【PyTorch中的自注意力机制】:BERT和GPT模型文本生成高级应用
发布时间: 2024-12-11 16:44:06 阅读量: 8 订阅数: 11 

gpt-2-Pytorch:具有OpenAI的简单文本生成器gpt-2 Pytorch实现
# 1. 自注意力机制的基本概念和原理
## 1.1 自注意力机制的定义
自注意力机制(Self-Attention Mechanism),也称为内部注意力机制,是深度学习中的一种核心计算框架。它允许输入序列中的每个元素直接与其他所有元素相互作用,以此来计算表示,从而在处理序列数据时捕捉长距离依赖关系。
## 1.2 自注意力的工作原理
自注意力通过计算query(查询)、key(键)和value(值)三个向量来实现,这三个向量通常由同一输入的不同线性变换得到。通过query和key之间的点积操作得到注意力权重,然后用这个权重对value向量加权求和,生成输出。这种方式可以并行处理,提升了模型处理序列数据的效率。
## 1.3 自注意力与循环神经网络(RNN)的区别
与传统的循环神经网络相比,自注意力机制的优势在于它不需要按顺序处理数据,能够同时考虑输入序列的所有元素。这不仅加快了训练速度,还增强了模型捕捉序列中远距离依赖的能力。因此,在诸如自然语言处理等序列建模任务中,自注意力机制正变得越来越流行。
# 2. BERT模型中的自注意力应用
在第一章中,我们对自注意力机制的理论基础和核心概念进行了梳理,为接下来深入了解其在BERT模型中的应用打下了坚实的基础。本章将重点介绍BERT模型的结构和特点,并深入探讨自注意力机制在其中的具体实现方式,以及BERT如何通过自注意力机制实现文本生成等应用。
### 2.1 BERT模型的结构和特点
#### 2.1.1 BERT模型的基本组成
BERT(Bidirectional Encoder Representations from Transformers)是由Google在2018年提出的预训练模型,它在NLP领域引发了革命性的变化。BERT模型利用Transformer的编码器结构,通过Masked Language Model (MLM) 和 Next Sentence Prediction (NSP) 任务来预训练模型,从而学习到丰富的语言表征。
BERT模型的核心是一系列堆叠的Transformer编码器层,每一个编码器层都包含两个子层:一个多头自注意力机制层(Multi-Head Self-Attention Layer),和一个前馈神经网络层(Feed-Forward Neural Network Layer)。另外,编码器层之间还加入了残差连接(Residual Connections)和层归一化(Layer Normalization)。
```python
import torch
import torch.nn as nn
class BertLayer(nn.Module):
def __init__(self, hidden_size, attention_heads, dropout_prob):
super(BertLayer, self).__init__()
self.self_attention = nn.MultiheadAttention(
embed_dim=hidden_size,
num_heads=attention_heads,
dropout=dropout_prob,
batch_first=True
)
self.norm1 = nn.LayerNorm(hidden_size)
self.ffn = nn.Sequential(
nn.Linear(hidden_size, 4 * hidden_size),
nn.ReLU(),
nn.Linear(4 * hidden_size, hidden_size)
)
self.norm2 = nn.LayerNorm(hidden_size)
self.dropout = nn.Dropout(dropout_prob)
def forward(self, hidden_states):
# Apply self-attention
attention_output = self.self_attention(hidden_states, hidden_states, hidden_states)[0]
attention_output = self.dropout(attention_output)
# Add layer norm and residual connection
out1 = self.norm1(hidden_states + attention_output)
# Apply feed-forward network
ffn_output = self.ffn(out1)
ffn_output = self.dropout(ffn_output)
# Add layer norm and residual connection
out2 = self.norm2(out1 + ffn_output)
return out2
```
上述代码展示了一个BERT层(编码器层)的基本实现,通过多头自注意力机制处理输入的hidden_states,然后通过前馈网络并结合层归一化和残差连接,将输出传递到下一个编码器层。
#### 2.1.2 BERT模型的预训练和微调
BERT模型的预训练过程是利用大规模语料库,通过MLM和NSP任务来学习语言的双向上下文表示。MLM任务通过随机遮蔽一部分输入词,让模型预测这些遮蔽词,这样模型必须学习理解完整的句子上下文才能做出正确的预测。NSP任务则是训练模型判断两个句子是否在原始文本中是连续的,从而帮助模型理解句子间关系。
在预训练完成后,BERT可以通过微调(Fine-tuning)应用于各种下游任务,例如情感分析、问答系统、命名实体识别等。微调过程相对简单,只需在BERT基础上添加一个或几个任务特定的层,并在特定任务的数据集上继续训练所有或部分层的参数。
### 2.2 自注意力在BERT中的实现
#### 2.2.1 自注意力机制在BERT中的角色
自注意力机制是BERT模型的核心组件之一,它允许模型在处理每个单词时考虑到句子中所有其他单词的信息。这种机制使得BERT能够捕捉复杂的双向语言表征,与传统的单向RNN或LSTM模型相比,BERT能够更准确地理解上下文。
自注意力机制的核心操作是计算查询(Q)、键(K)和值(V)之间的相似度,即 QK^T / sqrt(d_k),d_k是键的维度。通过缩放点积计算得到的权重,来加权值向量,从而得到每个位置的注意力输出。
```python
# Example of attention computation in PyTorch
Q = torch.matmu
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从零开始的Ubuntu系统安全加固指南:让系统固若金汤

# 1. Ubuntu系统安全加固概述
在当今的数字化时代,随着网络攻击的日渐频繁和多样化,确保操作系统的安全性变得尤为重要。Ubuntu,作为广泛使用的Linux发行版之一,其安全性自然不容忽视。系统安全加固是防御网络威胁的关键步骤,涉及从基础的权限配置到高级的加密技术的
【C语言性能提升】:掌握函数内联机制,提高程序性能

# 1. 函数内联的概念与重要性
内联函数是优化程序性能的重要技术之一,它在编译阶段将函数调用替换为函数体本身,避免了传统的调用开销。这种技术在许多情况下能够显著提高程序的执行效率,尤其是对于频繁调用的小型函数。然而,内联也是一把双刃剑,不当使用可能会导致目标代码体积的急剧膨胀,从而影响整个程序的性能。
对于IT行业的专业人员来说,理解内联函数的工作原理和应用场景是十
YOLOv8模型调优秘籍:检测精度与速度提升的终极指南

# 1. YOLOv8模型概述
YOLOv8是最新一代的实时目标检测模型,继承并改进了YOLO系列算法的核心优势,旨在提供更准确、更快速的目标检测解决方案。本章将对YOLOv8模型进行基础性介绍,为读者理解后续章节内容打下基础。
## 1.1 YOLOv8的诞生背景
YOLOv8的出现是随着计算机视觉
【VSCode高级技巧】:20分钟掌握编译器插件,打造开发利器

# 1. VSCode插件基础
## 1.1 了解VSCode插件的必要性
Visual Studio Code (VSCode) 是一款流行的源代码编辑器,它通过插件系统极大的扩展了其核心功能。了解如何安装和使用VSCode插件对于提高日常开发的效率至关重要。开发者可以通过插件获得语言特定的支持、工具集成以及个人化的工作流程优化等功能
Linux文件压缩:五种方法助你效率翻倍
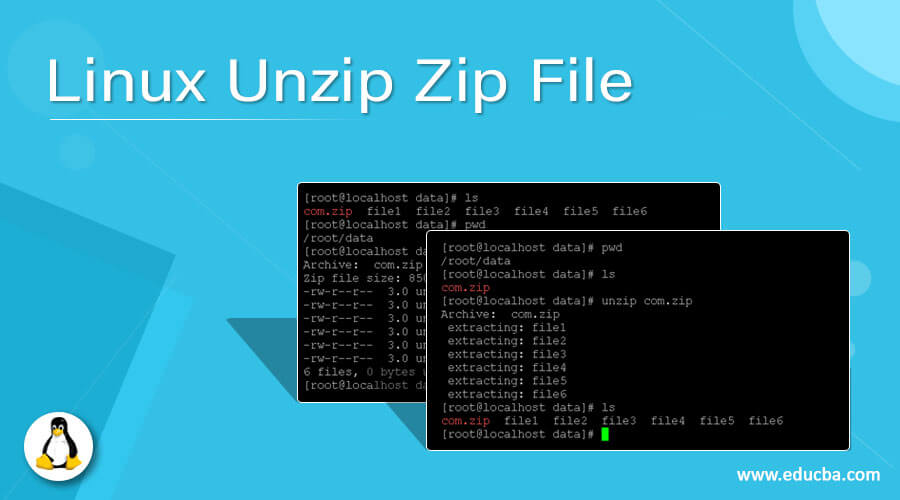
# 1. Linux文件压缩概述
Linux文件压缩是系统管理和数据传输中常见的操作,旨在减少文件或文件集合的大小,以便于存储和网络传输。压缩技术可以提高存储利用率、减少备份时间,并通过优化数据传输效率来降低通信成本。本章节将介绍Linux环境中文件压缩的基本概念,为深入理解后续章节中的技术细节和操作指南打下基础。
# 2. ```
# 第二章:理论基础与压缩工具介绍
## 2.1 压缩技
【PyCharm图像转换与色彩空间】:深入理解背后的科学(4个关键操作)

# 1. PyCharm环境下的图像处理基础
在进行图像处理项目时,一个稳定且功能强大的开发环境是必不可少的。PyCharm作为一款专业的Python IDE,为开发者提供了诸多便利,尤其在图像处理领域,它能够借助丰富的插件和库,简化开发流程并提高开发效率。本章节将重点介绍如何在PyCharm环境中建立图像处理项目的基础,并为后续章节的学习打下坚实的基础。
VSCode快捷键案例解析:日常开发中的快捷操作实例,专家级的实践
# 1. VSCode快捷键的概览与优势
在现代软件开发的快节奏中,提高
YOLOv8训练速度与精度双赢策略:实用技巧大公开

# 1. YOLOv8简介与背景知识
## YOLOv8简介
YOLOv8,作为You Only Look Once系列的最新成员,继承并发扬了YOLO家族在实时目标检测领域的领先地位。YOLOv8引入了多项改进,旨在提高检测精度,同时优化速度以适应不同的应用场景,例如自动驾驶、安防监控、工业检测等。
## YOLO系列模型的发展历程
YOLOv8的出现并不是孤立的,它是在YOLOv1至YOLOv7
【PyCharm中的异常处理】:专家教你如何捕获和分析异常
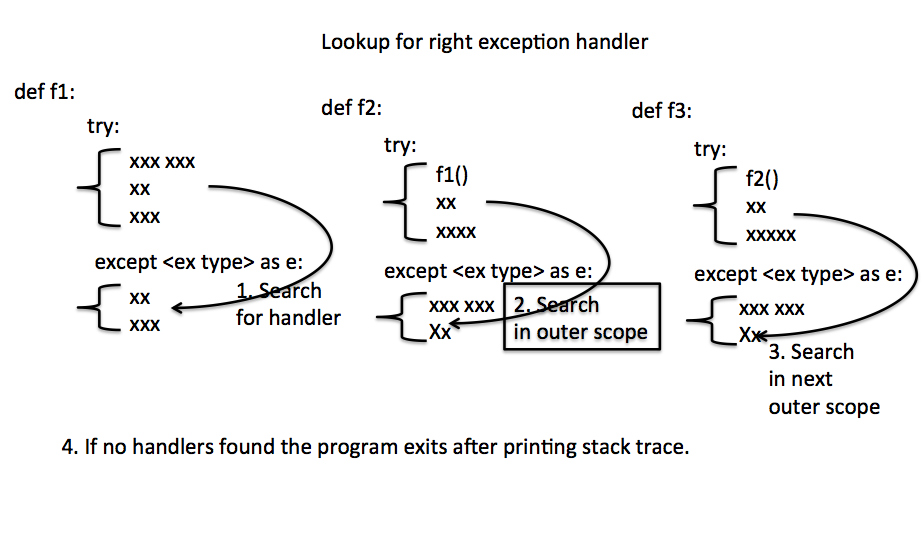
# 1. PyCharm与Python异常处理基础
在编写代码的过程中,异常处理是确保程序鲁棒性的重要部分。本章将介绍在使用PyCharm作为开发IDE时,如何理解和处理Python中的异常。我们将从异常处理的基础知识开始,逐步深入探讨更高级的异常管理技巧及其在日常开发中的应用。通过本章的学习,你将能够更好地理解Python异常处理机制,以及如何利用PyCharm提供的工具来提高开发效率。
在开始之前,让我们首先明确异常
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )