【数据探索与可视化】:简化流程,使用Anaconda模板进行数据探索与可视化
发布时间: 2024-12-09 16:38:19 阅读量: 4 订阅数: 17 

玉米病叶识别数据集,可识别褐斑,玉米锈病,玉米黑粉病,霜霉病,灰叶斑点,叶枯病等,使用voc对4924张照片进行标注
# 1. 数据探索与可视化的基础概念
## 数据探索与可视化的意义
在数据科学领域,数据探索与可视化是理解数据内在结构、模式和关联的关键环节。它涉及到数据分析的初级阶段,即通过视觉工具和统计技术来发现数据集中的有趣特征、异常和趋势。数据探索有助于我们提出假设,为后续的分析和建模工作奠定基础。
## 数据探索与可视化的步骤
进行数据探索通常包括几个关键步骤:
1. **数据收集**:获取所需分析的数据。
2. **数据清洗**:处理缺失值、异常值和格式不统一等问题。
3. **数据转换**:将数据转换成适合进行分析的格式,包括归一化、标准化等。
4. **数据可视化**:利用图表和图形将分析结果展示出来。
## 数据探索与可视化的工具
在数据分析中,有许多工具可以用于数据探索和可视化,其中一些常用的包括:
- **Python**:使用Pandas进行数据处理,Matplotlib和Seaborn进行数据可视化。
- **R语言**:利用ggplot2等包进行图形化探索。
- **Tableau** 和 **Power BI**:这些工具提供了强大的数据可视化能力,适用于商业智能分析。
数据探索和可视化作为分析流程的起始点,不仅有助于快速洞察数据特点,而且可以指导后续更复杂的数据挖掘与机器学习过程。接下来,我们将深入探讨如何搭建Anaconda环境,进一步深化我们的数据探索与可视化技能。
# 2. Anaconda环境的搭建与配置
Anaconda是一个流行的开源Python发行版,适用于大规模数据处理、预测分析和科学计算。它为数据分析提供了一个集成的环境,预装了大量数据科学相关的包,极大地简化了数据分析与可视化的准备工作。
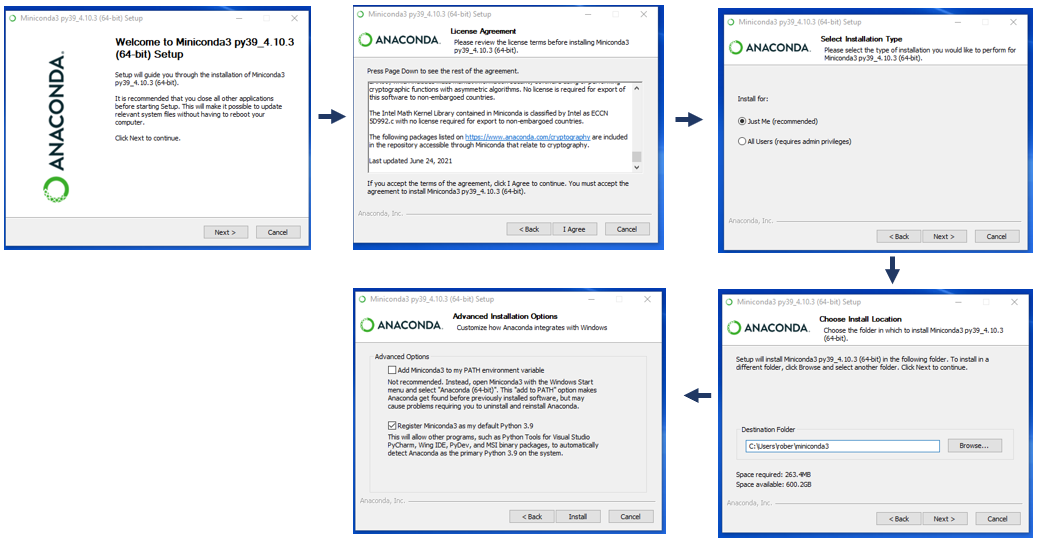
### 2.1 Anaconda的下载和安装
Anaconda可以在其官方网站下载适合不同操作系统的安装包。以下是下载和安装Anaconda的步骤:
#### 2.1.1 下载Anaconda安装包
1. 访问Anaconda官方网站。
2. 选择适合您操作系统的Python版本。目前,Anaconda支持Windows, macOS, Linux等系统。
3. 下载安装包。
#### 2.1.2 安装Anaconda
1. 双击下载的安装包。
2. 按照安装向导提示完成安装,推荐接受所有默认选项。
安装完成后,可以在系统中打开Anaconda Navigator。这是一个图形用户界面,可以帮助我们安装和管理包,以及启动Jupyter Notebook和Spyder等IDE。
### 2.2 Anaconda环境管理
在使用Anaconda时,我们通常会创建多个虚拟环境,以隔离不同项目之间的依赖关系。
#### 2.2.1 创建新的环境
可以使用conda命令行工具来创建新的环境,例如创建一个名为`py38`的新环境,指定Python版本为3.8:
```bash
conda create -n py38 python=3.8
```
#### 2.2.2 激活环境
在命令行中输入以下命令来激活之前创建的环境:
```bash
conda activate py38
```
一旦激活,我们可以开始安装需要的包:
```bash
conda install numpy pandas matplotlib
```
#### 2.2.3 环境导出和导入
如果需要与其他用户共享环境,可以导出当前环境的配置文件:
```bash
conda env export > environment.yml
```
其他用户可以通过以下命令导入环境:
```bash
conda env create -f environment.yml
```
### 2.3 Anaconda包的管理
在数据分析项目中,可能会需要安装很多特定版本的包。Anaconda提供了非常便捷的方式来管理这些包。
#### 2.3.1 包的安装
使用conda安装包非常简单:
```bash
conda install <package_name>
```
如果conda找不到想要的包,还可以使用pip进行安装:
```bash
pip install <package_name>
```
#### 2.3.2 包的更新和卸载
更新一个包到最新版本:
```bash
conda update <package_name>
```
卸载不需要的包:
```bash
conda remove <package_name>
```
### 2.4 深入理解Conda的YAML文件
Anaconda环境的配置信息可以被保存在YAML文件中,这使得环境配置变得可复现和可共享。
#### 2.4.1 YAML文件结构
YAML文件包含了环境名称、包列表以及包的版本信息。以下是一个简单的示例:
```yaml
name: py38
channels:
- conda-forge
- defaults
dependencies:
- python=3.8
- pandas=1.1.3
- matplotlib=3.3.1
```
#### 2.4.2 管理多个环境
我们可以为不同的项目维护多个YAML文件,通过`conda env create -f environment1.yml`来创建环境,或者通过`conda env update -f environment2.yml --prune`来更新现有环境。
### 小结
通过上述步骤,我们可以快速搭建和配置Anaconda环境,进行高效的数据探索与可视化。随着您对Anaconda环境的熟悉程度加深,将会更加体会到它在数据科学工作流程中的便利和强大功能。
# 3. 使用Anaconda进行数据探索
## 3.1 数据预处理技术
### 3.1.1 数据清洗和预处理
数据清洗是数据预处理的首个步骤,目的是确保数据的质量和可用性。数据预处理通常包括处理缺失值、异常值、重复数据、数据类型转换、数据归一化等任务。
#### 处理缺失值
缺失值可以使用均值、中位数、众数或者根据业务逻辑填充特定值。
```python
import pandas as pd
# 示例数据
data = {'A': [1, 2, 3, None, 5], 'B': [6, None, 8, 9, 10]}
df = pd.DataFrame(data)
# 使用均值填充缺失值
df_filled_mean = df.fillna(df.mean())
# 使用众数填充缺失值
df_filled_mode = df.fillna(df.mode().iloc[0])
```
以上代码块展示了如何使用均值和众数填充缺失值的方法。在使用`fillna`函数时,可以指定不同的填充方法。
#### 处理异常值
异常值可以通过定义的阈值范围来识别和处理。
```python
# 假设我们定义的阈值为小于30或大于70为异常
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQ
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Anaconda项目模板专栏是一份全面的指南,涵盖了使用Anaconda进行项目管理和开发的各个方面。它提供了从创建项目模板到使用Git进行版本控制的逐步指导。专栏还介绍了Anaconda环境管理的最佳实践,以及优化开发和部署流程的技巧。此外,它还探讨了Anaconda模板在大数据项目中的应用,以及提高性能的内存管理和加速技术。通过本专栏,读者可以掌握Anaconda的强大功能,从而简化项目管理、提高开发效率并优化机器学习项目框架。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
网络硬件的秘密武器:QSGMII规格全剖析

参考资源链接:[QSGMII接口规范:连接PHY与MAC的高速解决方案](https://wenku.csdn.net/doc/82hgqw0h96?spm=1055.2635.3001.10343)
# 1. QSGMII概述与起源
## 1.1 QSGMII的定义与概念
QSGMII(Quadruple Small Form-factor Pluggable Gigabit Med
【JVPX连接器完全指南】:精通选型、电气特性、机械设计及故障处理

参考资源链接:[航天JVPX加固混装连接器技术规格与优势解析](https://wenku.csdn.net/doc/6459ba7afcc5391368237d7a?spm=1055.2635.3001.10343)
# 1. JVPX连接器概述
## JVPX连接器的起源与发展
JVPX连接器是高性能连接解决方案中的佼佼者,它起源于军事和航空航天领域,因应对极端环境的苛刻
电子工程师必读:LVTTL和LVCMOS定义、应用及解决方案
参考资源链接:[LVTTL LVCMOS电平标准](https://wenku.csdn.net/doc/6412b6a2be7fbd1778d476ba?spm=1055.2635.3001.10343)
# 1. LVTTL与LVCMOS的定义与基本特性
## 1.1 LVTTL与LVCMOS简介
在数字电路设计中,LVTTL(Low Voltage Transistor-Transistor Logic)和LVCMOS(Low Voltage Complementary Metal-Oxide-Semiconductor)是两种常见的电压标准。它们用于确保不同集成电路(IC)之间的兼容
【NRF52810开发环境全攻略】:一步到位配置软件工具与固件

参考资源链接:[nRF52810低功耗蓝牙芯片技术规格详解](https://wenku.csdn.net/doc/645c391cfcc53913682c0f4c?spm=1055.2635.3001.10343)
# 1. NRF52810开发概述
精通数字电路设计:第五章关键概念全解析
参考资源链接:[数字集成电路设计 第五章答案 chapter5_ex_sol.pdf](https://wenku.csdn.net/doc/64a21b7d7ad1c22e798be8ea?spm=1055.2635.3001.10343)
# 1. 数字电路设计的原理与基础
数字电路设计是构建现代电子系统不可或缺的环节,它涉及到从
【编程新手教程】:正点原子ATK-1218-BD北斗GPS模块基础与实践

参考资源链接:[正点原子ATK-1218-BD GPS北斗模块用户手册:接口与协议详解](https://wenku.csdn.net/doc/5o9cagtmgh?spm=1055.2635.3001.10343)
# 1. ATK-1
存储器技术变革:JEP122H标准的深远影响分析

参考资源链接:[【最新版可复制文字】 JEDEC JEP122H 2016.pdf](https://wenku.csdn.net/doc/hk9wuz001r?spm=1055.2635.3001.10343)
# 1. 存储器技术的演进与JEP122H标准概览
存储器技术是计算机系统中不可或缺的组成部分,它的发展速度直接关系到整个信息处理系统的性能。JEP122H标准是继以
多目标优化新境界:SQP算法的应用与技巧

参考资源链接:[SQP算法详解:成功解决非线性约束优化的关键方法](https://wenku.csdn.net/doc/1bivue5eeo?spm=1055.2635.3001.10343)
# 1. SQP算法概述与理论基础
在数学优化领域中,序列二次规划(Sequential Quadratic Progr
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )