【Linux数据分析优化】:Anaconda在Linux系统中的高级应用技巧
发布时间: 2024-12-10 05:59:00 阅读量: 7 订阅数: 14 

在Linux服务器上安装Anaconda使用conda
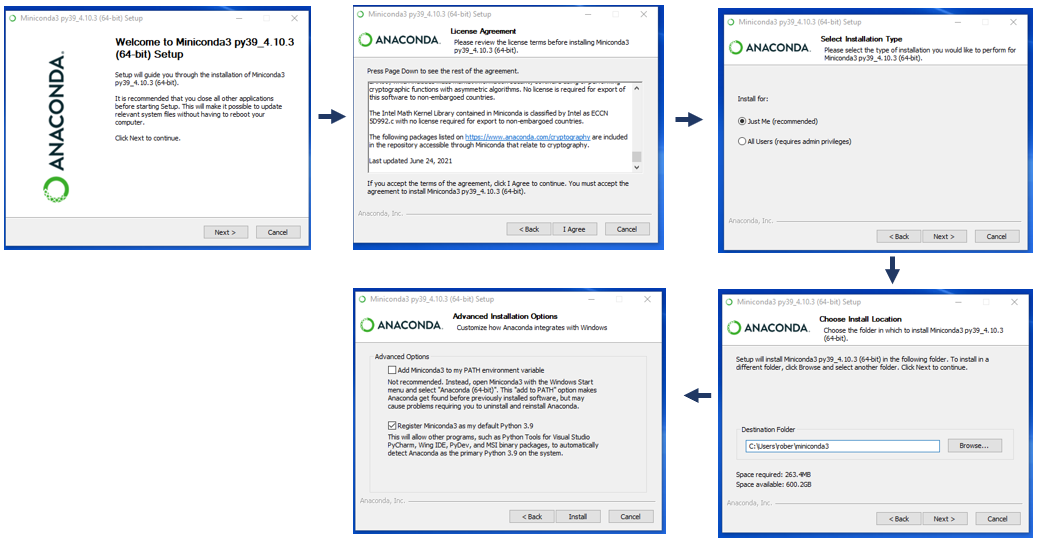
# 1. Anaconda简介及环境配置
## 1.1 Anaconda概述
Anaconda是一个开源的Python发行版本,它旨在简化包管理和部署。Anaconda的管理器conda,可以快速安装、运行和升级包及其依赖关系。它还包含了一个名为Anaconda Navigator的图形界面,方便用户直观地进行环境配置和包管理。
## 1.2 Anaconda环境配置
### 1.2.1 安装Anaconda
Anaconda的安装过程简单快捷。首先从[官方网站](https://www.anaconda.com/products/individual)下载对应操作系统的安装包,执行安装脚本并遵循提示操作即可。安装完成后,通过在命令行输入`conda --version`来验证安装是否成功。
### 1.2.2 配置Conda环境
环境管理是Anaconda的核心功能之一。通过以下命令,可以创建一个新的环境,安装特定版本的Python,并激活该环境:
```bash
conda create -n myenv python=3.8
conda activate myenv
```
通过环境管理,用户可以在隔离的环境中安装不同版本的库,避免版本冲突,同时也便于对项目依赖进行版本控制。
### 1.2.3 安装第三方包
使用conda命令可以安装各种第三方包:
```bash
conda install numpy pandas
```
这会自动处理好所有依赖,简化了包的安装流程。Anaconda还支持通过pip安装包,对于那些conda仓库中没有的包尤其有用。
本章介绍了Anaconda的基本概念和环境配置方法,为后续章节中进行Linux下的数据分析工作打下了基础。接下来的章节将深入探讨Linux下的数据分析工具和实践。
# 2. Linux数据分析基础
### 2.1 数据分析常用工具介绍
#### 2.1.1 Jupyter Notebook的基本使用
Jupyter Notebook是一个开源Web应用程序,允许你创建和共享包含实时代码、方程式、可视化和解释文本的文档。它支持多种编程语言,但是特别受到Python社区的青睐。对于数据分析师来说,Jupyter Notebook提供了一个交互式的环境,非常适合探索性数据分析和快速原型设计。
在Linux环境下安装Jupyter Notebook非常简单,可以使用Anaconda来快速搭建环境。首先,确保你已经安装了Anaconda,然后打开终端,执行以下命令创建一个新的环境并安装Jupyter:
```bash
conda create -n jupyter_env python=3.8 jupyter
```
激活环境:
```bash
conda activate jupyter_env
```
安装完成后,你可以通过以下命令启动Jupyter Notebook:
```bash
jupyter notebook
```
启动后,系统会自动打开默认的Web浏览器,呈现Jupyter Notebook的主界面。在那里,你可以创建新的笔记本,并开始编写和执行Python代码。
### 2.1.2 Pandas数据处理框架
Pandas是一个开源的Python数据分析库,提供了高性能、易用的数据结构和数据分析工具。它广泛应用于数据清洗、数据分析和数据可视化等任务。
Pandas的基本数据结构是DataFrame,可以看作是一个表格或二维数组,非常适合于处理结构化数据。下面是创建和操作DataFrame的一个简单示例:
```python
import pandas as pd
# 创建一个简单的DataFrame
data = {'Name': ['Alice', 'Bob', 'Claire'],
'Age': [24, 30, 25],
'Gender': ['Female', 'Male', 'Female']}
df = pd.DataFrame(data)
print(df)
```
输出结果将是:
```
Name Age Gender
0 Alice 24 Female
1 Bob 30 Male
2 Claire 25 Female
```
Pandas还提供了数据的导入和导出功能,支持多种文件格式,如CSV、Excel、JSON等。下面是一个读取CSV文件并进行数据处理的例子:
```python
# 读取CSV文件
df = pd.read_csv('data.csv')
# 数据清洗:去除空值
df.dropna(inplace=True)
# 数据预处理:添加新列
df['New Column'] = df['Existing Column'] * 10
# 数据分析:分组并计算平均值
grouped = df.groupby('Category').mean()
# 数据导出到新的CSV文件
grouped.to_csv('grouped_data.csv')
```
### 2.2 Linux系统中数据处理流程
#### 2.2.1 数据的导入与导出
在Linux系统中,数据的导入和导出是数据分析流程的第一步。Pandas提供了非常便捷的方法来实现这一过程。以下是一个将数据从CSV文件导入到DataFrame,并将处理后的数据导出到新的CSV文件的示例:
```python
# 导入数据
df = pd.read_csv('/path/to/input/data.csv')
# 数据处理代码...
# 导出数据
df.to_csv('/path/to/output/data.csv', index=False)
```
#### 2.2.2 数据清洗和预处理技巧
数据清洗和预处理是数据分析中非常重要的步骤。它包括去除重复数据、处理缺失值、异常值检测和纠正等。下面是一个数据清洗和预处理的示例:
```python
# 去除重复数据
df.drop_duplicates(inplace=True)
# 处理缺失值,这里简单地用平均值填充
df.fillna(df.mean(), inplace=True)
# 异常值处理,假设'Age'列中大于60的值为异常
df['Age'] = df['Age'].apply(lambda x: x if x <= 60 else np.nan)
```
#### 2.2.3 数据分析和可视化实践
数据可视化能够帮助我们更直观地理解数据。Pandas与Matplotlib、Seaborn等可视化库整合良好,可以轻松创建图表。下面是一个简单的例子,展示如何使用Pandas和Matplotlib绘制一个散点图:
```python
import matplotlib.pyplot as plt
# 假设我们有一个DataFrame 'df',包含'x'和'y'两列数据
df.plot(kind='scatter', x='x', y='y')
plt.show()
```
### 2.3 性能监控与系统资源优化
#### 2.3.1 系统资源监控工具
在Linux系统中,我们可以使用多种工具进行资源监控。例如,`top`、`htop`、`vmstat`、`iostat`等。这些工具可以帮助我们了解CPU、内存、磁盘I/O和网络I/O的使用情况。下面是一个使用`top`命令查看系统资源使用情况的例子:
```bash
top
```
该命令将提供一个实时更新的列表,其中列出了当前系统中资源使用率最高的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在为数据科学和分析领域的专业人士提供有关 Anaconda 的全面学习资源和社区推荐。涵盖的主题包括:
* Anaconda 入门指南
* 包管理和工作流程优化
* Jupyter Notebook 集成
* 数据预处理和清洗
* 版本控制策略
* 大数据处理
* Linux 和 Windows 系统中的高级应用技巧
* 社区资源和学习策略
* 企业级和云端数据环境部署
* SQL 数据库集成
通过这些文章,读者可以深入了解 Anaconda 的强大功能,并学习如何将其有效地应用于各种数据科学和分析任务。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入探索内存乒乓机制:C代码如何实现高效缓存

参考资源链接:[C代码实现内存乒乓缓存与消息分发,提升内存响应](https://wenku.csdn.net/doc/64817668d12cbe7ec369e795?spm=1055.2635.3001.10343)
# 1. 内存乒乓机制的基础概念
内存乒乓机制是计算机内存管理中一种优化手段,其核心在于利用有限的内存资源实现高效的数据处理。该机制涉及交替使用两块内存区域,一块正在使用时,另一块则进行数据
【Cadence放大器实战技巧大公开】:频率响应与极零点调谐一步到位

参考资源链接:[Candence分析:放大器极零点与频率响应解析](https://wenku.csdn.net/doc/649e6f207ad1c22e797c681e?spm=1055.2635.3001.10343)
# 1. 放大器基础理论与频率响应
在电子工程领域,放大器是重要的构建模块,它能够增加信号的幅度或功率。要深入理解放大器的性能,必须掌握其基础理论和频率响应。频率响应,是指放大器对不同频率信号的放大能力。了解和分析
固体物理的VASP魔法:理论到实践的完整应用攻略
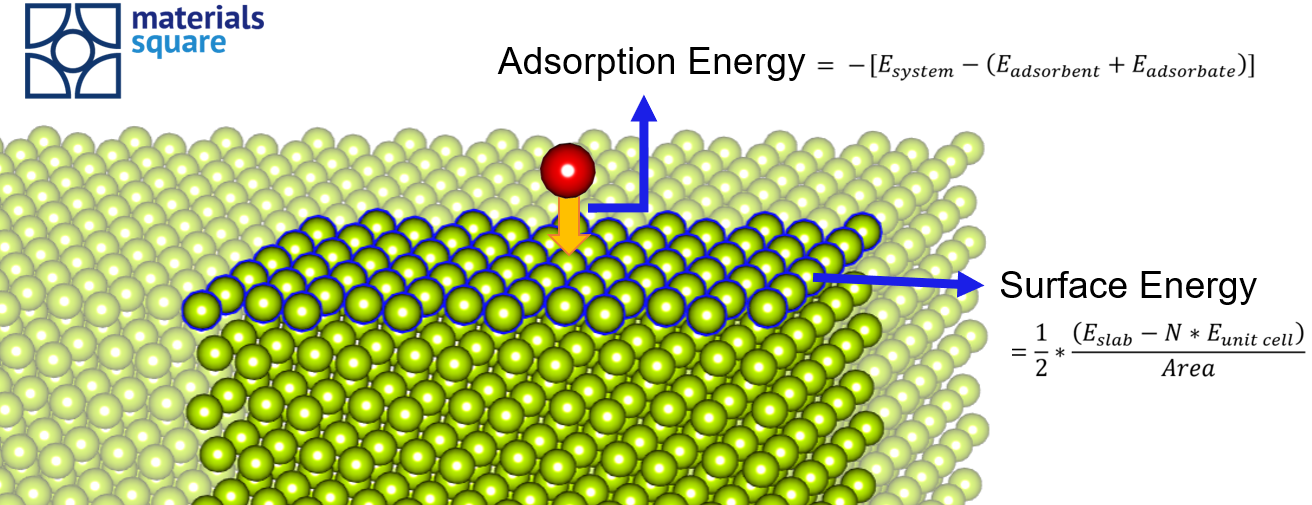
参考资源链接:[vasp中文使用指南:清华大学苏长荣老师编撰](https://wenku.csdn.net/doc/1xa94iset7?spm=1055.2635.3001.10343)
# 1. VASP软件概述及基本操作
## 1.1 VASP软件简介
VASP(Vienna Ab initio Simulation Package)是一款广泛应用于材料科学和凝聚态物理领域的第一性
网络安全必备:H3C交换机MAC绑定与黑名单的深度剖析及实战应用

参考资源链接:[H3C交换机:实战教程-黑名单、MAC绑定与ACL综合配置](https://wenku.csdn.net/doc/64697c9e543f844488bebdc7?spm=1055.2635.3001.10343)
# 1. H3C交换机MAC绑定与黑名单概念解析
## 1.1 交换机安全的背景
在当今网络安全形势日益复杂的背景下,企业网络面临着各种安全威胁。通过诸
揭秘HBM保护:JESD22-A114-B标准的实战应用与合规性指南

参考资源链接:[JESD22-A114-B(EDS-HBM).pdf](https://wenku.csdn.net/doc/6401abadcce7214c316e91b7?spm=1055.2635.3001.10343)
# 1. HBM保护的必要性和基本原理
【网络瓶颈不再难题】:nlbwmon实战案例分析与故障排除手册
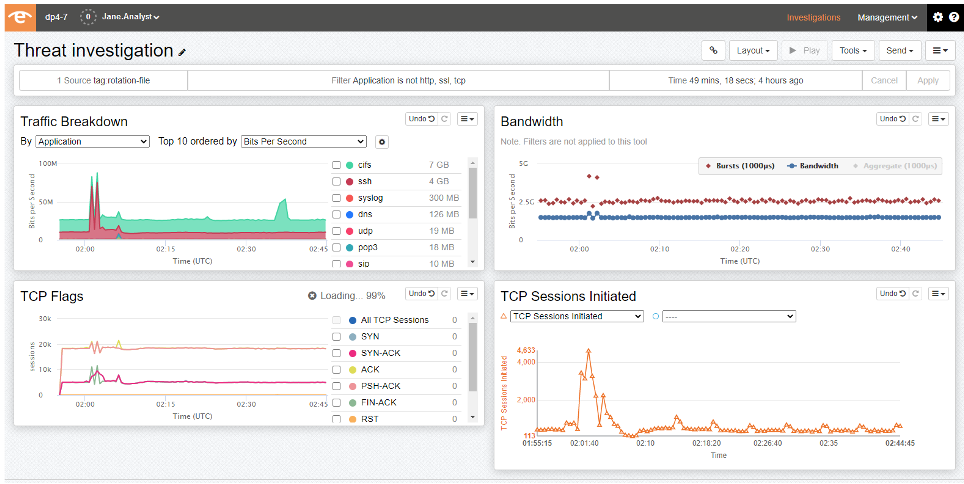
参考资源链接:[Openwrt带宽统计:nlbwmon的安装与优化](https://wenku.csdn.net/doc/3egvhwv2wq?spm=1055.2635.3001.10343)
# 1. 网络性能监控与瓶颈识别
在现代的IT环境中,网络性能监控是确保业务连续性和高效运营的关键组成部分。随着数据流量和网络复杂性的增加,监控工具
深入挖掘PLC-ANALYZER Pro 6:揭秘高级功能在定制化应用中的潜力
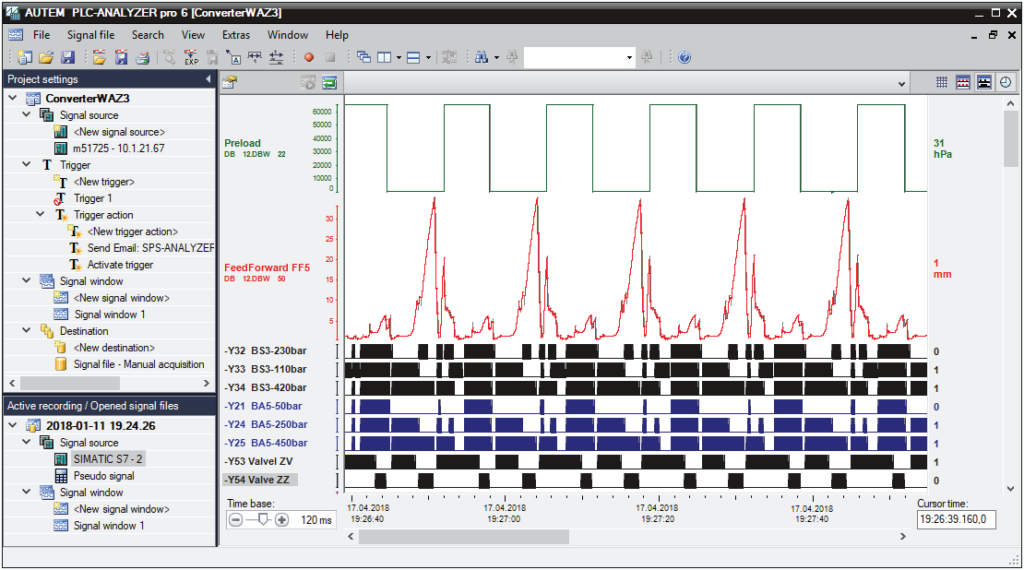
参考资源链接:[PLC-ANALYZER pro 6用户手册:全面指南](https://wenku.csdn.net/doc/mg061y42p0?spm=1055.2635.3001.10343)
# 1. PLC-ANALYZER Pro 6基础介绍
## 1.1 简介与背景
PLC-ANALYZ
CREO事件驱动设计实战:VB API事件处理精要

参考资源链接:[CREO二次开发VB API向导](https://wenku.csdn.net/doc/6412b5efbe7fbd1778d44ed5?spm=1055.2635.3001.10343)
# 1. CREO事件驱动设计概述
在现代计算机辅助设计(CAD)软件中,事件驱动设计已成为提高用户交互效率和软件响应能力
Artix7资源管理宝典:高效利用硬件资源的10大技巧
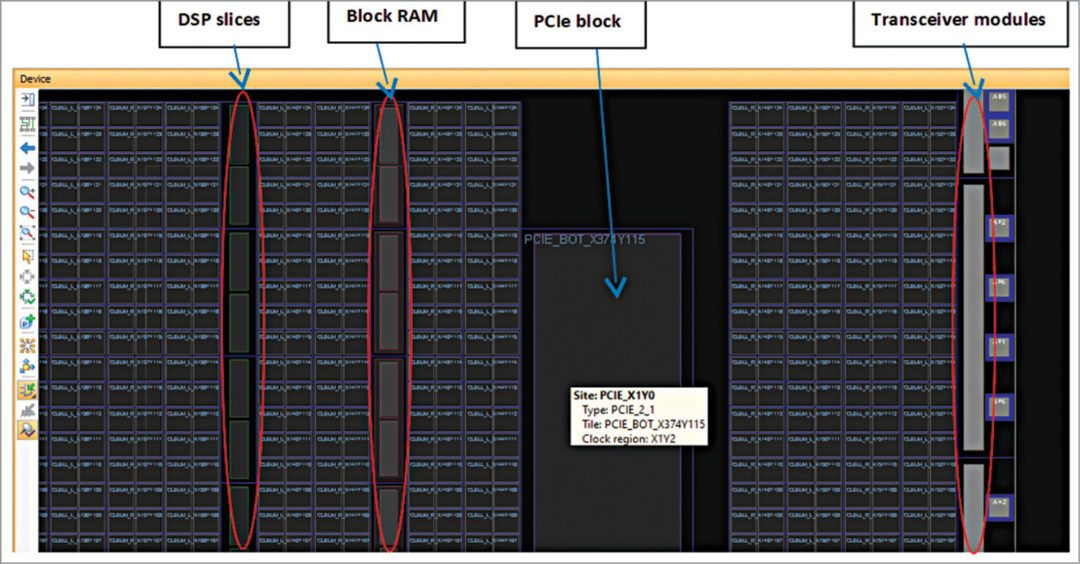
参考资源链接:[《Artix7修炼秘籍》-MIA701第二季20171009.pdf](https://wenku.csdn.net/doc/6412b7aabe7fbd1778d4b1bf?spm=1055.2635.3001.10343)
# 1. Artix7资源管理简介
Artix7作为Xilinx推出的最新一代FPGA芯片,其强大的资源管理功能对系统性能的优化有着至关重要的作用。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )