【案例研究】:揭秘成功MySQL数据导入的背后故事与经验
发布时间: 2024-12-06 15:49:21 阅读量: 11 订阅数: 14 

MATLAB实现SSA-CNN-BiLSTM麻雀算法优化卷积双向长短期记忆神经网络数据分类预测(含完整的程序,GUI设计和代码详解)

# 1. MySQL数据导入基础知识概述
在进行MySQL数据导入之前,了解其基础知识是至关重要的。数据导入是数据库管理和维护的基本任务之一,涉及将数据从不同源(如CSV文件、Excel表格或其他数据库)迁移到MySQL数据库中。在本章,我们将介绍数据导入的基本概念,包括其重要性、常见的应用场景以及数据导入的基本流程。此外,本章还将阐述如何在导入过程中确保数据的准确性和完整性,为后续章节深入探讨做好铺垫。
```mermaid
graph LR
A[开始数据导入] --> B[理解数据导入概念]
B --> C[识别应用场景]
C --> D[掌握基本导入流程]
D --> E[确保数据准确性与完整性]
E --> F[结束数据导入]
```
理解数据导入概念:
```markdown
数据导入是数据库操作的一个基本环节,它允许你将数据从一个系统或格式转移到另一个系统中,通常是将数据加载到MySQL数据库中。它的重要性在于能够实现数据迁移、数据备份、数据同步和数据整合等多种数据管理任务。
识别应用场景:
- 数据迁移:从旧系统迁移到新系统。
- 数据备份:将重要数据从主数据库复制到备份数据库。
- 数据同步:维持多个数据库间数据的一致性。
- 数据整合:合并多个数据源,为数据分析做准备。
```
掌握基本导入流程:
```markdown
数据导入的基本流程包括准备数据源、执行导入操作和验证数据导入结果三个主要步骤。在准备数据源时,需要将数据整理成MySQL可以接受的格式,如CSV或SQL语句。执行导入操作时,可以利用MySQL提供的工具,例如`mysql`命令行工具、`LOAD DATA INFILE`语句或第三方数据导入工具。数据导入完成后,验证数据是否准确导入至关重要,这通常涉及对特定数据的查询和校验。
```
通过本章的学习,读者将掌握数据导入的基础知识,为后续章节的深入讨论打下坚实基础。在接下来的章节中,我们将具体探讨如何在数据导入前做好充分的准备工作,以确保数据导入的安全性和效率。
# 2. 数据导入前的准备工作
在开始数据导入之前,确保充分的准备工作是至关重要的。这不仅涉及到对数据库环境和数据源的理解,还涵盖了对安全性与备份策略的规划。
## 2.1 数据库环境搭建与配置
### 2.1.1 选择合适的MySQL版本
在选择MySQL版本时,需要考虑多个因素,比如性能需求、兼容性问题以及未来的技术支持等。
MySQL版本的选择通常取决于应用需求与服务器的性能。例如:
- MySQL 5.6:适合对稳定性有高要求的环境。
- MySQL 5.7:引入了许多性能改进和新特性,如JSON支持。
- MySQL 8.0:增加了如窗口函数、角色管理等强大特性。
### 2.1.2 数据库服务器的安装与配置
服务器配置的性能直接关系到数据导入的效率。以下是一些关键的配置项:
- 内存大小:确保有足够的内存来处理数据导入任务,减少I/O操作。
- 硬盘类型:固态硬盘(SSD)比机械硬盘(HDD)有更好的读写速度。
- MySQL配置文件(my.cnf或my.ini):需要合理调整缓冲区大小,如innodb_buffer_pool_size, key_buffer_size等。
```ini
[mysqld]
innodb_buffer_pool_size = 2G
key_buffer_size = 512M
```
在配置文件中,`innodb_buffer_pool_size`是InnoDB存储引擎中最重要的配置项,它定义了缓冲池大小,影响数据和索引的处理效率。
## 2.2 数据源的整理与分析
### 2.2.1 识别数据源格式和类型
数据源可能来自多种格式,如CSV、JSON、XML等。在数据导入前,需要识别数据源的格式。
- CSV:逗号分隔的值,便于数据交换,但没有严格的数据类型。
- JSON:一种轻量级的数据交换格式,常用于Web服务。
- XML:可扩展标记语言,包含丰富的元数据。
### 2.2.2 数据质量的检查与清洗
数据质量的检查是确保数据导入后准确性的关键一步。检查工具如`awk`, `sed`或`jq`在处理数据格式化和验证方面非常有用。
清洗数据的典型步骤包括:
- 删除重复记录。
- 格式化日期和数字字段。
- 检查和修正不一致的数据。
```bash
# 示例:使用awk检查CSV文件中的重复行
awk -F, '!seen[$0]++' file.csv
```
## 2.3 安全性考虑与备份策略
### 2.3.1 数据导入过程中的安全风险
数据导入过程可能面临多种安全风险,包括:
- 数据泄露:敏感数据在传输过程中可能被截获。
- 非授权访问:未授权的用户可能访问数据导入过程。
- 数据完整性破坏:恶意用户可能篡改数据。
### 2.3.2 设计有效的数据备份方案
数据备份是保护数据不受意外损失的重要手段。一个有效的备份方案应该包括:
- 完整备份:定期执行全库备份。
- 增量备份:只备份自上次备份以来发生变化的数据。
- 备份验证:定期验证备份数据的可用性。
备份策略应该根据数据的重要性、变化频率以及可用的资源来定制。
通过以上准备工作,我们可以确保数据导入过程的顺利进行,同时降低风险和潜在的错误发生。在下一章节中,我们将深入探讨数据导入工具和技术的选择。
# 3. ```
# 第三章:数据导入工具和技术选择
## 3.1 常用数据导入工具介绍
### 3.1.1 MySQL官方工具使用方法
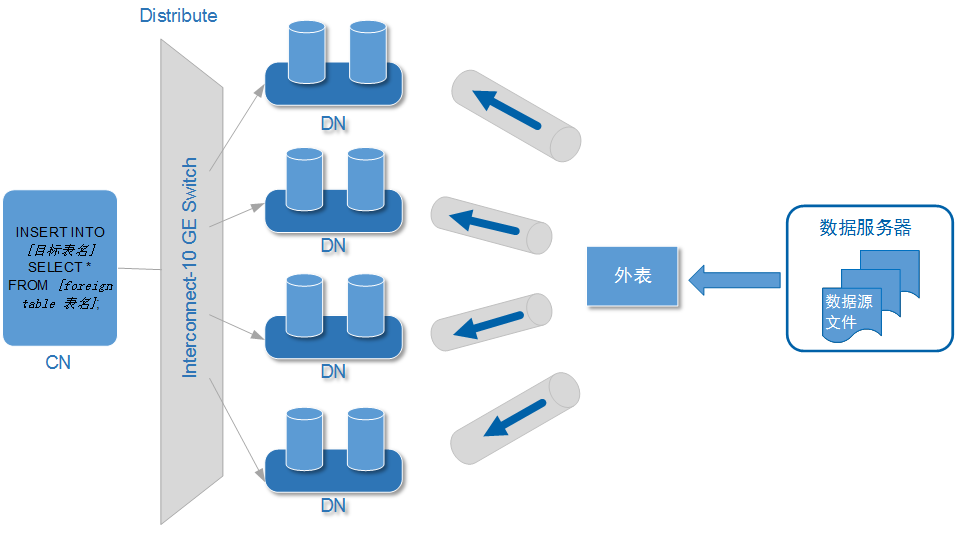
MySQL提供了一系列的官方工具,如`mysqlimport`和`LOAD DATA INFILE`命令,这些都是进行数据导入的高效工具。`mysqlimport`是一个命令行工具,用于批量导入数据到MySQL服务器上的指定数据库中,而`LOAD DATA INFILE`是MySQL服务器提供的一个SQL语句,可以快速导入大量数据。
以`LOAD DATA INFILE`为例,该语句的基本语法如下:
```sql
LOAD DATA INFILE 'file_name.txt'
INTO TABLE table_name
[FIELDS TERMINATED BY 'delimiter']
[ENCLOSED BY 'enclosure']
[LINES TERMINATED BY 'newline']
[IGNORE number LINES]
(column1, column2, ...);
```
`file_name.txt` 是待导入数据的文件,`table_name` 是目标表名。 `FIELDS TERMINATED BY` 用于指定字段分隔符,`ENCLOSED BY` 用于指定字段的包围字符,`LINES TERMINATED BY` 用于指定行的结束符,`IGNORE number LINES` 用于跳过文件开头的若干行(通常用作跳过标题行)。
在使用时,确保服务器配置允许`LOAD DATA INFILE`操作,或在命令中使用`LOCAL`关键字来指定本地文件路径。
### 3.1.2 第三方数据导入工具对比
除了MySQL的官方工具外,市场上还有许多第三方工具,如`MyLoader`、`Navicat`和`SQLyog`等。这些工具通常具有图形用户界面,易于使用,并且支持更多的功能,例如并发导入、进度监控、错误报告和格式转换等。
以`MyLoader`为例,它是一款支持高并发导入的高效工具,相比于原生的`LOAD DATA INFILE`,它在处理大文件和高并发导入时表现更为出色。同时,`MyLoader`还支持断点续传和自定义的错误处理。
第三方工具的另一个显著优势是它们通常提供跨平台支持,例如`Navicat`就可以在Windows、Mac和Linux上运行。它们还提供了友好的用户界面,降低了技术门槛,使得非技术人员也能高效完成数据导入工作。
## 3.2 数据导入技术选型
### 3.2.1 比较不同导入技术的优势
选择数据导入技术时,需要考虑多个方面,比如数据量大小、
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MySQL 数据导入的方方面面,提供了全面的指南和技巧,帮助用户高效、安全地导入数据。专栏涵盖了从新手必备的基础操作到高级自动化脚本编写,以及性能优化、数据一致性保障、工具对比、错误诊断、数据清洗、索引优化、权限管理、跨平台迁移、大型数据集导入等各个方面。此外,还提供了数据格式转换、并行导入、数据校验、分批导入、数据恢复等实用技巧。通过阅读本专栏,用户可以掌握 MySQL 数据导入的最佳实践,提高数据导入效率,确保数据完整性和安全性。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【UHD 620核显驱动故障排除全攻略】:Windows 7用户的终极指南
参考资源链接:[Win7 64位下UHD 620/630核显驱动发布(8代处理器适用)](https://wenku.csdn.net/doc/273in28khy?spm=1055.2635.3001.10343)
# 1. UHD 620核显驱动故障概述
## 1.1 故障的普遍影响
英特尔UHD 620作为广泛集成在多代处理器中的核显单元,其
【Cadence放大器性能指标实战】:频率响应评估与优化全攻略
参考资源链接:[Candence分析:放大器极零点与频率响应解析](https://wenku.csdn.net/doc/649e6f207ad1c22e797c681e?spm=1055.2635.3001.10343)
# 1. Cadence放大器性能指标概述
## 1.1 放大器性能指标的定义
放大器作为电子电路中的核
网络安全必备:H3C交换机MAC绑定与黑名单的深度剖析及实战应用

参考资源链接:[H3C交换机:实战教程-黑名单、MAC绑定与ACL综合配置](https://wenku.csdn.net/doc/64697c9e543f844488bebdc7?spm=1055.2635.3001.10343)
# 1. H3C交换机MAC绑定与黑名单概念解析
## 1.1 交换机安全的背景
在当今网络安全形势日益复杂的背景下,企业网络面临着各种安全威胁。通过诸
【网络流量监控与比较】:nlbwmon在OpenWrt下的使用与优势解析
参考资源链接:[Openwrt带宽统计:nlbwmon的安装与优化](https://wenku.csdn.net/doc/3egvhwv2wq?spm=1055.2635.3001.10343)
# 1. 网络流量监控的概念与重要性
网络流量监控是网络管理和运维中不可或缺的组成部分,它
内存管理艺术:C语言中的乒乓缓存策略
参考资源链接:[C代码实现内存乒乓缓存与消息分发,提升内存响应](https://wenku.csdn.net/doc/64817668d12cbe7ec369e795?spm=1055.2635.3001.10343)
# 1. 内存管理的基础知识
内存管理是计算机系统中的一项核心功能,它负责合理地分配和回收内存空间,确保系统运行的稳定性和资源的高效利用。理解内存管理的基础知识是深入研究高级内存管理技术的前提。本
Fluent UDF中文教程:一步到位,掌握流体仿真编程精髓(0基础到专业精通)

参考资源链接:[Fluent UDF中文教程:自定义函数详解与实战应用](https://wenku.csdn.net/doc/1z9ke82ga9?spm=1055.2635.3001.10343)
# 1. Fluent UDF编程入门
## 1.1 开启Fluent UDF编程之旅
在这一章节中,我们将带您进入Fluent UDF(User-Defined Functions)编程的世界。Fluent是一
【HBM ESD测试案例大公开】:遵循JESD22-A114-B标准的最佳实践分析

参考资源链接:[JESD22-A114-B(EDS-HBM).pdf](https://wenku.csdn.net/doc/6401abadcce7214c316e91b7?spm=1055.2635.3001.10343)
# 1. ESD测试与HBM概念解析
## 1.1 ESD的定义及其对电子设备的重要性
静电放电(ESD)是一种常见的物理现象,其发生时会引起瞬间电流,可能
【并行计算秘技】:打造现代计算机体系结构的五大基石
参考资源链接:[王志英版计算机体系结构课后答案详解:层次结构、虚拟机与透明性](https://wenku.csdn.net/doc/646747c6543f844488b70360?spm=1055.2635.3001.10343)
# 1. 并行计算简介与基本原理
并行计算是当代信息技术的一个核心领域,它允许同时执行多个计算任务,极大地
VASP问题解决宝典:常见模拟案例分析与技巧

参考资源链接:[vasp中文使用指南:清华大学苏长荣老师编撰](https://wenku.csdn.net/doc/1xa94iset7?spm=1055.2635.3001.10343)
# 1. VASP基础知识概述
## 1.1 VASP简介
VASP(Vienna Ab initio
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )