【Fluent中文数据压缩秘技】:提升导入导出效率的高效技巧
发布时间: 2024-12-14 14:19:48 阅读量: 1 订阅数: 3 

大批量fluent导出数据,针对超大导出数据.rar_-baijiahao_fluent data format_fluent中
参考资源链接:[SpaceClaim导入导出指南:支持多种文件格式](https://wenku.csdn.net/doc/2rqd6og2wc?spm=1055.2635.3001.10343)
# 1. Fluent中文数据压缩概览
在当今信息爆炸的时代,数据压缩技术对于存储和传输数据而言至关重要,尤其是在专业的计算流体动力学(CFD)软件Fluent中,这一需求显得尤为突出。Fluent作为一款广泛应用于工程仿真领域的软件,对数据压缩技术的依赖日渐增强,以提升数据处理效率和减少存储成本。
## 1.1 数据压缩在Fluent中的作用
在Fluent操作中,大量的计算数据需要存储和分析。有效运用数据压缩技术可以显著减少对存储资源的占用,并能加快数据在网络中的传输速率。此外,数据压缩在提高计算效率、优化资源分配以及降低计算成本等方面发挥着重要作用。
## 1.2 Fluent数据压缩的技术要求
Fluent用户在选择合适的数据压缩方法时需要考虑多方面的因素。例如,需要权衡压缩速度与压缩率之间的平衡,以及压缩算法是否适用于特定的计算场景。随着技术的发展,新的压缩技术不断涌现,用户应关注并利用这些技术来提高Fluent操作的效率和性能。
在接下来的章节中,我们将深入探讨数据压缩的理论基础,并详细介绍Fluent中数据压缩的实践技巧、高级应用以及未来展望。
# 2. 理解数据压缩理论基础
## 2.1 数据压缩的概念和必要性
### 2.1.1 数据冗余与压缩比
在信息技术领域,数据冗余是普遍存在的现象,指的是数据在存储或传输过程中出现的重复或者可预测的信息。这种冗余信息可能来源于用户的习惯性输入、数据记录的模式化、或者是数据本身的重复性。由于冗余的存在,数据往往比其实际所需占用的空间更大。数据压缩技术的核心目标就是识别并去除这些冗余部分,从而实现数据的精简存储或传输。
压缩比是衡量数据压缩效率的一个重要指标,它表示的是原始数据大小与压缩后数据大小的比例。一个高压缩比意味着更少的存储空间和更快的数据传输速度,但在某些情况下也可能意味着更高的计算资源消耗和压缩/解压时间。因此,在不同的应用场景中,对于压缩比的追求需要根据实际情况做出适当的平衡。
### 2.1.2 常见的数据压缩算法原理
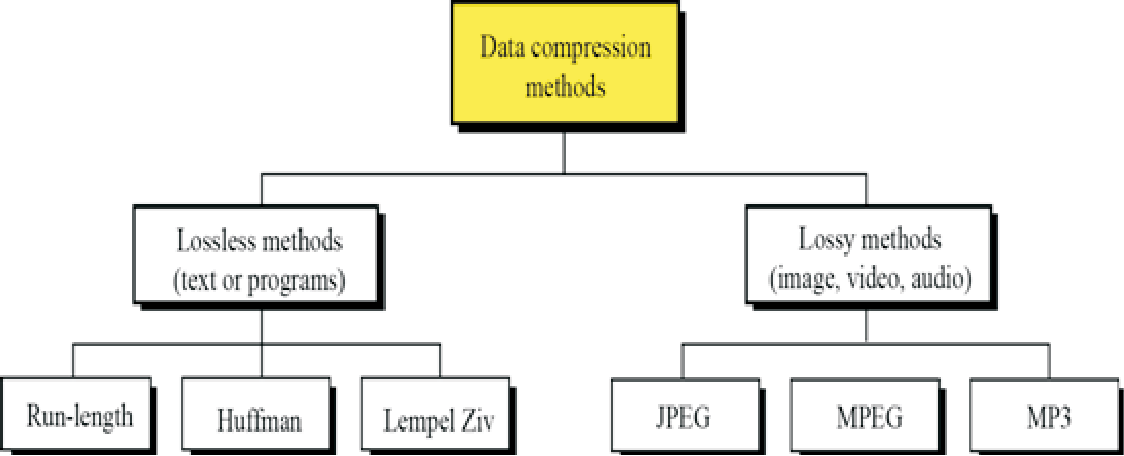
数据压缩算法根据压缩方式的不同,可以大致分为两大类:无损压缩和有损压缩。
- 无损压缩算法(Lossless Compression Algorithms)保留了原始数据的所有信息,因此压缩后的数据可以完全还原为原始数据。这类算法通常用于需要精确数据的应用场合,如文本文件、程序代码、数据库等。常见的无损压缩算法包括ZIP、GZIP、LZ77、LZ78、LZW和Deflate等。
- 有损压缩算法(Lossy Compression Algorithms)在压缩过程中会丢失一部分原始数据的信息。这种压缩方式通常用于音视频数据的压缩,因为人类对这些信息的感知具有一定的冗余度,丢失一部分信息不会严重影响用户体验。典型的有损压缩算法包括JPEG、MP3和MPEG等。
## 2.2 数据压缩技术的分类
### 2.2.1 无损压缩与有损压缩
无损压缩和有损压缩在信息处理中有着本质的区别。无损压缩算法由于不丢失任何数据,因此对于数据的完整性要求较高,常用于要求严格的应用场景。而有损压缩则通过牺牲一定的数据精度来换取更高的压缩率,适用于对压缩速度和存储空间要求更高的场景。
### 2.2.2 静态压缩与动态压缩
从压缩算法处理数据的方式来看,数据压缩技术又可以分为静态压缩和动态压缩。
- 静态压缩算法(Static Compression Algorithms)在压缩过程中不需要考虑数据的整体特性,仅根据固定的数据模型和统计特性进行压缩。这类算法通常适用于数据流的压缩,如文件压缩工具。
- 动态压缩算法(Dynamic Compression Algorithms)则需要观察数据的输入流,根据数据流的统计特性和模式变化,动态地调整压缩策略。这类算法往往能够达到更高的压缩效率,但实现起来更为复杂。
## 2.3 压缩算法的选择标准
### 2.3.1 压缩速度与压缩率的平衡
选择合适的压缩算法需要考虑多个因素。首先,压缩速度和压缩率是需要权衡的两个重要参数。快速的压缩算法(如LZ4)能够提供更快的压缩和解压缩速度,但可能牺牲一部分压缩率。而对于追求高压缩比的场景(如某些备份场景),则可能需要选择压缩速度相对较慢但压缩率较高的算法(如Deflate)。
### 2.3.2 算法的适用场景分析
不同的压缩算法适合不同的应用场景。例如,文本数据和程序代码通常采用无损压缩算法,如GZIP和Zstandard(zstd),以保证数据的完整性和精确性。而对于音频和视频数据,由于人眼和人耳的感知有限,可以采用有损压缩算法以大幅提高压缩效率。
接下来,我们将探讨Fluent数据压缩实践技巧,以及如何在实际应用中高效地使用这些理论知识。
# 3. Fluent数据压缩实践技巧
## 3.1 Fluent中压缩算法的配置与使用
### 3.1.1 Fluent内置压缩功能的设置
Fluent作为一个广泛使用的计算流体动力学(CFD)软件,为用户提供了内置的数据压缩功能,以优化存储空间和减少数据传输时间。配置Fluent的内置压缩功能通常涉及调整求解器的参数设置,以达到最优的压缩效果和性能平衡。
在Fluent的求解器设置中,可以通过以下步骤启用和配置内置压缩算法:
- 打开Fluent求解器,并加载你的案例文件。
- 进入求解器的设置菜单,选择 "File Operations"。
- 在 "File Operations" 设置中找到 "Data Storage" 部分。
- 开启 "Compress Output Data" 选项。
- 根据需要调整压缩级别。Fluent通常提供几个压缩级别,从低到高分别适用于不同程度的压缩需求。
在启用压缩功能后,Fluent将对保存的数据文件进行压缩处理,减少磁盘空间的占用。不过值得注意的是,压缩和解压缩的过程会消耗一定的CPU资源,特别是在处理大量数据时。因此,在性能和压缩率之间找到一个平衡点是至关重要的。
```plaintext
# 示例:启用Fluent内置压缩功能的伪代码命令
# 注意:这不是真实的Fluent命令,仅为说明概念所用
set file_operation_compression = true;
set compression_level = 5;
```
这段伪代码展示了如何在Fluent中设置启用数据压缩,并指定压缩级别。虽然实际的Fluent设置步骤可能更为复杂,但关键在于理解不同压缩级别对资源消耗和压缩效果的影响。
### 3.1.2 第三方压缩工具在Fluent中的应用
尽管Fluent自带了数据压缩的功能,但在某些情况下,可能需要更专业的压缩工具来满足特定需求。例如,面对特别大的数据集,或者在特定的计算和存储环境下,内置功能可能不足以提供最佳的压缩效果。这时,可引入第三方压缩工具来进一步优化数据处理流程。
在Fluent中集成第三方压缩工具主要通过以下几个步骤进行:
- 选择一个适合Fluent输出数据格式的压缩工具,例如7-Zip、WinRAR或TAR等。
- 在Fluent的求解器脚本中,添加外部压缩工具的调用代码。这可以通过执行系统命令实现,如使用Python或bash脚本。
- 在Fluent后处理阶段,脚本将自动调用指定的压缩工具处理输出数据。
- 配置压缩工具的参数,例如选择压缩算法、设置压缩比等,以适应数据特点和需求。
```bash
# 示例:通过Bash脚本调用第三方压缩工具
# 注意:这是一个示例命令,用于说明如何在脚本中嵌入压缩工具
zip -9 output.zip output.dat
```
该命令使用zip工具压缩Fluent生成的输出文件,其中 `-9` 参数表示使用最大压缩比。通过这种方式,可以灵活地利用不同的压缩工具和参数来优化压缩效果。
## 3.2 数据导入导出流程优化
### 3.2.1 批量处理与自动化脚本
在处理大量数据时,使用批量处理和自动化脚本可以极大地提高效率。在Fluent的上下文中,自动化脚本可以用来自动化数据的导入、求解过程以及导出压缩数据的流程。这样不仅可以减少人工操作的繁琐,还能确保流程的一致性。
批量处理的关键在于能够编写脚本,使得程序能够自动识别并处理一批文件,而不是一个一个单独处理。在Fluent中,可以使用ANSYS提供的宏或者外部脚本语言(如Python、TCL)来实现这一点。
下面是一个简单的Python脚本示例,该脚本使用Fluent的Python API来批量处理多个案例文件:
```python
imp
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【SIPP基础操作指南】:手把手教你使用SIPP进行测试(从零开始)

参考资源链接:[Maple软件基础操作指南:注释与计算](https://wenku.csdn.net/doc/17z6cduxsj?spm=1055.2635.3001.10343)
# 1. SIPP简介和安装配置
## 1.1 SIPP概述
SIPp 是一个开源的测试工具,专门用于发起和处
CST旋转体仿真:掌握精确模拟与分析的5大技巧
参考资源链接:[CST建模教程:如何绘制旋转椭球体](https://wenku.csdn.net/doc/6401ac12cce7214c316ea870?spm=1055.2635.3001.10343)
# 1. CST仿真软件概述
CST Studio Suite是电磁仿真软件领域的佼佼者,广泛应用于雷达、天线、高频电路、电磁兼容(EMC)等领域。本章旨在为读者提供一个关于CST软
移动开发黎明纪实:iOS与Android,开启移动革命的钥匙
参考资源链接:[不吹牛-庚寅年2010年第一期教材690页.pdf](https://wenku.csdn.net/doc/6412b722be7fbd1778d4935d?spm=1055.2635.3001.10343)
# 1. 移动开发的起源与兴起
## 1.1 移动开发的历史回顾
在移动互联网的浪潮中,移动开发从早期的功能手机时代发展到如今的智能手机全盛时期。最初的移动应用多为静态的信息展示和基础交互,随着技术的发展,移动应用逐渐整合了更多的功能,比如音频、视频播放,复杂的用户界面(UI)以及云服务的接入。
## 1.2 移动操作系统的竞争
移动开发的兴起离不开两大主流操作系统的
G7SA安全继电器安装指南:一步到位的安装与故障排除秘籍
参考资源链接:[欧姆龙安全继电器单元G7SA系列产品介绍](https://wenku.csdn.net/doc/6463338e5928463033bdab89?spm=1055.2635.3001.10343)
# 1. G7SA安全继电器概述
## 1.1 安全继电器的定义与重要性
安全继电器是工业控制系统中的关键安全设备,用于监控和控制机械设备的安全功能。G7SA安全继电器是其中的代表型号,它具有高性能和可靠性,能够在紧急情况下快速切断电源,保护人员和设备的安全。在工业自动化领域,安全继电器是确保生产过程安全、符合法规要求的必备设备。
## 1.2 G7SA安全继电器的核心优势
G
WinCC VBS性能优化:提升脚本运行效率的关键技巧
参考资源链接:[wincc vbs手册中文](https://wenku.csdn.net/doc/6412b756be7fbd1778d49eef?spm=1055.2635.3001.10343)
# 1. WinCC VBS基础和脚本编写
## 1.1 WinCC VBS概述
WinCC(Windows Control Center)是西门子公司推出的一
【SPiiPlus MMI编程接口详解】:轻松集成与自定义,实现技术飞跃
参考资源链接:[2020 SPiiPlus MMI应用工作室用户指南(v3.02)](https://wenku.csdn.net/doc/6v6i2rq0ws?spm=1055.2635.3001.10343)
# 1. SPiiPlus MMI编程接口概览
在现代工业自动化领域中,SPiiPlus MMI编程接口扮演着至关重要的角色,它为用户提供了与自动化设备进行交互的平台,通过这个接口可以实现对设备的监控和控制。本章将为读者提供一个关于SPiiPlus MMI编程接口的全面概览,以便为后续章节的详细讨论打下坚实的基础。
## 1.1 接口的核心价值
SPiiPlus MMI编程接口的
【美的智能制造的终极攻略】:掌握数据驱动决策,优化生产流程

参考资源链接:[美的三年智能制造规划:精益智能工厂与数字化转型策略](https://wenku.csdn.net/doc/74kekgm9f1?spm=1055.2635.3001.10343)
# 1. 数据驱动决策的力量
在当今这个快速变化的商业环境中,数据驱动决策已成为提升企业竞争力的
深入掌握iFix数据架构:专家解读高效数据传输到SQL Server技巧
参考资源链接:[iFix组态软件实时数据获取与SQL Server存储步骤](https://wenku.csdn.net/doc/6412b762be7fbd1778d4a19f?spm=1055.2635.3001.10343)
# 1. iFix数据架构概述
## 1.1 iFix数据架构简介
iFix数据
Conformal ECO流程与设计自动化
参考资源链接:[揭秘Conformal ECO流程:关键步骤与命令详解](https://wenku.csdn.net/doc/6r74x366qb?spm=1055.2635.3001.10343)
# 1. Conformal ECO流程概述
## 1.1 ECO流程简介
ECO(Engineering Change Order)流程是集成电路设计与制造中的关键步骤,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )