c语言里面的记事本乱码
时间: 2023-10-29 12:40:28 浏览: 49
记事本中出现乱码可能有多种原因,以下是一些常见的原因和解决方法:
1. 编码不一致:记事本默认使用 ANSI 编码,而有些程序使用的是 UTF-8、Unicode 等编码格式,导致打开时出现乱码。解决方法:在记事本中选择“另存为”,选择编码为 UTF-8 或 Unicode。
2. 字体不一致:有些字体可能不支持某些字符,导致打开时出现乱码。解决方法:在记事本中选择“格式”->“字体”,选择一个支持所需字符的字体。
3. 文件损坏:文件损坏也可能导致打开时出现乱码。解决方法:尝试从备份或其他来源获取文件。
4. 语言环境不一致:有时候在不同的语言环境中打开文件会导致乱码。解决方法:在记事本中选择“文件”->“打开”,在“编码”下拉菜单中选择正确的语言环境。
希望这些解决方法能帮到你!
相关问题
c语言printf中文乱码
在C语言中,如果使用printf函数输出中文字符时出现乱码,通常是由于编码方式不匹配导致的。C语言默认使用ASCII编码,而中文字符通常使用的是UTF-8编码。
要解决printf中文乱码问题,可以采取以下几种方法:
1. 使用宽字符函数:C语言提供了宽字符函数来处理多字节字符,例如wprintf和fwprintf。这些函数可以正确地输出中文字符。需要注意的是,使用宽字符函数时,字符串常量需要在前面加上L前缀,表示宽字符。
2. 修改编码方式:可以将C语言的编码方式修改为UTF-8,以匹配中文字符的编码方式。可以在源代码文件的开头添加如下注释,指定文件的编码方式为UTF-8:
```c
// - coding: utf-8 -*-
```
3. 使用转义序列:可以使用转义序列来输出中文字符。例如,使用\u编码来表示Unicode字符,如\u4F60表示中文字符"你"。需要注意的是,转义序列只适用于Unicode字符集。
4. 使用第三方库:如果以上方法无法解决问题,可以考虑使用第三方库来处理中文字符的输出。例如,可以使用iconv库进行字符编码转换。
c语言txt文件乱码
C语言读取txt文件时出现乱码的原因可能有很多,以下是几种可能的原因和解决方法:
1.文件编码方式不同:如果文件的编码方式与程序读取文件时的编码方式不同,就会出现乱码。可以通过修改文件编码方式或者在程序中指定编码方式来解决。
2.文件中包含特殊字符:如果文件中包含一些特殊字符,例如非ASCII字符,也可能会导致乱码。可以通过在程序中使用宽字符类型(wchar_t)来解决。
3.文件读取方式不正确:如果文件读取方式不正确,例如读取的字节数不正确或者读取的方式不正确,也可能会导致乱码。可以通过检查读取方式和读取字节数来解决。
以下是一个示例程序,演示了如何读取一个UTF-8编码的txt文件并正确输出其中的内容:
```c
#include <stdio.h>
#include <locale.h>
#include <wchar.h>
int main()
{
setlocale(LC_ALL, ""); // 设置本地化环境
FILE* fp = fopen("test.txt", "r, ccs=UTF-8"); // 打开UTF-8编码的文件
if (fp == NULL) {
printf("open file error!\n");
return -1;
}
wchar_t buf[1024];
while (fgetws(buf, 1024, fp) != NULL) { // 逐行读取文件内容
wprintf(L"%ls", buf); // 输出读取的内容
}
fclose(fp);
return 0;
}
```
相关推荐
最新推荐
小学生测验C语言课程设计报告
1.通过本课程设计,培养上机动手能力,使学生巩固《C语言程序设计》课程学习的内容,掌握工程软件设计的基本方法,强化上机动手能力,闯过编程关; 2.为后续各门计算机课程的学习打下坚实基础; 3.理解程序设计的思路...
C语言实现小型电子词典
主要为大家详细介绍了C语言实现小型电子词典,用户可以进行英译汉、汉译英等功能,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
计算机考研复试C语言简答题资料
适用于考研党C语言线上复试问答~
C语言基础(全).pdf
包含的内容都是博客的,这里只是整理成了PDF方便查看,下载前请先浏览博客查看是否需要。(后续有时间的话会优化内容)
c语言float类型小数点后位数
在本篇文章里小编给大家整理了关于c语言float类型小数点后面有几位的相关知识点,需要的朋友们可以学习下。
zigbee-cluster-library-specification
最新的zigbee-cluster-library-specification说明文档。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL数据库性能提升秘籍:揭秘性能下降幕后真凶及解决策略
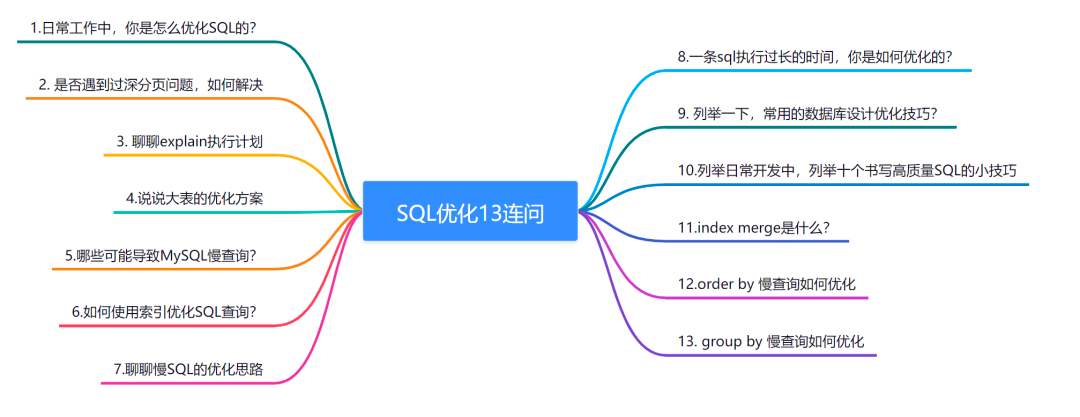
# 1. MySQL数据库性能优化概述**
MySQL数据库性能优化是一项至关重要的任务,可以显著提高应用程序的响应时间和整体用户体验。优化涉及识别和解决影响数据库性能的因素,包括硬件资源瓶颈、软件配置不当和数据库设计缺陷。通过采取适当的优化策略,可以显著提升数据库性能,满足业务需求并提高用户满意度。
# 2. MySQL数据库性能下降的幕后真凶
### 2.1 硬件资源瓶颈
#### 2.1.1 CPU利用率过高
**症状:
如何在unity创建按钮
在 Unity 中创建按钮的步骤如下:
1. 在 Unity 中创建一个 UI Canvas,选择 GameObject -> UI -> Canvas。
2. 在 Canvas 中创建一个按钮,选择 GameObject -> UI -> Button。
3. 在场景视图中调整按钮的位置和大小。
4. 在 Inspector 中设置按钮的文本、颜色、字体等属性。
5. 添加按钮的响应事件,选择按钮,在 Inspector 的 On Click () 中添加相应的方法。
这样就可以创建一个按钮了,你可以在游戏中使用它来触发相应的操作。
JSBSim Reference Manual
JSBSim参考手册,其中包含JSBSim简介,JSBSim配置文件xml的编写语法,编程手册以及一些应用实例等。其中有部分内容还没有写完,估计有生之年很难看到完整版了,但是内容还是很有参考价值的。