【专家揭秘】搭建MySQL与Apache集群:扩展性与高可用性配置秘籍
发布时间: 2024-12-07 09:24:27 阅读量: 6 订阅数: 17 

MySQL集群与LVS实现apache负载均衡.pdf
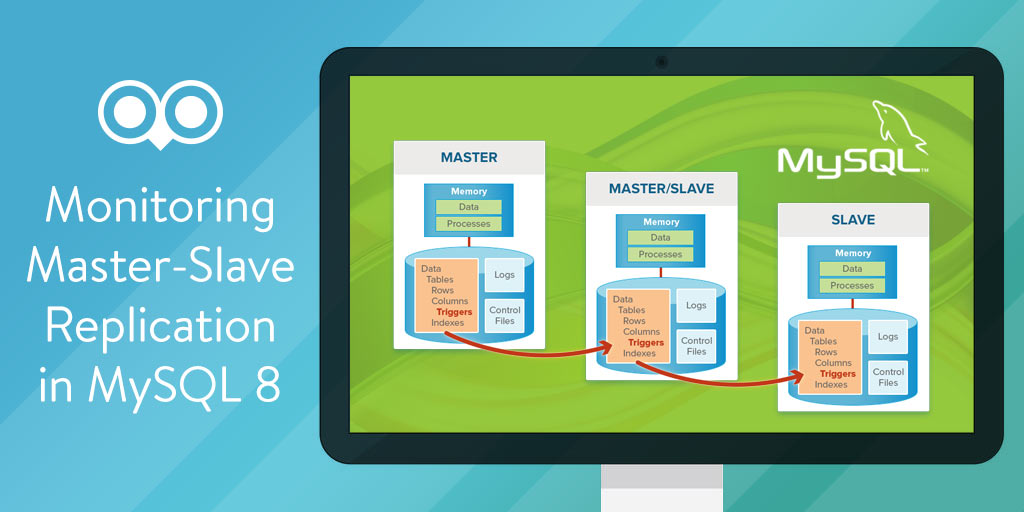
# 1. MySQL与Apache集群概述
## 集群技术的重要性与应用场景
在当今数字化时代,数据的高速处理与存储是企业IT基础设施的核心要求。集群技术应运而生,为的是通过多个计算节点的协同工作,提供比单个系统更高的性能、更强的稳定性和更好的可扩展性。它在大数据处理、云计算平台、在线服务、以及需要高并发访问的应用场景中扮演着至关重要的角色。集群通过分散负载和数据冗余,确保了服务的连续性和数据的安全性,是企业应对业务需求波动和峰值冲击的有效手段。
## MySQL与Apache集群的基本概念
MySQL集群是指多个MySQL实例组成的一个系统,这些实例协同工作,共享数据,提供服务。它通过分布式的架构设计,实现了数据库的高性能、高可用性和易扩展性。同样,Apache集群则涉及到将多个Apache服务器实例联合在一起,以处理大量的HTTP请求。它通常通过负载均衡器来分配请求至各个服务器,并通过复制技术保障服务的连续性和数据的一致性。
## 扩展性与高可用性的基本原理
扩展性是集群技术的一个核心概念,它主要通过水平扩展(增加更多服务器)来提升系统处理能力。高可用性(High Availability, HA)则意味着系统即便在部分组件发生故障的情况下,仍能够继续提供服务。在MySQL集群中,这通常通过数据副本和故障转移机制来实现,确保数据的持续可用性;在Apache集群中,则是通过健康检查和流量分配策略来保证关键组件的不间断服务。通过这些机制,集群能够在面对硬件故障、网络问题甚至应用程序故障时,仍然保持运行,为用户提供不间断的服务。
# 2.1 MySQL集群架构解析
### 2.1.1 集群组件与工作原理
MySQL集群是由多种组件构成,每一个组件都拥有其独特的功能,它们协同工作,从而实现一个高效、高可用的数据库环境。MySQL集群核心组件包括数据节点(Data Nodes),管理节点(Mysqld Management Nodes),以及SQL节点(SQL Nodes)。
- 数据节点负责存储实际的数据,实现数据的冗余和高可用。
- 管理节点用于维护集群的状态信息,管理集群内部的通信,以及监控各个数据节点的状态,确保数据的一致性。
- SQL节点,又称应用节点,主要负责处理客户端的连接和查询请求。
集群工作原理基于NDB存储引擎,该存储引擎专为集群而设计,能够实现多数据节点之间的实时数据复制和同步。当客户端发起查询或更新请求时,请求首先被发送到SQL节点,然后通过内部路由机制转发到对应的数据节点。数据节点进行相应的数据操作,并将结果返回给SQL节点,最后由SQL节点返回给客户端。
### 2.1.2 数据复制与故障转移机制
数据复制是保证MySQL集群高可用的关键技术之一。MySQL集群采用异步复制机制,通过二进制日志(Binary Log)来实现数据节点之间的数据同步。
- 主节点对数据的修改(如INSERT、UPDATE、DELETE操作)会被记录到二进制日志中。
- 复制线程会定期从主节点获取二进制日志,并在从节点上重放,从而保持数据的一致性。
故障转移机制确保当集群中的一个或多个节点发生故障时,整个集群能够迅速恢复服务,最大限度地减少服务中断时间。该机制包括如下步骤:
1. 故障检测:管理节点定期检测数据节点和SQL节点的健康状态,如果检测到节点故障,会立即进行标记。
2. 故障通知:管理节点将故障信息通知给其他健康节点,并在集群中进行广播。
3. 自动恢复:根据配置,可能会触发自动故障转移过程,让其他节点接管故障节点的工作。
4. 故障节点替换:集群中可以设置热备节点,它们会在主节点发生故障时自动上线,继续提供服务。
## 2.2 MySQL集群安装与配置步骤
### 2.2.1 安装前的准备工作
在开始MySQL集群的安装前,需要进行以下准备工作:
- 确定集群的架构:根据应用需求选择合适的集群架构(例如,主从复制、双主复制、集群多主等)。
- 硬件资源规划:评估所需服务器的硬件资源,包括CPU、内存、存储空间等。
- 网络环境准备:确保所有参与集群的服务器之间网络互通,并有适当的防火墙策略。
### 2.2.2 配置实例与节点管理
配置MySQL集群涉及多个步骤,具体如下:
- 初始化数据节点:创建目录并初始化数据节点,包括分配端口、设置节点ID等。
- 配置管理节点:编辑管理节点配置文件,指定管理节点ID和集群管理的端口。
- 配置SQL节点:在每个SQL节点的配置文件中指定集群参数,并确保SQL节点能够找到数据节点。
节点管理是指如何操作集群中的各个节点,包括启动、停止、监控节点状态等。通过管理节点提供的命令行工具或者MySQL集群的管理控制台,可以执行节点的管理操作。
## 2.3 MySQL集群性能优化
### 2.3.1 索引优化与查询调优
索引是优化数据库性能的关键,它可以显著提高查询效率。索引优化主要包括:
- 选择合适的索引类型:根据查询模式选择B-tree索引或哈希索引等。
- 索引列选择:基于查询条件和排序操作来确定哪些列需要建立索引。
- 索引维护:定期清理和重建索引,以确保索引的性能不会因数据变动而降低。
查询调优的核心是减少查询所涉及的数据量以及优化数据访问方式。可以通过以下步骤进行:
- 优化查询语句:使用EXPLAIN来分析查询计划,理解查询是如何执行的。
- 避免全表扫描:确保查询条件能够利用索引。
- 分批处理数据:当处理大量数据时,采用分批查询减少单次查询负载。
### 2.3.2 负载均衡与读写分离
负载均衡是指将进入集群的请求分散到多个服务器上,以提高整体吞吐量和减少单点故障的可能性。负载均衡可以通过以下方式实现:
- 使用硬件负载均衡器,如F5 BIG-IP。
- 利用软件负载均衡器,如Nginx或HAProxy。
读写分离是通过分离读和写操作到不同的服务器来优化性能的策略。在MySQL集群中,通常由SQL节点来实现读写分离:
- 写操作由主节点处理,然后通过数据复制机制同步到其他节点。
- 读操作可以分配给任意可用的节点,这样可以分担主节点的负载。
## 代码块
下面是为MySQL集群配置一个简单的负载均衡的例子,使用了HAProxy作为负载均衡器。
```haproxy
frontend http_front
bind *:80
stats uri /haproxy?stats
default_backend http_back
backend http_back
balance roundrobin
server node1 <node1_ip>:3306 check
server node2 <node2_ip>:3306 check
server node3 <node3_ip>:3306 check
```
逻辑分析:
- `frontend http_front` 定义了一个前端,监听所有IP地址的80端口。
- `balance roundrobin` 指定使用轮询算法进行负载均衡。
- `server` 指令定义了三个节点,`check` 参数确保HAProxy能够检查后端服务的健康状态。
参数说明:
- `<node1_ip>`, `<node2_ip>`, `<node3_ip>` 代表实际部署的MySQL集群中SQL节点的IP地址。
- HAProxy配置文件中的端口号需要和SQL节点上MySQL服务监听的端口一致。
## 表格
| 参数 | 描述 | 推荐值 |
|-------------------|------------------------------------------------------------|----------|
| balance | 设置负载均衡的算法。可选项有 roundrobin, leastconn 等。 | roundrobin |
| server | 后端服务器的定义,包括IP和端口。 | |
| check | 对后端服务器进行健康检查。 | |
| default_backend | 设置默认的后端服务器组。 | http_back |
| stats uri | HAProxy状态页面的URI地址。 | /haproxy?stats |
> 注:以上表格展示了在HAProxy配置文件中常用参数的描述和推荐值。
## 流程图
```mermaid
graph TD
A[客户端请求] -->|通过HTTP| B[HAProxy负载均衡器]
B -->|负载均衡算法| C[SQL节点1]
B -->|负载均衡算法| D[SQL节点2]
B -->|负载均衡算法| E[SQL节点3]
C -->|读操作| F[返回数据]
D -->|读操作| F
E -->|读操作| F
```
逻辑分析:
- 客户端发送请求到HAProxy负载均衡器。
- HAProxy根据负载均衡算法选择一个SQL节点,并将请求转发过去。
- 选中的SQL节点处理请求,执行读操作,并将数据返回给客户端。
该流程图展示了HAProxy如何将客户端的请求分发给MySQL集群中的SQL节点,实现了负载均衡。
## 2.3.2 负载均衡与读写分离
在数据库集群中,实现负载均衡和读写分离策略是优化性能的重要手段。以下是具体操作步骤:
1. 配置应用层访问策略,确保写请求(INSERT、UPDATE、DELETE)只发送给主节点,读请求(SELECT)则可以分散到多个从节点。
2. 在应用服务器上,可以使用诸如Apache、Nginx等Web服务器软件,通过配置实现读写分离逻辑。
3. 应用程序代码层面上,可以设置不同的数据库连接,针对不同的操作连接到不同的节点。例如,读操作连接从节点,写操作连接主节点。
### mermaid格式流程图
```mermaid
graph LR
A[客户端请求] -->|写请求| B[SQL节点主]
A -->|读请求| C[SQL节点从1]
A -->|读请求| D[SQL节点从2]
B -->|写操作| E[数据复制]
C -->|读操作| F[返回结果]
D -->|读操作| F
E -->|数据同步| C
E -
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“MySQL与Apache的集成使用”深入探讨了MySQL数据库和Apache服务器之间的集成策略。文章涵盖了从性能优化到数据同步、监控和连接池管理等各个方面。
专栏提供了10个优化技巧来提升MySQL和Apache的协同性能,6个负载均衡策略以高效分发请求,以及5个关键步骤以确保数据同步的一致性。此外,还介绍了监控工具和策略,以全面了解系统性能。
文章还探讨了内存管理优化、缓存策略、分布式部署和云环境中的集成。它提供了最佳实践案例、高级集成技巧和连接池管理与优化的深入分析。专栏还涵盖了高并发处理、事务管理和备份与恢复策略,为读者提供了全面的指南,以实现MySQL和Apache的无缝集成和高效操作。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
台达PLC DVP32ES2-C终极指南:从安装到高级编程的全面教程
参考资源链接:[台达DVP32ES2-C PLC安装手册:256点I/O扩展与应用指南](https://wenku.csdn.net/doc/64634ae0543f8444889c0bcf?spm=1055.2635.3001.10343)
# 1. 台达PLC DVP32ES2-C基础介绍
台达电子作为全球知名的自动化与电子组件制造商,其PLC(可编程逻辑控制器)产品广泛应用于工业自动化领域。DVP32ES2-C作为台达PL
【九齐8位单片机基础教程】:NYIDE中文手册入门指南
参考资源链接:[NYIDE 8位单片机开发软件中文手册(V3.1):全面教程](https://wenku.csdn.net/doc/1p9i8oxa9g?spm=1055.2635.3001.10343)
# 1. 九齐8位单片机概述
九齐8位单片机是一种广泛应用于嵌入式系统和微控制器领域的设备,以其高性能、低功耗、丰富的外设接口以及简单易用的编程环境而著称。本章将概览九齐8位单片机的基础知识
【西门子840 CNC报警速查秘籍】:快速诊断故障,精确锁定PLC变量

参考资源链接:[标准西门子840CNC报警号对应的PLC变量地址](https://wenku.csdn.net/doc/6412b61dbe7fbd1778d45910?spm=1055.2635.3001.10343)
# 1. 西门子840 CNC报警系统概述
## 1.1 CNC报警系统的作用
CNC(Computer Numerical Contro
数据结构基础精讲:算法与数据结构的7大关键关系深度揭秘
参考资源链接:[《数据结构1800题》带目录PDF,方便学习](https://wenku.csdn.net/doc/5sfqk6scag?spm=1055.2635.3001.10343)
# 1. 数据结构与算法的关系概述
数据结构与算法是计算机科学的两大支柱,它们相辅相成,共同为复杂问题的高效解决提供方法论。在这一章中,我们将探讨数据结构与算法的紧密联系,以及为什么理解它
QSGMII性能稳定性测试:掌握核心测试技巧

参考资源链接:[QSGMII接口规范:连接PHY与MAC的高速解决方案](https://wenku.csdn.net/doc/82hgqw0h96?spm=1055.2635.3001.10343)
Nginx HTTPS转HTTP:24个安全设置确保兼容性与性能

参考资源链接:[Nginx https配置错误:https请求重定向至http问题解决](https://wenku.csdn.net/doc/6412b6b5be7fbd1778d47b10?spm=1055.2635.3001.10343)
# 1. Nginx HTTPS转HTTP基础
在这一章中,我们将探索Nginx如何从HTTPS过渡
JVPX连接器设计精要:结构、尺寸与装配的终极指南
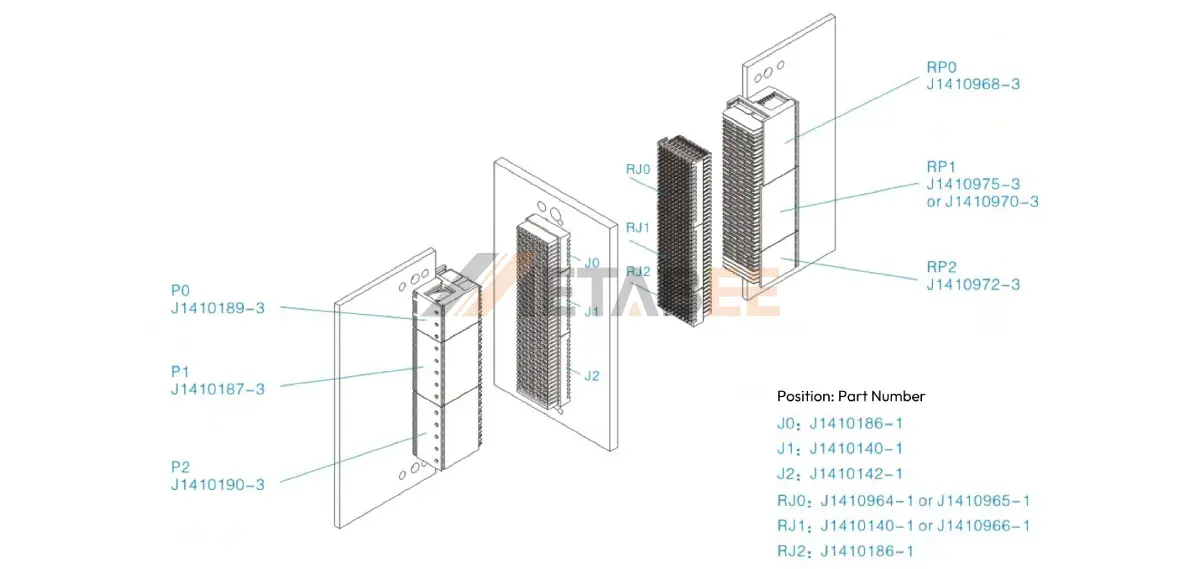
参考资源链接:[航天JVPX加固混装连接器技术规格与优势解析](https://wenku.csdn.net/doc/6459ba7afcc5391368237d7a?spm=1055.2635.3001.10343)
# 1. JVPX连接器概述与市场应用
JVPX连接器作为军事和航天领域广泛使用的一种精密连接器,其设计与应用展现了电子设备连接技术的先进性。本章节将首先探讨JVPX连接
STM32F405RGT6性能全解析:如何优化核心架构与资源管理
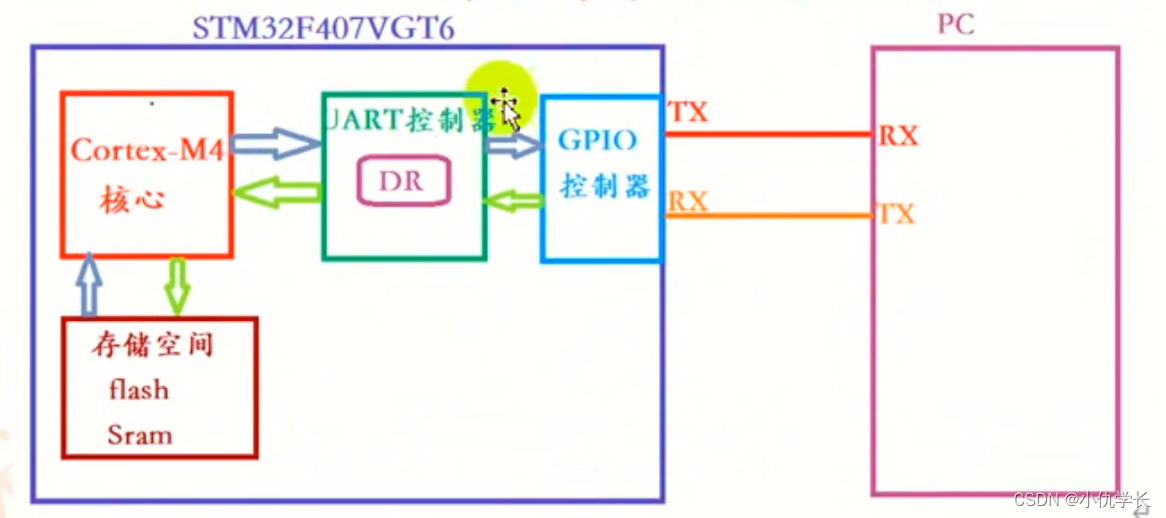
参考资源链接:[STM32F405RGT6中文参考手册:Cortex-M4 MCU详解](https://wenku.csdn.net/doc/6401ad30cce7214c316ee9da?spm=1055.2635.3001.10343)
# 1. STM32F405RGT6核心架构概览
STM32F405RGT6作为ST公司的一款高性能ARM Cortex-M4微控制器,其核心架构的设计是提升整体性能和效
数字集成电路设计实用宝典:第五章应用技巧大公开
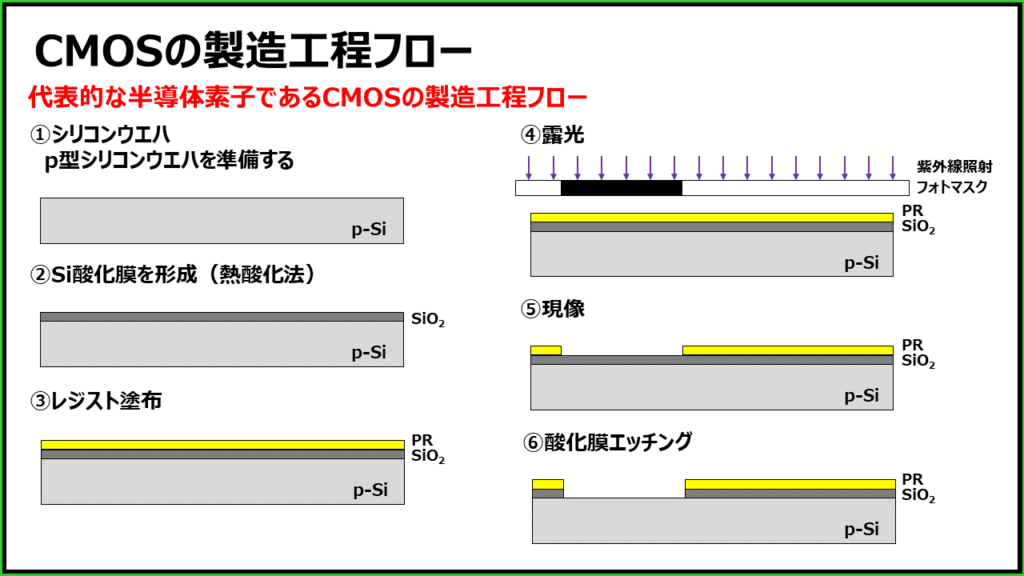
参考资源链接:[数字集成电路设计 第五章答案 chapter5_ex_sol.pdf](https://wenku.csdn.net/doc/64a21b7d7ad1c22e798be8ea?spm=1055.2635.3001.10343)
# 1. 数字集成电路设计基础
## 1.1 概述
数字集成电路是现代电子技术中的核心组件,它利用晶体管的开关特性来
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )