认识Tornado框架:快速入门指南
发布时间: 2024-02-14 01:28:19 阅读量: 48 订阅数: 38 
# 1. 引言
## 1.1 什么是Tornado框架
Tornado是一个Python的Web框架和异步网络库,最初由FriendFeed开发,后被Facebook开源。它非常适合处理高并发的情况,特别是对于长连接的支持非常强大。Tornado被广泛应用于构建实时Web服务,Web应用程序和API。
## 1.2 Tornado框架的特点和优势
Tornado框架的主要特点包括:
- 异步非阻塞IO模型,适合高性能的网络应用
- 轻量级的Web框架,易于学习和上手
- 对长连接和实时应用的支持非常出色
- 内置支持WebSocket和协程
- 提供HTTP客户端和服务器,方便进行HTTP通信
## 1.3 为什么选择Tornado框架
选择Tornado框架的原因包括:
- 高性能的异步IO模型,适合处理大量并发连接
- 轻量级灵活,适合构建实时Web应用和API
- 内置支持WebSocket,方便构建实时通信系统
通过本指南,您将了解如何安装、使用和部署Tornado框架,以及它的核心概念和高级用法。
# 2. 安装和设置Tornado框架
Tornado框架的安装和设置是使用该框架的第一步。在这一章节中,我们将学习如何安装Python和pip,使用pip进行Tornado框架的安装,以及创建和设置Tornado项目的过程。
### 2.1 安装Python和pip
在开始学习Tornado框架之前,首先需要安装Python和pip。Python是Tornado框架的运行环境,而pip是Python的包管理工具,可以用来安装Tornado框架及其依赖包。
```python
# 确保已安装Python
python --version
# 确保已安装pip
pip --version
```
### 2.2 使用pip安装Tornado框架
一旦安装了Python和pip,就可以使用pip来安装Tornado框架了。
```python
# 使用pip安装Tornado框架
pip install tornado
```
### 2.3 创建和设置Tornado项目
在本节中,我们将学习如何创建和设置一个基本的Tornado项目,并进行一些基本的配置。
```python
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, Tornado")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上面的代码中,我们创建了一个简单的Tornado应用,当用户访问根路径时,会看到"Hello, Tornado"的文本响应。
通过本章节的指南,你已经学会了如何安装Python和pip,使用pip安装Tornado框架,以及创建和设置一个简单的Tornado项目。下一步,我们将深入学习Tornado框架的使用方法。
**总结:**
在本章中,我们学习了安装Python和pip,使用pip安装Tornado框架,以及创建和设置Tornado项目的过程。同时,我们还编写了一个简单的Tornado应用程序来验证安装和设置的正确性。
# 3. 开始使用Tornado
#### 3.1 编写第一个Tornado应用程序
下面我们将通过编写一个简单的"Hello, Tornado!"应用程序来开始学习如何使用Tornado框架。
首先,我们需要创建一个Python文件,命名为`app.py`:
```python
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, Tornado!")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上面的代码中,我们首先导入了`Tornado`的两个模块:`tornado.ioloop`和`tornado.web`。接下来,我们定义了一个名为`MainHandler`的请求处理类,它继承自`RequestHandler`类。在`MainHandler`类中,我们只定义了一个`get`方法,当有`GET`请求访问根路由时,会调用该方法。
然后,我们定义了一个名为`make_app`的函数,该函数用于创建一个`Tornado`的应用实例。在`make_app`函数中,我们将根路由和对应的处理类进行了映射。
最后,我们通过判断`__name__`是否为`__main__`来运行该应用程序。`app.listen(8888)`将应用程序绑定到本地的`8888`端口上,`tornado.ioloop.IOLoop.current().start()`启动了`Tornado`的事件循环。
保存文件后,在命令行中执行以下命令启动应用程序:
```bash
python app.py
```
现在,你可以在浏览器中访问`http://localhost:8888/`,你将会看到页面上显示"Hello, Tornado!"。
代码解释:我们定义了一个名为`MainHandler`的请求处理类,该类继承自`tornado.web.RequestHandler`。在`MainHandler`类中,我们重写了`get`方法,当接收到`GET`请求时,会向客户端返回"Hello, Tornado!"字符串。
通过`make_app`函数创建了一个`Tornado`应用实例,并将根路由`'/'`和对应的`MainHandler`类进行了映射。通过`app.listen(8888)`将应用程序绑定到本地的`8888`端口上,然后通过`tornado.ioloop.IOLoop.current().start()`启动了事件循环来监听并处理请求。
这样,我们就成功地创建并运行了我们的第一个`Tornado`应用程序。接下来,我们将学习如何创建路由处理程序和处理HTTP请求和响应。
#### 3.2 创建路由处理程序
在`Tornado`中,可以通过编写不同的处理类来处理不同的路由。
首先,我们创建一个新的文件`handlers.py`,用于存放我们的路由处理类。
```python
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, Tornado!")
class AboutHandler(tornado.web.RequestHandler):
def get(self):
self.write("This is the About page.")
```
在上面的代码中,我们定义了两个处理类:`MainHandler`和`AboutHandler`。`MainHandler`用于处理根路由`/`的请求,`AboutHandler`用于处理`/about`的请求。
然后,我们需要在`app.py`中添加这些路由和对应的处理类:
```python
import tornado.ioloop
import tornado.web
from handlers import MainHandler, AboutHandler
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
(r"/about", AboutHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上面的代码中,我们通过`from handlers import MainHandler, AboutHandler`导入了之前定义的处理类。然后,在`make_app`函数中,将`"/about"`路由和`AboutHandler`类进行映射。
保存文件并重新运行应用程序,然后在浏览器中访问`http://localhost:8888/about`,你将会看到页面上显示"This is the About page."。
代码解释:我们定义了一个`MainHandler`类和一个`AboutHandler`类,分别用于处理根路由`/`和`/about`的请求。在这两个类中,我们分别重写了`get`方法,并向客户端返回不同的字符串。
在`app.py`中,通过`from handlers import MainHandler, AboutHandler`导入了之前定义的处理类。然后,在`make_app`函数中,将`"/about"`路由和`AboutHandler`类进行了映射。
这样,我们就成功地创建了多个路由和对应的处理类,实现了不同路由的访问功能。下一节,我们将学习如何处理HTTP请求和响应。
#### 3.3 处理HTTP请求和响应
在`Tornado`中,可以通过`RequestHandler`类提供的方法来处理HTTP请求和生成HTTP响应。
首先,我们添加一个新的路由`/message`和对应的处理类`MessageHandler`:
```python
class MessageHandler(tornado.web.RequestHandler):
def get(self):
self.render("message.html")
def post(self):
message = self.get_argument("message")
self.write(message)
```
在上面的代码中,我们定义了一个`MessageHandler`类,用于处理`/message`的请求。在`get`方法中,我们调用了`render`方法来渲染一个名为`message.html`的模板文件,在后面的章节中我们将会详细介绍如何使用模板。
在`post`方法中,我们使用`self.get_argument("message")`来获取客户端POST请求中的`message`参数,并通过`self.write`向客户端返回这个参数。
然后,我们需要在`app.py`中添加这个路由和处理类:
```python
from handlers import MainHandler, AboutHandler, MessageHandler
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
(r"/about", AboutHandler),
(r"/message", MessageHandler),
])
```
在上面的代码中,我们将`"/message"`路由和`MessageHandler`类进行了映射。
保存文件并重新运行应用程序,然后在浏览器中访问`http://localhost:8888/message`,你将看到一个空白页面。现在,我们尝试向这个页面发送一个`POST`请求来传递一个`message`参数,可以使用`curl`命令或者使用浏览器中的开发者工具的`Network`面板来发送这个请求。
例如,使用`curl`命令来发送一个`POST`请求,并传递一个`message`参数:
```bash
curl -XPOST -d "message=Hello Tornado!" http://localhost:8888/message
```
你将会在命令行中看到返回的结果是"Hello Tornado!"。
这样,我们就成功地处理了HTTP请求,并向客户端返回了相应的结果。
代码解释:我们定义了一个`MessageHandler`类,用于处理`/message`的请求。在`get`方法中,我们调用了`render`方法来渲染一个名为`message.html`的模板文件。在`post`方法中,我们使用`self.get_argument`方法来获取客户端POST请求中的`message`参数,并通过`self.write`向客户端返回这个参数。
在`app.py`中,我们将`"/message"`路由和`MessageHandler`类进行了映射。
在浏览器中访问`http://localhost:8888/message`,你将看到一个空白页面。通过发送一个`POST`请求,并传递一个`message`参数,我们可以得到返回的结果。
下一节,我们将学习如何添加模板和静态文件。
#### 3.4 添加模板和静态文件
在`Tornado`中,可以通过使用模板来生成动态的HTML页面,也可以通过使用静态文件来提供CSS、JavaScript等静态资源。
首先,我们需要创建一个名为`templates`的文件夹,并在其中添加一个`message.html`的模板文件:
```html
<!DOCTYPE html>
<html>
<head>
<title>Message</title>
<link rel="stylesheet" type="text/css" href="/static/style.css">
</head>
<body>
<h1>Message</h1>
<form action="/message" method="post">
<input type="text" name="message" placeholder="Enter message">
<button type="submit">Submit</button>
</form>
</body>
</html>
```
在上面的代码中,我们定义了一个简单的HTML页面,其中使用了`/static/style.css`的样式文件。
然后,我们需要在`app.py`中添加静态文件的配置:
```python
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
(r"/about", AboutHandler),
(r"/message", MessageHandler),
], static_path=os.path.join(os.path.dirname(__file__), "static"))
```
在上面的代码中,我们通过`static_path`参数指定了静态文件的路径为当前文件所在目录下的`static`文件夹。
保存文件并重新运行应用程序,然后在浏览器中访问`http://localhost:8888/message`,你将看到一个表单页面,输入信息并点击"Submit"按钮,将会返回输入的文本信息。
代码解释:我们添加了一个名为`message.html`的模板文件,在该模板文件中,我们引入了一个CSS样式文件`/static/style.css`。
在`app.py`中,通过`static_path`参数指定了静态文件的路径为当前文件所在目录下的`static`文件夹。
这样,我们就成功地添加了模板和静态文件,并使用模板生成动态的HTML页面,同时提供了静态资源。
通过本章的学习,我们已经了解了如何使用`Tornado`框架创建路由处理程序、处理HTTP请求和响应,以及添加模板和静态文件。在下一章,我们将深入学习`Tornado`框架的核心概念。
# 4. Tornado框架的核心概念
Tornado框架作为一个高性能的Web框架,其核心概念涉及到异步和非阻塞IO、协程和生成器、回调和事件循环以及Tornado的事件驱动架构。理解这些核心概念是使用Tornado框架的关键,下面将详细介绍每个概念的作用和原理。
#### 4.1 异步和非阻塞IO
在传统的同步IO模型中,一个IO操作会阻塞整个进程或线程,直到IO操作完成才能继续执行下一步。而在Tornado框架中,采用了异步和非阻塞的IO模型,即IO操作不会阻塞整个进程或线程的执行,而是通过回调函数的方式在IO操作完成后再执行对应的处理逻辑。这种模型可以极大地提高并发处理能力,使得服务器能够更高效地处理大量的IO密集型任务。
```python
import tornado.ioloop
import tornado.web
import time
class MainHandler(tornado.web.RequestHandler):
async def get(self):
self.write("Start\n")
await self.sleep(5)
self.write("End\n")
async def sleep(self, seconds):
await tornado.ioloop.IOLoop.current().run_in_executor(None, lambda: time.sleep(seconds))
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
* 代码说明:上述代码演示了在Tornado框架中如何使用异步和非阻塞IO模型,通过`tornado.ioloop.IOLoop.current().run_in_executor`实现了异步的延时操作。
* 代码总结:Tornado框架的异步和非阻塞IO模型能够让程序在IO操作时不被阻塞,提高了程序的并发能力。
* 结果说明:当客户端发起请求时,会先输出"Start",然后经过5秒的延时后输出"End"。
#### 4.2 协程和生成器
Tornado框架中广泛使用协程和生成器来简化异步编程过程。通过使用`async`和`await`关键字,开发者可以编写更加直观、易读的异步代码,而不用关心底层的回调机制。
```python
import tornado.ioloop
import tornado.web
import time
class MainHandler(tornado.web.RequestHandler):
async def get(self):
self.write("Start\n")
await self.sleep(5)
self.write("End\n")
async def sleep(self, seconds):
for _ in range(seconds):
await tornado.gen.sleep(1)
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
* 代码说明:上述代码演示了在Tornado框架中如何使用协程和生成器来进行异步编程,通过`async def`定义异步函数,使用`await`关键字进行异步操作。
* 结果说明:与之前的示例相同,当客户端发起请求时,会先输出"Start",然后经过5秒的延时后输出"End"。
通过理解和应用这些核心概念,开发者可以更好地利用Tornado框架的特性,实现高性能、高并发的Web应用程序。
# 5. Tornado框架的高级用法
Tornado框架不仅可以用于构建简单的web应用程序,还具备一些高级功能和用法。本章将介绍如何在Tornado框架中使用数据库和ORM、实现用户认证和权限控制、构建RESTful API以及使用Tornado的WebSocket和长连接。
#### 5.1 使用Tornado的数据库和ORM
在Tornado框架中使用数据库通常需要配合ORM(对象关系映射),常用的ORM包括SQLAlchemy和Peewee。通过ORM,我们可以使用Python对象来操作数据库,而不必直接编写SQL语句。以下是一个使用SQLAlchemy的简单示例:
```python
import tornado.ioloop
import tornado.web
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
engine = create_engine('sqlite:///mydatabase.db', echo=True)
Session = sessionmaker(bind=engine)
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
username = Column(String)
password = Column(String)
def __repr__(self):
return f"<User(username='{self.username}', password='{self.password}')>"
Base.metadata.create_all(engine)
class MainHandler(tornado.web.RequestHandler):
def get(self):
session = Session()
users = session.query(User).all()
for user in users:
self.write(f"Username: {user.username}, Password: {user.password}<br>")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
在上述示例中,我们使用SQLAlchemy定义了一个User模型,并利用Tornado框架创建了一个简单的web应用程序,该程序可以查询并展示数据库中的用户信息。
#### 5.2 实现用户认证和权限控制
在Tornado框架中实现用户认证和权限控制通常需要结合Tornado的认证模块来实现。例如,可以使用tornado.auth模块提供的`GoogleMixin`、`FacebookGraphMixin`等来实现第三方登录,也可以自定义`BaseHandler`来实现基于cookie的认证和权限控制。
#### 5.3 构建RESTful API
Tornado框架天生支持异步IO和非阻塞IO,因此非常适合构建RESTful API。通过Tornado的`RequestHandler`类,我们可以轻松地实现GET、POST、PUT、DELETE等HTTP方法的处理,从而构建高性能的RESTful API。
#### 5.4 使用Tornado的WebSocket和长连接
除了HTTP请求外,Tornado框架还支持WebSocket和长连接,可以轻松实现实时通讯和消息推送等功能。通过Tornado的`WebSocketHandler`类,可以方便地处理WebSocket连接,并实现双向通信。
在本章中,我们介绍了Tornado框架的一些高级用法,包括使用数据库和ORM、实现用户认证和权限控制、构建RESTful API以及使用WebSocket和长连接。这些功能使得Tornado成为一个强大且灵活的框枧,可以满足各种复杂应用程序的需求。
# 6. Tornado框架的部署和优化
在开发完Tornado应用程序之后,下一步是将其部署到生产环境中,并对其进行优化,以提高性能和可伸缩性。本章将介绍如何部署Tornado应用程序,并提供一些优化的技巧和策略。
### 6.1 部署Tornado应用程序
在将Tornado应用程序部署到生产环境之前,需要确保服务器上已经安装了Python和Tornado框架。一般来说,可以使用如下的步骤来部署Tornado应用程序:
1. 将应用程序文件上传到服务器上的指定目录。
2. 安装应用程序所需的依赖库,可以使用pip来安装。
```bash
$ pip install -r requirements.txt
```
3. 配置服务器的网络和安全设置,例如防火墙、端口转发等。
4. 配置Tornado应用程序的运行环境,例如端口号、日志文件路径等。
5. 启动Tornado应用程序,并监控其运行状态。
```bash
$ python app.py
```
### 6.2 使用Nginx和Supervisor进行生产环境部署
为了提高Tornado应用程序的性能和可靠性,可以使用Nginx作为反向代理服务器,并使用Supervisor来管理Tornado进程。以下是部署流程的简要步骤:
1. 安装Nginx和Supervisor。
2. 配置Nginx代理 Tornado应用程序的请求。
```nginx
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://127.0.0.1:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
```
3. 配置Supervisor来管理Tornado进程。
```ini
[program:tornado-app]
command=/path/to/python /path/to/app.py
autostart=true
autorestart=true
redirect_stderr=true
```
4. 启动Nginx和Supervisor服务,并监控其运行状态。
```bash
$ sudo service nginx start
$ sudo supervisorctl start tornado-app
```
### 6.3 提高Tornado应用程序的性能和可伸缩性
为了提高Tornado应用程序的性能和可伸缩性,可以采用以下一些优化策略:
- 使用多进程部署Tornado应用程序,从而充分利用多核CPU的性能。
- 使用缓存来减轻数据库的访问压力,例如使用Redis作为缓存服务器。
- 使用异步IO和非阻塞IO技术来提高应用程序的并发处理能力。
- 使用负载均衡来分担请求压力,例如使用Nginx或HAProxy。
- 对数据库进行性能优化,例如建立索引、使用连接池等。
- 使用合适的数据结构和算法来提高数据处理的效率。
### 6.4 监控和调试Tornado应用程序
在生产环境中,为了及时发现和解决问题,需要对Tornado应用程序进行监控和调试。以下是一些常用的监控和调试工具:
- 使用日志系统来记录应用程序的运行状态和错误信息。
- 使用性能分析工具来分析应用程序的性能瓶颈,例如cProfile、line_profiler等。
- 使用监控工具来监控应用程序的运行指标,例如Grafana、Prometheus等。
- 使用断点调试器来定位问题,例如pdb、PyCharm等。
- 使用错误追踪工具来收集和分析应用程序的错误信息,例如Sentry、Airbrake等。
通过以上的部署和优化措施,可以使Tornado应用程序具备更好的性能和可伸缩性,并保证应用程序在生产环境中的稳定运行。
希望本章的内容能够帮助你成功部署和优化Tornado应用程序!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Lucky带你玩转高并发Tornado框架实战与优化》是一本致力于帮助读者深入理解和灵活运用Tornado框架的实用指南。从快速入门指南到核心理念的解读,再到事件循环、协程与生成器的实践应用,涵盖了Tornado框架中各个重要的知识点。通过专栏,读者将深入了解Tornado框架下的HTTP服务器搭建、模板引擎运用、表单验证、静态文件处理、WebSocket支持、消息队列、缓存优化、数据库操作和日志记录等内容,并且了解如何保障应用程序的安全性。专栏具有丰富的实例和案例,旨在帮助读者快速上手并掌握Tornado框架的实战技巧与性能优化方法,从而使他们能够更好地应对高并发环境下的挑战。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
网格搜索:多目标优化的实战技巧

# 1. 网格搜索技术概述
## 1.1 网格搜索的基本概念
网格搜索(Grid Search)是一种系统化、高效地遍历多维空间参数的优化方法。它通过在每个参数维度上定义一系列候选值,并
随机搜索与贝叶斯优化的结合

# 1. 随机搜索与贝叶斯优化简介
在当今快速发展的IT领域,优化算法扮演着越来越重要的角色。本章将概述随机搜索与贝叶斯优化的基本概念、发展历程以及它们在现代科技中的应用价值。从随机搜索的简单概念,到贝叶斯优化在概率模型和代理模型基础上的预期改善策略,我们将揭开优
机器学习调试实战:分析并优化模型性能的偏差与方差
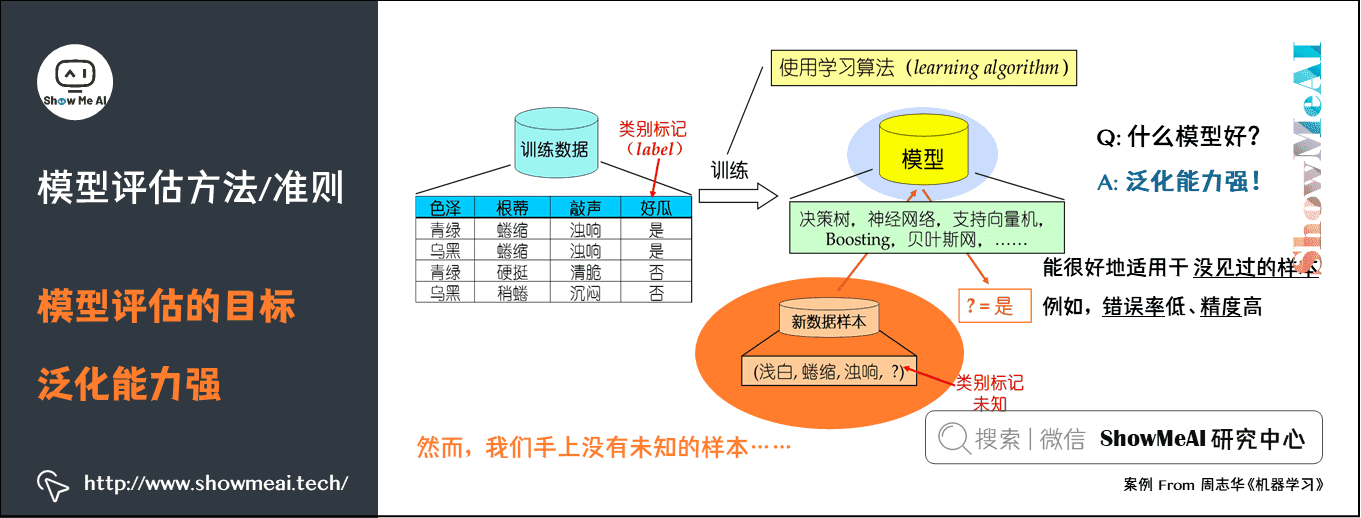
# 1. 机器学习调试的概念和重要性
## 什么是机器学习调试
机器学习调试是指在开发机器学习模型的过程中,通过识别和解决模型性能不佳的问题来改善模型预测准确性的过程。它是模型训练不可或缺的环节,涵盖了从数据预处理到最终模型部署的每一个步骤。
## 调试的重要性
有效的调试能够显著提高模型的泛化能力,即在未见过的数据上也能作出准确预测的能力。没有经过适当调试的模型可能无法应对实
VR_AR技术学习与应用:学习曲线在虚拟现实领域的探索

# 1. 虚拟现实技术概览
虚拟现实(VR)技术,又称为虚拟环境(VE)技术,是一种使用计算机模拟生成的能与用户交互的三维虚拟环境。这种环境可以通过用户的视觉、听觉、触觉甚至嗅觉感受到,给人一种身临其境的感觉。VR技术是通过一系列的硬件和软件来实现的,包括头戴显示器、数据手套、跟踪系统、三维声音系统、高性能计算机等。
VR技术的应用
测试集在兼容性测试中的应用:确保软件在各种环境下的表现

# 1. 兼容性测试的概念和重要性
## 1.1 兼容性测试概述
兼容性测试确保软件产品能够在不同环境、平台和设备中正常运行。这一过程涉及验证软件在不同操作系统、浏览器、硬件配置和移动设备上的表现。
## 1.2 兼容性测试的重要性
在多样的IT环境中,兼容性测试是提高用户体验的关键。它减少了因环境差异导致的问题,有助于维护软件的稳定性和可靠性,降低后
过拟合的统计检验:如何量化模型的泛化能力

# 1. 过拟合的概念与影响
## 1.1 过拟合的定义
过拟合(overfitting)是机器学习领域中一个关键问题,当模型对训练数据的拟合程度过高,以至于捕捉到了数据中的噪声和异常值,导致模型泛化能力下降,无法很好地预测新的、未见过的数据。这种情况下的模型性能在训练数据上表现优异,但在新的数据集上却表现不佳。
## 1.2 过拟合产生的原因
过拟合的产生通常与模
特征贡献的Shapley分析:深入理解模型复杂度的实用方法
# 1. 特征贡献的Shapley分析概述
在数据科学领域,模型解释性(Model Explainability)是确保人工智能(AI)应用负责任和可信赖的关键因素。机器学习模型,尤其是复杂的非线性模型如深度学习,往往被认为是“黑箱”,因为它们的内部工作机制并不透明。然而,随着机器学习越来越多地应用于关键决策领域,如金融风控、医疗诊断和交通管理,理解模型的决策过程变得至关重要
探索性数据分析:训练集构建中的可视化工具和技巧
# 1. 探索性数据分析简介
在数据分析的世界中,探索性数据分析(Exploratory Dat
激活函数在深度学习中的应用:欠拟合克星
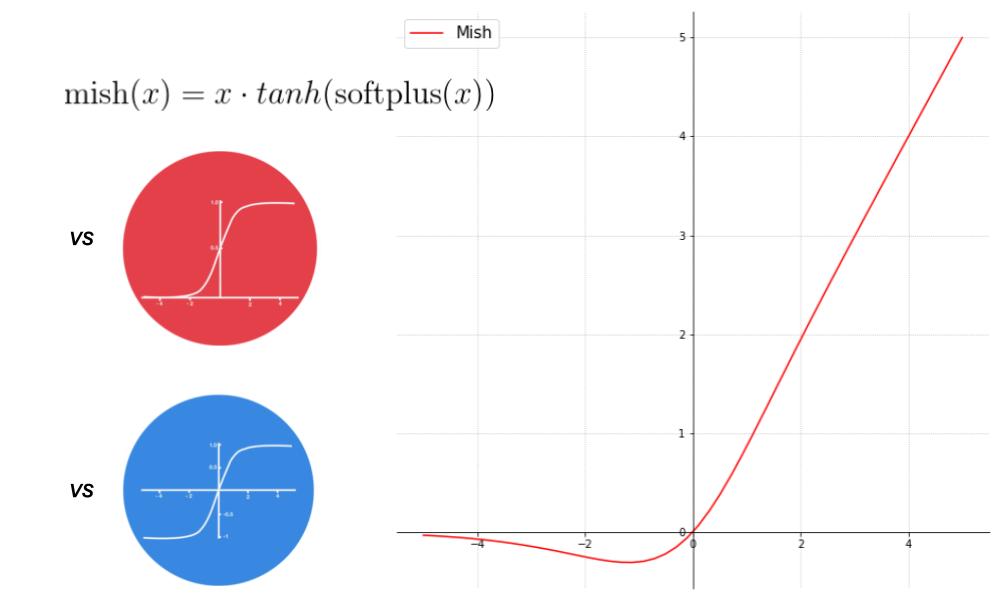
# 1. 深度学习中的激活函数基础
在深度学习领域,激活函数扮演着至关重要的角色。激活函数的主要作用是在神经网络中引入非线性,从而使网络有能力捕捉复杂的数据模式。它是连接层与层之间的关键,能够影响模型的性能和复杂度。深度学习模型的计算过程往往是一个线性操作,如果没有激活函数,无论网络有多少层,其表达能力都受限于一个线性模型,这无疑极大地限制了模型在现实问题中的应用潜力。
激活函数的基本
【统计学意义的验证集】:理解验证集在机器学习模型选择与评估中的重要性
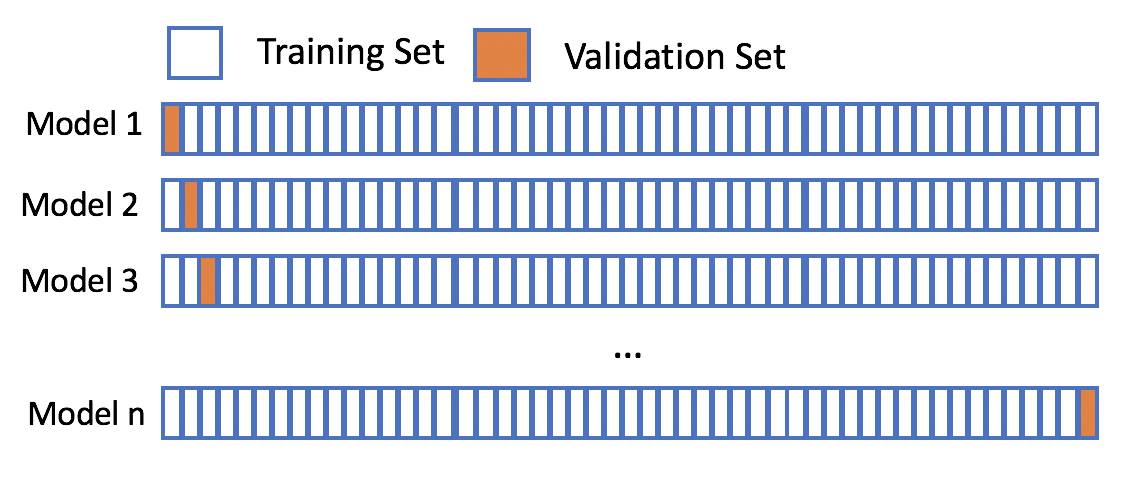
# 1. 验证集的概念与作用
在机器学习和统计学中,验证集是用来评估模型性能和选择超参数的重要工具。**验证集**是在训练集之外的一个独立数据集,通过对这个数据集的预测结果来估计模型在未见数据上的表现,从而避免了过拟合问题。验证集的作用不仅仅在于选择最佳模型,还能帮助我们理解模型在实际应用中的泛化能力,是开发高质量预测模型不可或缺的一部分。
```markdown
## 1.1 验证集与训练集、测试集的区
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )