【数据科学容器化】:Anaconda环境与Docker实战攻略
发布时间: 2024-12-07 07:09:31 阅读量: 12 订阅数: 20 

Python 数据科学工具 Anaconda 的全面安装与使用指南
# 1. 数据科学容器化的概念与优势
数据科学容器化指的是将数据科学工作所需的软件环境、库和工具打包到容器中,以便在任何环境中快速部署和运行。容器化技术如Docker,使得数据科学工作流程与开发环境分离,确保了代码在不同系统间的一致性,提高了协作和部署的效率。
## 1.1 容器化的基本概念
容器化技术基于操作系统级虚拟化,它允许用户在一个隔离的环境中运行应用程序,每个容器都包含了运行应用程序所需的一切:代码、运行时环境、系统工具、系统库等。Docker是最流行的容器化平台之一,通过利用Docker,开发者可以轻松地创建、部署和运行容器。
## 1.2 容器化与虚拟机的区别
容器化不同于传统的虚拟机,因为它不需要运行一个完整的操作系统。容器共享主机操作系统的内核,使得它们更加轻量、启动速度更快,并且资源占用更少。这种轻量级的特性使得容器特别适合于运行单一应用程序或服务,从而优化资源使用并提高密度。
## 1.3 容器化技术的优势
在数据科学领域,容器化带来了诸多优势:
- **一致性**:确保了数据科学家的工作环境在不同机器和部署之间的一致性。
- **可移植性**:开发人员可以在本地开发,然后无缝迁移到生产环境,无需担心环境差异问题。
- **独立性**:每个容器独立运行,避免了不同项目间的依赖冲突。
- **扩展性**:容器化应用可以轻松扩展,特别是在云环境中,可以根据需求动态地启动或停止容器实例。
通过本章的内容,我们对数据科学容器化有了初步的了解,接下来我们将深入探讨如何设置Anaconda环境,这是数据科学工作流中不可或缺的一部分。
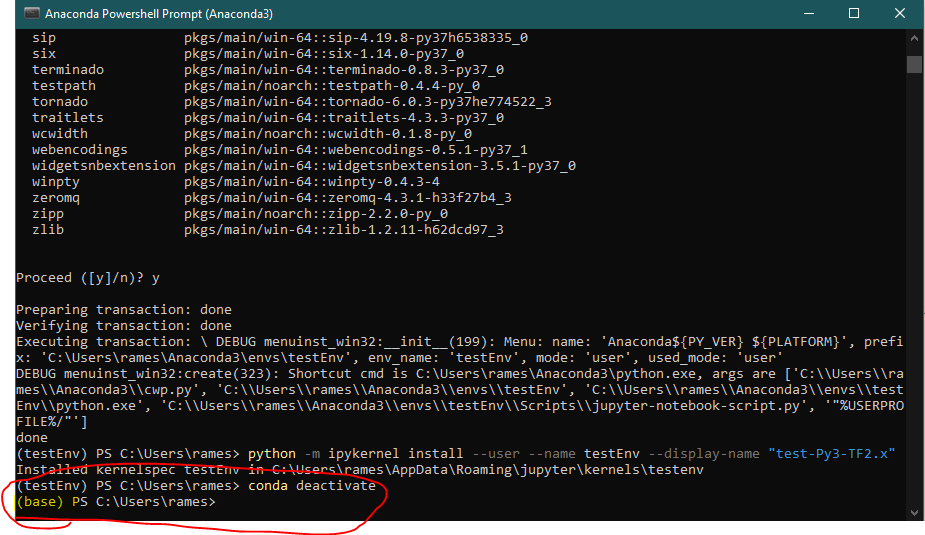
# 2.2 Anaconda环境包管理工具的使用
### 2.2.1 conda命令的基本使用方法
`conda` 是 Anaconda 环境的包管理工具,它允许用户轻松地安装、更新、删除包以及管理多个环境。`conda` 命令的使用是 Anaconda 环境管理的基础。
首先,让我们安装一个包。以下命令会安装最新版本的 NumPy 库:
```bash
conda install numpy
```
在这个命令执行过程中,`conda` 会自动检查并解决包之间的依赖关系。如果系统中已经存在该包的其他版本,`conda` 会询问是否要进行替换。
查看已安装的包可以使用:
```bash
conda list
```
这会展示当前环境的所有已安装包及其版本信息。若要更新某个包至最新版本,使用:
```bash
conda update numpy
```
删除包的命令是:
```bash
conda remove numpy
```
这些基本命令构成了`conda`日常使用的核心部分。在使用`conda`管理包时,需要考虑到包的版本兼容性以及环境的隔离性。
### 2.2.2 环境与包的创建、管理及导出
`conda` 的强大之处不仅在于包的管理,还在于环境的管理。创建一个新的环境,可以使用:
```bash
conda create --name myenv
```
这将创建一个名为 `myenv` 的环境。如果要安装特定包到新环境中,可以添加 `-p` 参数指定包名:
```bash
conda create --name myenv numpy
```
管理环境还包括激活、停用等操作。在 Windows 系统中,激活环境的命令是:
```bash
activate myenv
```
在 Linux 或 macOS 系统中,则使用:
```bash
conda activate myenv
```
停用环境使用的是:
```bash
conda deactivate
```
导出当前环境配置到一个文件,方便之后在其他机器上复现相同环境:
```bash
conda env export > environment.yaml
```
通过这个 YAML 文件,可以使用 `conda env create` 命令在任何新环境中重现相同的环境配置。
### 环境变量与命令解析
在进行上述操作时,`conda` 命令背后依赖于环境变量。例如,激活一个环境会改变 `PATH` 环境变量,以确保激活的环境中可执行文件的优先访问。`conda` 还支持创建、管理和导出包含 Python 和其他语言解释器的环境,以满足复杂的数据科学需求。
解析这些 `conda` 命令的参数和执行逻辑,可以看到 `conda` 对环境和包的管理非常灵活,而这些功能对于维护一致、隔离的工作环境至关重要,特别是在多人协作的项目中。通过合理使用 `conda` 管理数据科学环境,可以显著提高开发效率,同时减少因依赖问题引起的错误。
接下来的章节将会展示如何将 Jupyter Notebook 应用到 Anaconda 环境中,并深入了解如何通过 Notebook 实现复杂的数据科学工作流程。
# 3. Docker技术原理及入门
## 3.1 Docker的基本概念与架构
### 3.1.1 容器与虚拟机的比较
在深入理解Docker之前,首先需要厘清容器(Container)和虚拟机(Virtual Machine, VM)的概念及其差异。虚拟机通过在宿主机上运行一个虚拟机管理程序(Hypervisor),提供完整的操作系统环境,每个虚拟机都是一个完整的系统实例,拥有自己的操作系统内核。这种方式能够隔离不同的工作负载,但同时也带来了较大的资源开销,因为每个虚拟机都需要独立的系统镜像以及相应的硬件资源。
相对地,容器技术通过在单一操作系统实例上隔离应用程序及其依赖,从而实现轻量级的虚拟化。容器共享宿主机的操作系统内核,不需运行整个操作系统,因此启动速度更快,资源占用更少。此外,容器之间共享内核资源,使得容器可以更轻量级,更便于迁移和扩展。
### 3.1.2 Docker的核心组件解析
Docker由几个核心组件构成,包括Docker引擎(Docker Engine)、Docker客户端(Docker Client)、Docker镜像(Docker Image)、Docker容器(Docker Container)、Docker仓库(Docker Repository)等。
- **Docker引擎**:是Docker平台的核心,负责构建、运行和分发Docker容器。它包含Docker守护进程、REST API接口和CLI(命令行接口)。
- **Docker客户端**:是与Docker守护进程交互的用户界面,提供用户操作Docker引擎的命令。
- **Docker镜像**:是创建容器的模板,包含了运行应用程序所需的一切内容,包括代码、运行时、库、环境变量和配置文件。
- **Docker容器**:是从Docker镜像创建的运行实例,可以被启动、停止、移动、删除等操作。
- **Docker仓库**:用于存储和共享Docker镜像的场所。Docker Hub是公共仓库,用户也可以设置私有仓库。
Docker的这些核心组件共同作用,使得开发者能够高效地打包、分发和部署应用。
## 3.2 Docker的基本操作与镜像管理
### 3.2.1 Docker的安装与基础命令
在安装Docker之前,需要根据操作系统(如Linux, macOS, Windows等)准备好相应的环境。Docker官方提供了详细的安装指南,对于大多数主流操作系统,都可以通过包管理工具或安装器快速完成安装。
一旦安装成功,可以通过Docker命令行工具与Docker守护进程进行交互。这里列出几个常见的基础命令:
- `docker run`: 用于运行一个新的容器实例。
```bash
docker run -it --name myUbuntu ubuntu /bin/bash
```
以上命令以交互模式运行一个名为`myUbuntu`的容器,并连接到ubuntu镜像启动的bash shell。`-it`选项允许用户与容器进行交互。
- `docker ps`: 列出当前运行中的容器。
- `docker images`: 显示已下载的镜像列表。
- `docker stop`: 停止一个运行中的容器。
- `docker rm`: 删除一个或多个容器。
- `docker rmi`: 删除一个或多个镜像。
### 3.2.2 镜像的构建、查找与管理
Docker镜像是构建容器的蓝图,用户可以通过Dockerfile来定义应用程序及其依赖。Dockerfile是一个文本文件,包含了所有构建镜像所需的命令。
- **构建镜像**:
```Dockerfile
FROM python:3.8
COPY . /app
WORKDIR /app
RUN pip install -r requirements.txt
CMD ["python", "app.py"]
```
以这个简单的Dockerfile为例,构建镜像的过程只需执行:
```bash
docker build -t myapp .
```
这条命令根据当前目录下的Dockerfile构建一个名为`mya

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面探讨了 Anaconda 环境管理的最佳实践,涵盖了从包管理和依赖性解析到内存优化和网络配置等各个方面。它提供了深入的见解和实用技巧,帮助您破解 Anaconda 中的包管理难题,减少资源消耗,集成第三方工具和库,设置离线安装和私有仓库,分析 Python 解释器的性能和兼容性,优化环境性能,并有效管理元数据。通过遵循这些最佳实践,您可以充分利用 Anaconda 的强大功能,创建高效、可维护且可扩展的 Python 环境。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
西门子Insight软件:新手必读的7大操作要点与界面解读
参考资源链接:[西门子Insight软件用户账户管理操作手册](https://wenku.csdn.net/doc/6412b78abe7fbd1778d4aa90?spm=1055.2635.3001.10343)
# 1. 西门子Insight软件概述
## 1.1 软件简介
西门子Insight软件是一款面向工业设备和生产线的先进监控与数据分析解决方案。它将实时数据可视化和
【BODAS通信协议详解】:3大关键点,精通控制器与外部设备交互

参考资源链接:[BODAS控制器编程指南:从安装到下载的详细步骤](https://wenku.csdn.net/doc/6ygi1w6m14?spm=1055.2635.3001.10343)
# 1. BODAS通信协议概述
BODAS通信协议,作为工业自动化领域内的一项重要技术标准,确保了不同设备之间的高效、准确通信。在深入探究其内部工作机制之前,我们需要对其基本概念有所了解。本章主要介绍了BODAS协议
【CAD软件兼容性宝典】:确保许可管理器与OS完美结合

参考资源链接:[CAD提示“许可管理器不起作用或未正确安装。现在将关闭AutoCAD”的解决办法.pdf](https://wenku.csdn.net/doc/644b8a65ea0840391e559a08?spm=1055.2635.3001.10343)
# 1. CAD软件兼容性的重要性
CAD(计算机辅助
【Innovus命令行快速指南】:掌握这些技巧,让你从新手变大师
参考资源链接:[Innovus P&R 操作指南与流程详解](https://wenku.csdn.net/doc/6412b744be7fbd1778d49af2?spm=1055.2635.3001.10343)
# 1. Innovus命令行基础介绍
Innovus是Cadence公司推出的一款用于芯片设计的集成电路设计软件,其强大的命令行工具支持从设计、仿真到验证
深度剖析:巡检管理系统单机版A1.0的八大核心功能

参考资源链接:[巡检管理系统单机版A1.0+安装与使用指南](https://wenku.csdn.net/doc/6471c33c543f844488eb0879?spm=1055.2635.3001.10343)
# 1. 巡检管理系统单机版A1.0概览
巡检管理系统单机版A1.0是一个创新的IT解决方案,旨在实现资产的自动化管理,简化巡检流程,提升维护工作的效率和质量。本章节将提供一个整体性的概览,包括系统的基本功能、
STC89C52指令集精讲:助你迅速成为编程高手的50条指令详解
参考资源链接:[STC89C52单片机中文手册:概览与关键特性](https://wenku.csdn.net/doc/70t0hhwt48?spm=1055.2635.3001.10343)
# 1. STC89C52单片机简介及指令集概述
STC89C52单片机是基于经典的8051架构,广泛应用于嵌入式系统的开发中。它拥有8位处理器核心,其指令集简洁高效,针对实时控制应用进行了优化。本章将对STC89C52单片机进
【LabVIEW错误代码防不胜防】:开发者的10大陷阱与解决方案
参考资源链接:[LabVIEW错误代码大全:快速查错与定位](https://wenku.csdn.net/doc/7am571f3vk?spm=1055.2635.3001.10343)
# 1. LabVIEW错误代码的由来和影响
当我们进行LabVIEW开发时,错误代码是不可避免的。错误代码通常由不正确的程序执行引起,它们提供了解决问题的线索。了解错误代码的由来和
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )