四张图片并存储曝光时间
img1 = cv2.imread('img1.jpg', cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread('img2.jpg', cv2.IMREAD_GRAYSCALE)
img3 = cv2.imread('img3.jpg', cv2.IMREAD_GRAYSCALE)
img4 = cv2.imread('img4.jpg', cv2.IMREAD_GRAYSCALE)
exposure_times = np.array([0.033, 0.25, 2.5, 15.0])
# 随机选取100个点
h, w = img1.shape
indices = np.random.randint(0, h*w, size=100)
row_indices = indices // w
col_indices = indices % w
# 构造A矩阵和B向量
A = np.zeros((100*4 + 255, 256 + 100))
B = np.zeros((100*4 + 255, 1))
k = 0
for i in range(100):
row, col = row_indices[i], col_indices[i]
for j in range(4):
A[k, img1[row, col]] = exposure_times[j]
A[k+1, img2[row, col]] = exposure_times[j]
A[k+2, img3[row, col]] = exposure_times[j]
A[k+3, img4[row, col]] = exposure_times[j]
B[k, 0] = exposure_times[j] * np.log(img1[row, col] + 1)
B[k+1, 0] = exposure_times[j] * np.log(img2[row, col] + 1)
B[k+2, 0] = exposure_times[j] * np.log(img3[row, col] + 1)
B[k+3, 0] = exposure_times[j] * np.log(img4[row, col] + 1)
for j in range(256):
A[k+4+j, j] = 1
A[k+4+j, 256+i] = -1
B[k+4+j, 0] = 0
k += 4
# 使用SVD求解线性方程组
U, S, V = np.linalg.svd(A, full_matrices=False)
x = np.dot(V.T, np.dot(np.diag(1/S), np.dot(U.T, B)))
# 返回crf函数
def crf(img, x):
h, w = img.shape
result = np.zeros((h, w))
for i in range(h):
for j in range(w):
result[i, j] = np.exp(x[img[i, j]] / exposure_times).sum() / 255
return result
# 测试crf函数
crf_img1 = crf(img1, x)
cv2.imshow('img1', img1)
cv2.imshow('crf_img1', crf_img1)
cv2.waitKey(0)
cv2.destroyAllWindows()
说明:
- 首先读取四张图片并存储曝光时间;
- 随机选取100个点,构造A矩阵和B向量;
- 使用SVD方法求解线性方程组;
- 定义crf函数,输入一张图片和线性方程组的解,输出对应的crf函数;
- 测试crf函数,显示原图和crf处理后的图像。
注意事项:
- 这里的曝光时间是自己设定的,实际应用中需要根据摄像机的参数来确定;
- 随机选取的100个点可能会出现选到同一个点的情况,可以通过np.random.choice函数避免;
- 构造A矩阵和B向量的过程要小心细节,如向量的维度、指数和对数的关系等;
- SVD方法可能会出现奇异矩阵的情况,可以通过加入正则化项或使用其他方法来避免;
- crf函数的计算过程可能会比较慢,可以考虑使用并行计算或其他加速方法。
阅读全文
大家在看
基于Python深度学习的目标跟踪系统的设计与实现+全部资料齐全+部署文档.zip
【资源说明】
基于Python深度学习的目标跟踪系统的设计与实现+全部资料齐全+部署文档.zip基于Python深度学习的目标跟踪系统的设计与实现+全部资料齐全+部署文档.zip
【备注】
1、该项目是个人高分项目源码,已获导师指导认可通过,答辩评审分达到95分
2、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,请放心下载使用!
3、本项目适合计算机相关专业(人工智能、通信工程、自动化、电子信息、物联网等)的在校学生、老师或者企业员工下载使用,也可作为毕业设计、课程设计、作业、项目初期立项演示等,当然也适合小白学习进阶。
4、如果基础还行,可以在此代码基础上进行修改,以实现其他功能,也可直接用于毕设、课设、作业等。
欢迎下载,沟通交流,互相学习,共同进步!
python版-百家号-seleiunm-全自动发布文案-可多账号-多文案-解放双手 -附带seleiunm源码-二次开发可用
python版_百家号_seleiunm_全自动发布文案_可多账号_多文案_解放双手 _附带seleiunm源码_二次开发可用
NEW.rar_fatherxbi_fpga_verilog 大作业_verilog大作业_投币式手机充电仪
Verilog投币式手机充电仪
清华大学数字电子技术基础课程EDA大作业。刚上电数码管全灭,按开始键后,数码管显示全为0。输入一定数额,数码管显示该数额的两倍对应的时间,按确认后开始倒计时。输入数额最多为20。若10秒没有按键,数码管全灭。
IEC 62133-2-2021最新中文版.rar
IEC 62133-2-2021最新中文版.rar
基于springboot的毕设-疫情网课管理系统(源码+配置说明).zip
基于springboot的毕设-疫情网课管理系统(源码+配置说明).zip
【项目技术】
开发语言:Java
框架:springboot
架构:B/S
数据库:mysql
【实现功能】
网课管理系统分为管理员和学生、教师三个角色的权限子模块。
管理员所能使用的功能主要有:首页、个人中心、学生管理、教师管理、班级管理、课程分类管理、课程表管理、课程信息管理、作业信息管理、请假信息管理、上课签到管理、论坛交流、系统管理等。
学生可以实现首页、个人中心、课程表管理、课程信息管理、作业信息管理、请假信息管理、上课签到管理等。
教师可以实现首页、个人中心、学生管理、班级管理、课程分类管理、课程表管理、课程信息管理、作业信息管理、请假信息管理、上课签到管理、系统管理等。
最新推荐
STM32F103C8T6(C6T6)遥控小车发射接收模块 遥控发射端采用的芯片是c6t6,通过摇杆搭配NRF24L01向接收端发送数据,总共有8个数据通道,这里只用了左摇杆控制前后运动,右摇杆控制舵
STM32F103C8T6(C6T6)遥控小车发射接收模块
遥控发射端采用的芯片是c6t6,通过摇杆搭配NRF24L01向接收端发送数据,总共有8个数据通道,这里只用了左摇杆控制前后运动,右摇杆控制舵机左右转向,如需要其他通道可在源码里增加。
发射端采用的c6t6最小系统板搭配NRF24L01和L298N驱动器(驱动器可根据电机参数选择搭配)。
的是:
发射端原理图、PCB、源码。
接收端接线图,源码。
使用说明。
3G SDI 视频矩阵 4x4 1080P ?方案资料 TI 数字交叉开关芯片方案 方案资料含有源码(I2C控制数字交叉开关)、PCB图 通过发送串口指令控制矩阵板(提供简易版测试控制软件)
3G SDI 视频矩阵 4x4 1080P ?方案资料。
TI 数字交叉开关芯片方案。
方案资料含有源码(I2C控制数字交叉开关)、PCB图。
通过发送串口指令控制矩阵板(提供简易版测试控制软件)。
矩阵板供电 DC 12V 供电。
该资料没有原理图
注意该资料没有原理图,只有PCB图。
代码环境编译KEIL3。
画图软件Protel99。
双,多隐含层BP神经网络预测代码,多数入单输出,MATLAB程序 修改好的程序,注释清楚,EXCEL数据,可直接数据,直接运行即可 代码实现训练与测试精度分析
双,多隐含层BP神经网络预测代码,多数入单输出,MATLAB程序。
修改好的程序,注释清楚,EXCEL数据,可直接数据,直接运行即可。
代码实现训练与测试精度分析。
储能优化配置,考虑不平衡配电网,使用matlab实现,自己编的程序 灵敏度分析选址,以年均运维成本最低为目标优化接入容量以及储能出力,使用改进灰狼优化算法求解 附简单说明文档,适合初学者学习使用
储能优化配置,考虑不平衡配电网,使用matlab实现,自己编的程序。
灵敏度分析选址,以年均运维成本最低为目标优化接入容量以及储能出力,使用改进灰狼优化算法求解。
附简单说明文档,适合初学者学习使用。
交通牌识别 matlab bp神经网络 模版匹配 我自己做的 可以改数据 静态静态动态不用matlab
交通牌识别 matlab
bp神经网络 模版匹配
我自己做的
可以改数据
静态静态动态不用matlab
Pokedex: 探索JS开发的口袋妖怪应用程序
资源摘要信息:"Pokedex是一个基于JavaScript的应用程序,主要功能是收集和展示口袋妖怪的相关信息。该应用程序是用JavaScript语言开发的,是一种运行在浏览器端的动态网页应用程序,可以向用户提供口袋妖怪的各种数据,例如名称、分类、属性等。"
首先,我们需要明确JavaScript的作用。JavaScript是一种高级编程语言,是网页交互的核心,它可以在用户的浏览器中运行,实现各种动态效果。JavaScript的应用非常广泛,包括网页设计、游戏开发、移动应用开发等,它能够处理用户输入,更新网页内容,控制多媒体,动画以及各种数据的交互。
在这个Pokedex的应用中,JavaScript被用来构建一个口袋妖怪信息的数据库和前端界面。这涉及到前端开发的多个方面,包括但不限于:
1. DOM操作:JavaScript可以用来操控文档对象模型(DOM),通过DOM,JavaScript可以读取和修改网页内容。在Pokedex应用中,当用户点击一个口袋妖怪,JavaScript将利用DOM来更新页面,展示该口袋妖怪的详细信息。
2. 事件处理:应用程序需要响应用户的交互,比如点击按钮或链接。JavaScript可以绑定事件处理器来响应这些动作,从而实现更丰富的用户体验。
3. AJAX交互:Pokedex应用程序可能需要与服务器进行异步数据交换,而不重新加载页面。AJAX(Asynchronous JavaScript and XML)是一种在不刷新整个页面的情况下,进行数据交换的技术。JavaScript在这里扮演了发送请求、处理响应以及更新页面内容的角色。
4. JSON数据格式:由于JavaScript有内置的JSON对象,它可以非常方便地处理JSON数据格式。在Pokedex应用中,从服务器获取的数据很可能是JSON格式的口袋妖怪信息,JavaScript可以将其解析为JavaScript对象,并在应用中使用。
5. 动态用户界面:JavaScript可以用来创建动态用户界面,如弹出窗口、下拉菜单、滑动效果等,为用户提供更加丰富的交互体验。
6. 数据存储:JavaScript可以使用Web Storage API(包括localStorage和sessionStorage)在用户的浏览器上存储数据。这样,即使用户关闭浏览器或页面,数据也可以被保留,这对于用户体验来说是非常重要的,尤其是对于一个像Pokedex这样的应用程序,用户可能希望保存他们查询过的口袋妖怪信息。
此外,该应用程序被标记为“JavaScript”,这意味着它可能使用了JavaScript的最新特性或者流行的库和框架,例如React、Vue或Angular。这些现代的JavaScript框架能够使前端开发更加高效、模块化和易于维护。例如,React允许开发者构建可复用的UI组件,Vue则提供了数据驱动和组件化的编程方式,而Angular则是一个全面的前端框架,提供了模板、依赖注入、客户端路由等功能。
在文件名称列表中提到了"Pokedex-main",这很可能是应用程序的主文件或者项目的根目录名称。在这种情况下,主文件可能包含程序的入口点,即整个JavaScript应用程序开始执行的地方,它通常会包含对其他JavaScript文件的引用,以及初始化应用程序的代码。
综上所述,Pokedex作为一个JavaScript应用程序,涉及了前端开发的多个关键技术和概念。通过JavaScript,开发者能够实现一个功能丰富、响应用户交互、动态更新内容的应用程序,为用户提供口袋妖怪的详细信息和互动体验。
【提升R-Studio恢复效率】:RAID 5数据恢复的高级技巧与成功率
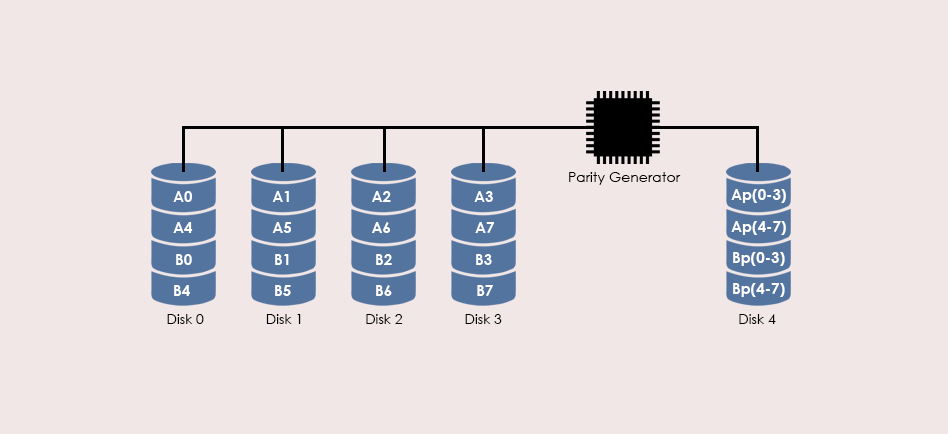
# 摘要
RAID 5作为一种广泛应用于数据存储的冗余阵列技术,能够提供较好的数据保护和性能平衡。本文首先概述了RAID 5数据恢复的重要性,随后介绍了RAID 5的基础理论,包括其工作原理、故障类型及数据恢复前的准备工作。接着,文章深入探讨了提升RAID 5数据恢复成功率的高级技巧,涵盖了硬件级别和软件工具的应用,以及文件系统结构和数据一致性检查。通过实际案例分析,
帮我写一段Python代码:sin波生成,设定rate,fin,size,幅值
当然可以。在Python中,我们可以使用`numpy`库来创建正弦波,并通过`tqdm`库添加进度条。下面是一个简单的示例代码,它会生成指定频率(rate)、持续时间(fin),以及样本大小(size)的正弦波,幅度可以自定义:
```python
import numpy as np
from tqdm import trange
# 定义函数生成sin波
def generate_sine_wave(rate=44100, fin=5, size=None, amplitude=1):
# 检查参数是否合理
if size is None:
size =
Laravel实用工具包:laravel-helpers概述
资源摘要信息:"Laravel开发-laravel-helpers 是一个针对Laravel框架开发者的实用程序包,它提供了许多核心功能的便捷访问器(getters)和修改器(setters)。这个包的设计初衷是为了提高开发效率,使得开发者能够快速地使用Laravel框架中常见的一些操作,而无需重复编写相同的代码。使用此包可以简化代码量,减少出错的几率,并且当开发者没有提供自定义实例时,它将自动回退到Laravel的原生外观,确保了功能的稳定性和可用性。"
知识点:
1. Laravel框架概述:
Laravel是一个基于PHP的开源Web应用框架,遵循MVC(Model-View-Controller)架构模式。它旨在通过提供一套丰富的工具来快速开发Web应用程序,同时保持代码的简洁和优雅。Laravel的特性包括路由、会话管理、缓存、模板引擎、数据库迁移等。
2. Laravel核心包:
Laravel的核心包是指那些构成框架基础的库和组件。它们包括但不限于路由(Routing)、请求(Request)、响应(Response)、视图(View)、数据库(Database)、验证(Validation)等。这些核心包提供了基础功能,并且可以被开发者在项目中广泛地使用。
3. Laravel的getters和setters:
在面向对象编程(OOP)中,getters和setters是指用来获取和设置对象属性值的方法。在Laravel中,这些通常指的是辅助函数或者服务容器中注册的方法,用于获取或设置框架内部的一些配置信息和对象实例。
4. Laravel外观模式:
外观(Facade)模式是软件工程中常用的封装技术,它为复杂的子系统提供一个简化的接口。在Laravel框架中,外观模式广泛应用于其核心类库,使得开发者可以通过简洁的类方法调用来执行复杂的操作。
5. 使用laravel-helpers的优势:
laravel-helpers包作为一个辅助工具包,它将常见的操作封装成易于使用的函数,使开发者在编写Laravel应用时更加便捷。它省去了编写重复代码的麻烦,降低了项目的复杂度,从而加快了开发进程。
6. 自定义实例和回退机制:
在laravel-helpers包中,如果开发者没有提供特定的自定义实例,该包能够自动回退到使用Laravel的原生外观。这种设计使得开发者在不牺牲框架本有功能的前提下,能够享受到额外的便利性。
7. Laravel开发实践:
在实际的开发过程中,开发者可以通过引入laravel-helpers包来简化代码的编写。例如,该包可能提供了一系列用于验证输入数据的快速方法,或者是一些处理常见任务的辅助函数,如快速生成响应、执行数据库查询、发送邮件等。
8. 开源贡献和社区支持:
laravel-helpers作为一个开源包,它的维护和更新依赖于社区的贡献。开发者在使用过程中也可以参与到包的开发与改进中,为Laravel社区做出贡献,并从社区中获取帮助和反馈。
总结而言,laravel-helpers包通过提供一系列的getters和setters工具函数,极大地提升了Laravel开发的效率与便利性。它不仅遵循了Laravel的核心设计理念,还通过回退机制保证了与框架原生功能的兼容性。对于希望优化其开发流程的Laravel开发者来说,这无疑是一个宝贵的资源。
【R-Studio技术路径】:从RAID 5数据恢复基础到高级操作

# 摘要
随着信息技术的发展,数据丢失问题日益突出,RAID 5作为常见的数据存储解决方案,其数据恢复技术显得尤为重要。本文首先介绍了RAID 5数据恢复的基础知识,然后详细解析了R-Studio软件的界面和核心功能,重点探讨了其在RAID 5数据恢复中的应用实践,包括磁盘镜像创建、数据提取、数据重组策略及一致性验证。进一步,本文还涉及了R-Studio的进阶技术,如脚本编