Python与自然语言生成:叙事艺术的编程实现
发布时间: 2024-12-07 06:56:27 阅读量: 9 订阅数: 16 

scaelextric_implementatio:叙事工具的执行

# 1. Python在自然语言生成中的角色
## 1.1 Python语言特性与NLP的契合度
Python作为一种高级编程语言,在自然语言处理(NLP)领域拥有显著的优势。它简洁易读的语法降低了入门门槛,同时强大的库支持和丰富的生态系统为NLP应用提供了坚实基础。Python语言的动态类型系统和解释执行机制使得快速原型开发成为可能,这对于NLP中的算法迭代尤为重要。
## 1.2 自然语言生成的技术基础
在NLP领域,自然语言生成(NLG)是一门涉及语言、计算机科学、人工智能的交叉技术。NLG的目标是从非语言源数据(如数据库、知识图谱等)自动产生有意义且自然流畅的语言表达。Python语言因其强大的数据处理能力和众多的第三方库支持,在NLG领域的应用变得日益广泛。
## 1.3 Python在NLG中的应用案例
目前,Python已经广泛应用在生成新闻报道、自动写作、对话系统等自然语言生成场景中。比如,利用Python开发的自动生成天气预报的程序,不仅能够理解天气数据,还能以自然、流畅的语言输出天气情况,大大提高了信息发布的效率和可读性。通过学习这些案例,我们能够更深入理解Python在NLG中的具体应用。
# 2. 理解自然语言处理的基础
自然语言处理(Natural Language Processing,NLP)是计算机科学、人工智能和语言学领域的一个交叉学科,它致力于让计算机能够理解和处理人类语言。为了深入理解自然语言处理,本章节将探讨其基础概念、理论框架以及在Python中的实现方法。
## 2.1 自然语言处理的基本概念
### 2.1.1 语言学基础知识
语言学是研究人类语言的科学,自然语言处理的基础之一就是语言学的基础知识。这些基础知识包括了音韵学、形态学、句法学、语义学和语用学等多个分支。
- **音韵学(Phonetics)**:研究语音的产生、属性、传输和接受。
- **形态学(Morphology)**:研究词的内部结构,包括词根、前缀、后缀等。
- **句法学(Syntax)**:研究句子的结构,包括词组、短语、从句和句子的关系与功能。
- **语义学(Semantics)**:研究语言的意义,包括单词、短语和句子的意义。
- **语用学(Pragmatics)**:研究语言的使用环境和语境,以及说话者的意图。
在自然语言处理中,这些语言学知识被用来构建算法和模型,使得机器能够识别和解析自然语言的结构和含义。
### 2.1.2 自然语言处理的应用场景
自然语言处理的应用场景十分广泛,包括但不限于以下领域:
- **搜索与信息检索**:通过关键词匹配来查找信息。
- **机器翻译**:将一种语言翻译成另一种语言。
- **语音识别**:将人类的语音转换成可处理的文本。
- **情感分析**:确定文本中表达的情绪倾向。
- **问答系统**:回答用户提出的自然语言问题。
- **聊天机器人**:模拟人类对话,提供信息或服务。
## 2.2 自然语言处理的理论框架
### 2.2.1 文本预处理步骤
在进行任何自然语言处理任务之前,通常需要对文本进行预处理。文本预处理是自然语言处理中至关重要的一步,它包括以下几个步骤:
1. **分词(Tokenization)**:将句子分解成单词、短语或其他有意义的单元。
2. **词性标注(Part-of-Speech Tagging)**:为每个单词赋予一个词性标签,如名词、动词等。
3. **词干提取(Stemming)**:将单词还原为其词根形式。
4. **词形还原(Lemmatization)**:将单词还原为其词典形式。
5. **去除停用词(Stop Word Removal)**:去除文本中常见的无意义词汇,如“的”、“是”、“和”等。
6. **向量化(Vectorization)**:将文本转换成数值向量,以便计算机处理。
### 2.2.2 语义分析与理解技术
语义分析是指理解文本中单词、短语和句子的含义,包括以下几个方面:
- **命名实体识别(Named Entity Recognition,NER)**:识别文本中的专有名词,如人名、地名等。
- **依存句法分析(Dependency Parsing)**:识别句子中词与词之间的依存关系。
- **语义角色标注(Semantic Role Labeling,SRL)**:确定句子中谓语的动作和它的参与者(如施事、受事)。
- **情感分析**:分析文本表达的情感倾向,如积极、消极或中立。
### 2.2.3 语言模型与生成模型的区别
自然语言处理中常见的模型可以分为语言模型和生成模型两类:
- **语言模型(Language Models)**:用于评估或预测句子出现的概率,例如n-gram模型和神经网络语言模型。
- **生成模型(Generation Models)**:用于生成新的文本,如基于模板的生成方法和基于机器学习的文本生成。
## 2.3 Python中的自然语言处理库
Python拥有强大的自然语言处理库,最著名的两个是NLTK和spaCy。
### 2.3.1 NLTK和spaCy库概述
- **NLTK(Natural Language Toolkit)**:是一个开源的自然语言处理库,提供了丰富的文本处理功能,适合教学和研究。
- **spaCy**:是一个更现代、性能更高的库,特别适合于工业级应用。它注重于高效的数据处理和模型训练。
### 2.3.2 其他流行的NLP工具和库
除了NLTK和spaCy外,还有许多其他流行的自然语言处理工具和库,比如Gensim、TextBlob和AllenNLP等。这些工具提供了额外的功能,如主题建模、情感分析、深度学习模型训练等。
通过上述内容,本章节为读者打下了自然语言处理的基础知识,为接下来深入了解Python实现自然语言生成的技术实践奠定了坚实的基础。
# 3. Python实现自然语言生成的技术实践
自然语言生成(Natural Language Generation,NLG)是自然语言处理的一个分支,它涉及到利用算法和技术生成自然语言文本或语音的过程。Python作为一门强大的编程语言,提供了一系列工具和库,使开发者能够构建和实现自然语言生成应用。本章将探讨文本生成的基本方法、使用机器学习方法生成文本以及实际代码演示。
## 3.1 文本生成的基本方法
### 3.1.1 基于模板的文本生成
基于模板的文本生成是最简单和直接的文本生成方法之一。它依赖于预定义的句子结构模板,并将具体的数据填充进这些模板中,以此来生成语义连贯的文本。这种方法的优点是实施起来相对容易,可以快速生成结构化和格式化的文本,缺点在于灵活性较差,对于多样化的文本生成效果有限。
```python
# 示例代码:基于模板的文本生成
def template_based_text_generation(entity_data, template):
"""
基于模板的文本生成函数
:param entity_data: 包含实体数据的字典,如{'name': 'Alice', 'occupation': 'engineer'}
:param template: 文本模板,如 "My name is {name} and I'm an {occupation}."
:return: 根据模板和实体数据生成的文本字符串
"""
# 将实体数据填充到模板中
generated_text = template.format(**entity_data)
return generated_text
entity_data = {'name': 'Alice', 'occupation': 'engineer'}
template = "My name is {name} and I'm an {occupation}."
print(template_based_text_generation(entity_data, template))
```
### 3.1.2 基于规则的文本生成
基于规则的方法依赖于一套详细的规则集合,这些规则指导如何生成文本。通常,规则定义了词汇的选择、短语的构造以及句子的组合。尽管基于规则的方法能够提供更灵活的文本生成方式,但其构建和维护难度较高,尤其是对于复杂的文本生成需求。
```python
# 示例代码:基于规则的文本生成
def rule_based_text_generation(parts_of_speech_rules):
"""
基于规则的文本生成函数
:param parts_of_speech_rules: 定义了不同词性规则的字典
:return: 生成的文本字符串
"""
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 在自然语言处理 (NLP) 领域的广泛应用。从社交媒体情感分析到主题建模、自然语言生成、机器翻译、知识图谱构建、语音识别和文本聚类,该专栏提供了深入的教程和实践指南,帮助读者掌握 NLP 的关键技术。专栏还涵盖了大规模文本处理技术,包括文本清洗和预处理,以确保数据质量和效率。通过这些文章,读者将了解 Python 在 NLP 中的强大功能,并获得在现实世界项目中应用这些技术的实际技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
精通VW 80808-2 OCR错误诊断:快速解决问题的7种方法

参考资源链接:[Volkswagen标准VW 80808-2(OCR)2017:电子元件与装配技术详细指南](https://wenku.csdn.net/doc/3y3gykjr27?spm=1055.2635.3001.10343)
# 1. VW 80808-2 OCR错误诊断概述
在数字化时代,光学字符识别(
LIFBASE性能调优秘笈:9个步骤提升系统响应速度
参考资源链接:[LIFBASE帮助文件](https://wenku.csdn.net/doc/646da1b5543f844488d79f20?spm=1055.2635.3001.10343)
# 1. LIFBASE系统性能调优概述
在IT领域,随着技术的发展和业务需求的增长,系统性能调优逐渐成为保障业务连续性和用户满意度的关键环节。LIFBASE系统作为
【XILINX 7代XADC进阶手册】:深度剖析数据采集系统设计的7个关键点

参考资源链接:[Xilinx 7系列FPGA XADC模块详解与应用](https://wenku.csdn.net/doc/6412
OV426功耗管理指南:打造绿色计算的终极武器
参考资源链接:[OV426传感器详解:医疗影像前端解决方案](https://wenku.csdn.net/doc/61pvjv8si4?spm=1055.2635.3001.10343)
# 1. OV426功耗管理概述
在当今数字化时代,信息技术设备的普及导致了能源消耗的剧增。随着对节能减排的全球性重视,如何有效地管理电子设备的功耗成为了IT行业关注的焦点之一。特别是对于高性能计算设备和嵌入式系统,合理的功耗管理不仅能够降低能源消耗,还能延长设备的使用寿命,提高系统的稳定性和响应速度。OV426作为一款先进的处理器,其功耗管理能力直接影响到整个系统的性能与效率。接下来的章节中,我们将深入
深入探讨:银行储蓄系统中的交易并发控制
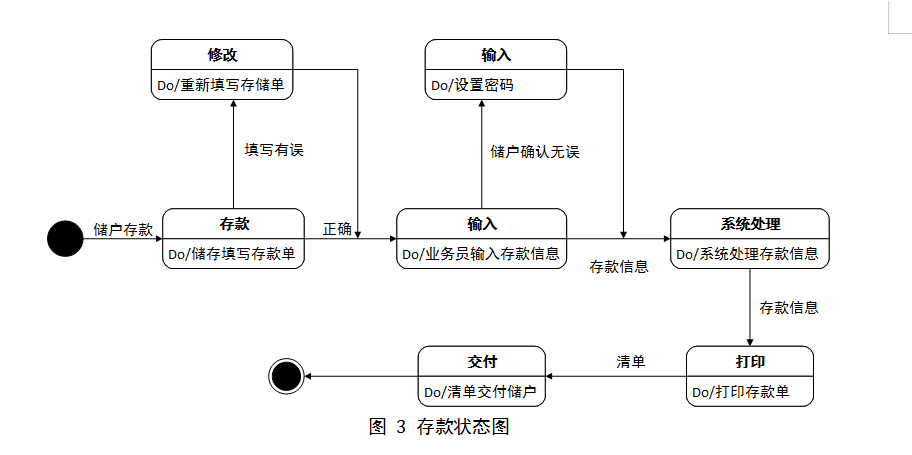
参考资源链接:[银行储蓄系统设计与实现:高效精准的银行业务管理](https://wenku.csdn.net/doc/75uujt5r53?spm=1055.2635.3001.10343)
# 1. 银行储蓄系统的并发问题概述
## 1.1 并发访问的必要性
在现代银行业务中,储蓄系统的并发处理是提高交易效率和用户体验的关键。随着在线交易量的增加,系统需要同时处理来自不同客户和分支机构的请求。并发访问确保了系统能够快速响应,但同时也带来了数
【HyperMesh材料属性至边界条件】:打造精准仿真模型的全路径指南

参考资源链接:[Hypermesh基础操作指南:重力与外力加载](https://wenku.csdn.net/doc/mm2ex8rjsv?spm=105
【热管理高手进阶】:Android平台下高通与MTK热功耗深入分析及优化
参考资源链接:[Android高通与MTK平台热管理详解:定制Thermal与架构解析](https://wenku.csdn.net/doc/6412b72dbe7fbd1778d495e3?spm=1055.2635.3001.10343)
# 1. Android热管理基础与挑战
在当今的移动设备领域,Andr
【DS-K1T673误识率克星】:揭秘误差分析及改善策略

参考资源链接:[海康威视DS-K1T673系列人脸识别终端用户指南](https://wenku.csdn.net/doc/5swruw1zpd?spm=1055.2635.3001.10343)
# 1. 误差分析与改善策略的重要性
## 1.1 误差在IT领域的普遍性
在IT行业,数据和系统准确性至关重要。误差,无论是人为的还是技术上的,都可能导致重大的问题,如系统故障、数据失真和决策
【PADS Layout专家速成】:7步掌握覆铜技术,优化电路板设计
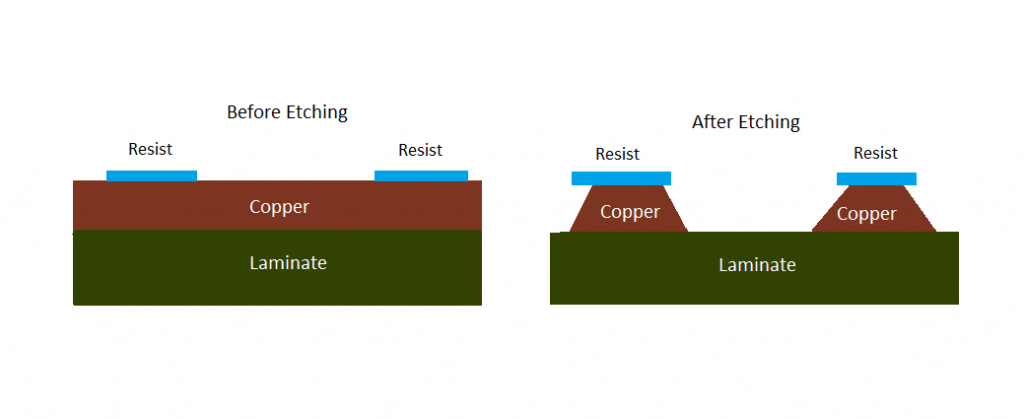
参考资源链接:[PADS LAYOUT 覆铜操作详解:从边框到填充](https://wenku.csdn.net/doc/69kdntug90?spm=1055.2635.3001.10343)
# 1. 覆铜技术概述
在现代电子设计制造中,覆铜技术是构建电路板核心的一环,它不仅涉及基础的电气连接,还包括了信号完整性、热管理以及结构稳定性等多方面考量
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )