HBase与Hadoop生态系统的集成与优化
发布时间: 2024-01-11 08:59:50 阅读量: 53 订阅数: 21 
# 1. HBase与Hadoop生态系统的概述
## 1.1 HBase简介
HBase是一个开源的分布式非关系型数据库,它建立在Apache Hadoop之上,提供了实时读/写访问大规模数据的能力。HBase采用了Google的Bigtable数据模型,适合存储半结构化数据,具有高可靠性、高性能和自动伸缩的特点。由于其水平扩展和强一致性的特性,HBase被广泛应用于互联网领域的大数据存储和实时分析任务中。
## 1.2 Hadoop生态系统概述
Apache Hadoop是一个能够对大量数据进行分布式处理的开源软件框架。它主要解决了海量数据的存储和并行计算问题,核心包括Hadoop分布式文件系统(HDFS)和MapReduce计算框架。除了HBase外,Hadoop生态系统还包括了Hive、Pig、Spark等组件,为不同类型的数据处理场景提供了多样化的解决方案。
## 1.3 HBase与Hadoop的关系与集成优势
HBase与Hadoop生态系统紧密集成,通过与HDFS、MapReduce、YARN等组件的配合,实现了高效的分布式数据存储和计算。HBase可以借助Hadoop生态系统的资源管理和并行计算能力,实现大规模实时数据处理和分析。同时,HBase还能够与Hadoop生态系统的其他组件协同工作,实现更丰富的数据处理功能和场景覆盖。
# 2. HBase与Hadoop集成的实施步骤
在本章中,我们将详细介绍HBase与Hadoop集成的实施步骤。HBase作为Hadoop生态系统中的分布式数据库,需要与Hadoop的核心组件如HDFS、MapReduce和YARN进行集成,以实现数据的存储和计算。
#### 2.1 HBase与HDFS集成
HBase与HDFS的集成是HBase能够利用Hadoop分布式文件系统进行数据存储的基础。以下是HBase与HDFS集成的步骤:
1. 步骤一:安装和配置Hadoop集群
首先,需要搭建一个Hadoop分布式集群,并确保集群的正常运行。可以参考Hadoop官方文档或其他相关资料进行安装和配置。
2. 步骤二:安装和配置HBase
在所有HBase节点上,需要安装和配置HBase。确保HBase的版本与Hadoop集群兼容,并且配置文件中正确指定了HDFS的地址、端口等信息。
3. 步骤三:启动HDFS和HBase服务
在Hadoop集群中的所有节点上,启动HDFS和HBase服务。可以使用Hadoop提供的脚本或命令来启动这些服务。
4. 步骤四:创建HBase表
使用HBase的Shell或编程接口,创建一个HBase表。可以定义表的列族和列等属性。
5. 步骤五:导入数据到HBase表
将数据从其他数据源导入到HBase表中。可以使用HBase提供的工具或编程接口来实现。
6. 步骤六:验证HBase与HDFS集成
在Hadoop集群中的任意节点上,通过HBase的Shell或编程接口进行数据的读取和写入操作,以验证HBase与HDFS的集成是否成功。
#### 2.2 HBase与MapReduce集成
HBase与MapReduce的集成是为了能够利用MapReduce的计算能力对HBase中的数据进行分析和处理。以下是HBase与MapReduce集成的步骤:
1. 步骤一:编写MapReduce程序
首先,编写一个MapReduce程序,用于对HBase中的数据进行处理和分析。可以使用Java编程语言来实现,也可以选择其他语言如Python或Scala。
2. 步骤二:设置HBase作为输入和输出
在MapReduce程序中,通过配置Job的输入和输出格式,将HBase作为输入和输出源。可以使用HBase提供的TableInputFormat和TableOutputFormat等类来实现。
3. 步骤三:运行MapReduce作业
使用Hadoop提供的工具或命令来提交和运行MapReduce作业。确保Hadoop集群正常运行,并且MapReduce作业能够正确访问和操作HBase表。
4. 步骤四:验证HBase与MapReduce集成
检查MapReduce作业的运行结果,验证HBase与MapReduce的集成是否成功。可以通过查看作业的日志和输出结果来进行验证。
#### 2.3 HBase与YARN集成
HBase与YARN的集成是为了能够更好地利用集群资源进行任务调度和管理。以下是HBase与YARN集成的步骤:
1. 步骤一:安装和配置YARN集群
首先,需要搭建一个YARN集群,并确保集群的正常运行。可以参考Hadoop官方文档或其他相关资料进行安装和配置。
2. 步骤二:配置HBase与YARN集成
在HBase的配置文件中,设置YARN作为资源管理器。配置文件中需要指定YARN的地址、端口等信息。
3. 步骤三:启动HBase和YARN服务
启动HBase和YARN服务,确保它们在集群中的所有节点上正常运行。可以使用Hadoop提供的脚本或命令来启动这些服务。
4. 步骤四:运行HBase作业在YARN上
使用HBase提供的工具或命令,在YARN集群上运行HBase作业。通过指定作业的参数和资源要求,将作业提交到YARN进行调度和执行。
5. 步骤五:验证HBase与YARN集成
检查HBase作业在YARN上的运行结果,验证HBase与YARN的集成是否成功。可以通过查看作业的日志和输出结果来进行验证。
#### 2.4 HBase与Hadoop集成的最佳实践
在HBase与Hadoop集成的过程中,可以考虑以下最佳实践:
1. 选择正确的Hadoop版本和HBase版本,确保它们之间具有兼容性。
2. 配置Hadoop集群和HBase集群

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《大数据之hbase详解》深度剖析HBase的各个方面,涵盖了HBase的安装与环境搭建、CRUD操作指南、数据模型详解与实际案例分析、表设计最佳实践、数据写入与读取性能优化策略、数据存储结构解析等多个主题。此外,还包括了HBase的读写原理、数据一致性与并发控制、数据压缩与存储空间优化策略、数据版本管理与数据生命周期控制、数据的过期清理与自动转移、数据备份与恢复策略等内容。同时,本专栏还涉及了HBase集群架构与节点角色、高可用性与故障恢复策略、与Hadoop生态系统的集成与优化、与其他分布式数据库的对比与性能评估、以及与NoSQL数据库的比较与选择指南等内容。无论您是初学者还是有一定经验的HBase用户,本专栏都将为您提供全面深入的专业指导,帮助您更好地理解和运用HBase。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Maxwell铁耗计算进阶】:提高精度,减少损耗的实用技巧
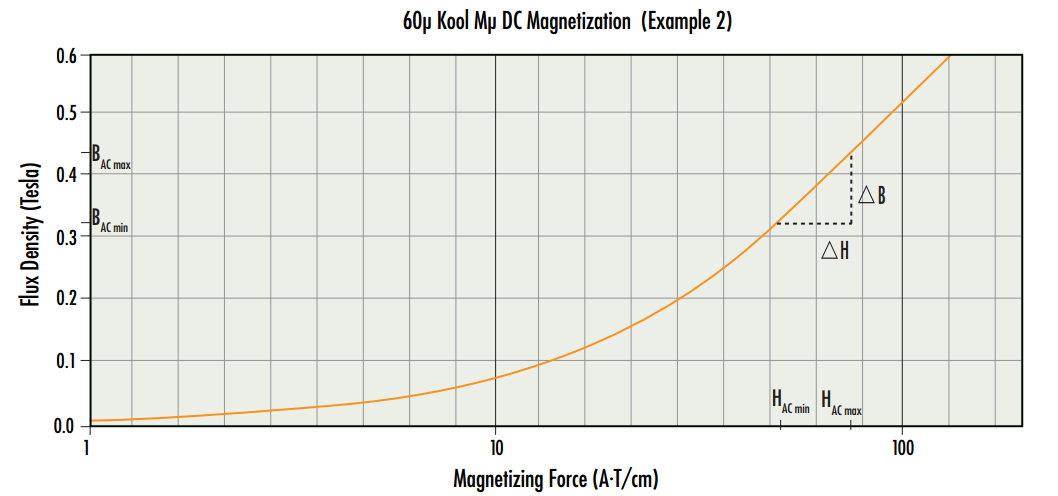
参考资源链接:[Maxwell中的铁耗分析与B-P曲线设置详解](https://wenku.csdn.net/doc/69syjty4c3?spm=1055.2635.3001.10343)
# 1. Maxwell铁耗计算基础
在电气工程领域,准确计算铁耗对于电机和变压器等设备的设
【数据驱动性能提升】:RTC6激光控制卡数据采集与分析实战

参考资源链接:[SCANLAB激光控制卡-RTC6.说明书](https://wenku.csdn.net/doc/71sp4mutsg?spm=1055.2635.3001.10343)
# 1. 数据驱动性能提升概述
在当今高度数字化的世界中,数据成为了推
【VCS故障诊断不求人】:一步步教你排查并解决故障的技巧

参考资源链接:[VCS用户手册:2020.03-SP2版](https://wenku.csdn.net/doc/hf87hg2b2r?spm=1055.2635.3001.10343)
# 1. VCS故障诊断基础
电气特性深度剖析:VGA连接器的电压和电流要求完全解读

参考资源链接:[标准15针VGA接口定义](https://wenku.csdn.net/doc/6412b795be7fbd1778d4ad25?spm=1055.2635.3001.10343)
# 1. VGA连接器概述与电气特性基础
## VGA连接器的起源与发展
视频图形阵列(VGA)连接器,作为一种视频
VBA调用外部程序:动态链接库与自动化集成
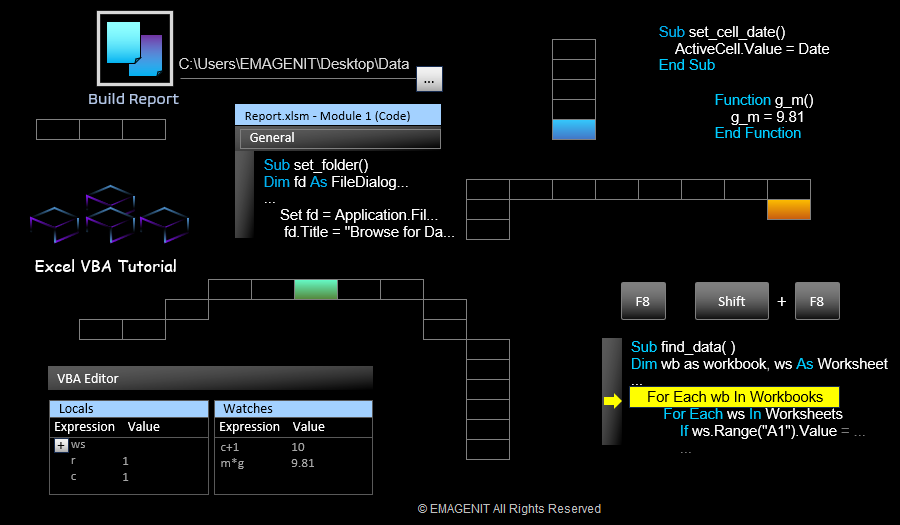
参考资源链接:[Excel VBA编程指南:从基础到实践](https://wenku.csdn.net/doc/6412b491be7fbd1778d40079?spm=1055.2635.3001.10343)
# 1. VBA与外部程序交互概述
## 1.1 交互的必要性与应用背景
在现代IT工作流程中,自动化和效率是追求的两大关键词。VBA(Visual Basic for Applications)作为一种广泛使用
【Sabre Red日志分析精讲】:3个高级技术深入挖掘执行信息

参考资源链接:[Sabre Red指令-查询、定位、出票收集汇总(中文版)](https://wenku.csdn.net/doc/6412b4aebe7fbd1778d4071b?spm=1055.2635.3001.10343)
# 1. Sabre Red日志分析入门
## 1.1 认识Sab
PM_DS18边界标记:技术革新背后的行业推动者
参考资源链接:[Converge仿真软件初学者教程:2.4版本操作指南](https://wenku.csdn.net/doc/sbiff4a7ma?spm=1055.2635.3001.10343)
# 1. PM_DS18边界标记的技术概览
## 1.1 边界标记技术简介
边界标记技术是一种在计算机科学中常用的技术,用于定义和处理数据元素之间的界限。这种技术广泛应用于数据管理、网络安全、信息检索等多个领域,提供了对数
SV630N高速挑战应对:高速应用中的高精度解决方案
参考资源链接:[汇川SV630N系列伺服驱动器用户手册:故障处理与安装指南](https://wenku.csdn.net/doc/3pe74u3wmv?spm=1055.2635.3001.10343)
# 1. SV630N高速应用概述
在现代电子设计领域中,SV630N作为一种专为高速应用设计的处理器,其高速性能和低功耗特性使其在高速数据传输、云计算和物
KEPSERVER与Smart200远程监控与维护:全面战略
参考资源链接:[KEPSERVER 与Smart200 连接](https://wenku.csdn.net/doc/64672a1a5928463033d77470?spm=1055.2635.3001.10343)
# 1. KEPSERVER与Smart200概述
工业自动化是现代制造业的核心,KEPServerEX 和 Smart200 是工业自动
中兴IPTV机顶盒应用安装秘籍:轻松管理你的应用库

参考资源链接:[中兴IPTV机顶盒 zx10 B860AV1.1设置说明](https://wenku.csdn.net/doc/64793a06d12cbe7ec330e370?spm=
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )