【实时洞察】:MySQL与Elasticsearch集成实现即时数据分析
发布时间: 2024-12-07 11:51:22 阅读量: 11 订阅数: 11 

MySQL 与 Elasticsearch 数据不对称问题解决办法
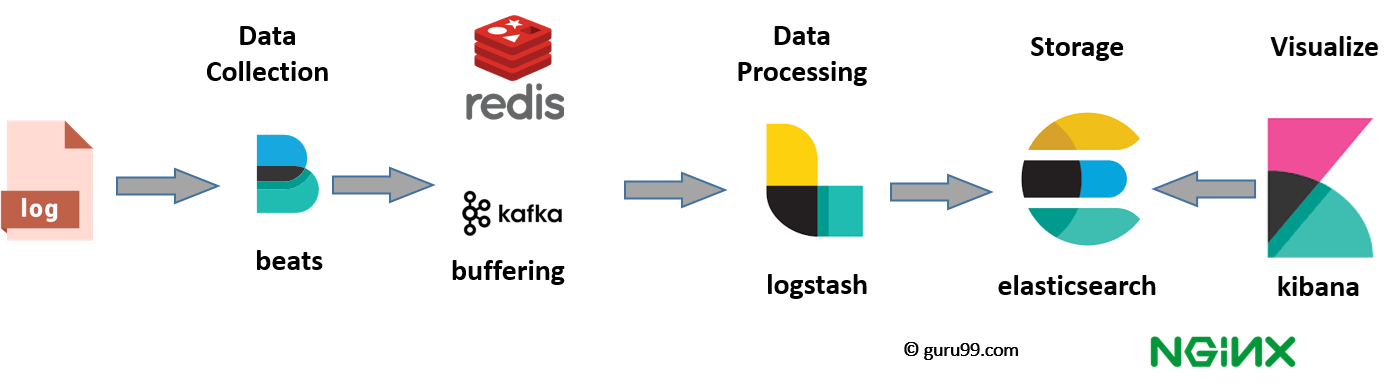
# 1. MySQL与Elasticsearch集成概述
随着大数据时代的到来,企业和开发者需要对海量数据进行高效的存储、检索和分析。MySQL和Elasticsearch作为业界常用的数据库和搜索引擎,在数据处理方面各有专长。集成MySQL与Elasticsearch,可以实现对结构化数据的存储以及复杂查询,同时提供快速、实时的全文搜索能力。本章节将概述两者集成的背景、重要性及应用场景,为后续章节打下基础。
集成MySQL与Elasticsearch是一个复杂的工程,需要对两者的工作原理、功能特点和配置方法有深入的了解。在深入探讨集成方案之前,我们需要先了解MySQL的基础知识和Elasticsearch的搜索引擎原理。
在下一章,我们将从MySQL数据库的基础开始,探索其安装、配置及核心概念,为理解数据同步和索引策略打下坚实的基础。随后,我们将深入Elasticsearch的内部世界,分析其分布式架构、数据模型和集群管理等关键知识点。这一切都将成为我们构建即时数据分析应用案例的基石。
# 2. MySQL数据库基础
## 2.1 MySQL的安装与配置
### 2.1.1 下载安装MySQL
在安装MySQL之前,您需要访问MySQL官方网站或其镜像站点下载最新版本的MySQL服务器安装包。对于大多数操作系统,MySQL提供了预编译的二进制包,包括Windows、macOS和Linux发行版。以Linux系统为例,通常可以使用包管理器进行安装。以下是基于Debian/Ubuntu系统的安装示例。
在终端运行以下命令来下载并安装MySQL服务器:
```bash
sudo apt-get update
sudo apt-get install mysql-server
```
安装过程中,系统会要求您设置root用户的密码,并询问是否配置`mysql_secure_installation`脚本来增强安装的安全性。完成安装后,您可以通过以下命令启动MySQL服务:
```bash
sudo systemctl start mysql
```
### 2.1.2 配置MySQL服务器
MySQL服务器安装完成后,需要进行基本配置以确保其正确运行。配置文件通常位于`/etc/mysql/`目录下,针对Debian/Ubuntu的配置文件名为`my.cnf`。配置项可能包括内存使用、连接数限制和用户权限等。
编辑配置文件以调整参数,例如增加最大连接数:
```ini
[mysqld]
max_connections = 1000
```
然后重启MySQL服务使配置生效:
```bash
sudo systemctl restart mysql
```
在配置过程中,您还可以通过MySQL客户端工具测试连接,检查配置是否正确:
```bash
mysql -u root -p
```
输入`root`用户的密码后,如果能成功登录到MySQL,说明配置文件设置无误。
## 2.2 MySQL核心概念与结构
### 2.2.1 数据库、表、索引和关系
MySQL是一个关系型数据库管理系统,它使用了标准的SQL语言。数据库中的数据是通过表来组织的,表则由行和列组成。索引是提高查询效率的数据结构,允许数据库快速地定位到表的特定数据。关系则定义了表与表之间的关联方式。
### 2.2.2 MySQL的数据类型和存储引擎
MySQL支持多种数据类型,用于定义列可以存储的数据类型和范围。常见的数据类型包括整数类型、浮点类型、日期和时间类型以及字符类型等。此外,MySQL还支持多种存储引擎,如InnoDB和MyISAM,每个引擎提供了不同的特性和优势。
InnoDB作为MySQL默认的存储引擎,支持事务处理、外键和行级锁定。而MyISAM则在全文搜索和空间数据处理方面有优势。选择合适的存储引擎对于数据库的性能和功能有着决定性的影响。
## 2.3 MySQL数据操作实践
### 2.3.1 基本的CRUD操作
CRUD是创建(Create)、读取(Read)、更新(Update)和删除(Delete)的简称,是数据库管理中的基本操作。
- **创建操作**:使用`CREATE`语句创建数据库和表。
- **读取操作**:使用`SELECT`语句从表中查询数据。
- **更新操作**:使用`UPDATE`语句修改表中的数据。
- **删除操作**:使用`DELETE`语句从表中删除数据。
例如,创建一个名为`employees`的表:
```sql
CREATE TABLE employees (
id INT NOT NULL AUTO_INCREMENT,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
PRIMARY KEY (id)
);
```
对表进行基本的CRUD操作可以按照如下方式进行:
```sql
-- 插入新数据
INSERT INTO employees (first_name, last_name, email) VALUES ('John', 'Doe', 'john.doe@example.com');
-- 查询数据
SELECT * FROM employees;
-- 更新数据
UPDATE employees SET email = 'john.newemail@example.com' WHERE id = 1;
-- 删除数据
DELETE FROM employees WHERE id = 1;
```
### 2.3.2 SQL查询优化与索引策略
在数据库管理中,查询优化是提高性能的关键。创建索引是优化查询的常用方法。索引可以加快数据检索速度,但也需要额外的空间和维护时间。因此,建立合理的索引策略是必要的。
- **选择合适的列建立索引**:通常选择作为查询条件的列或经常用于排序和连接操作的列。
- **合理使用复合索引**:如果一个查询经常使用多个列作为条件,可以考虑创建复合索引。
- **分析查询执行计划**:使用`EXPLAIN`语句来分析查询的执行计划,确保索引被有效利用。
例如,创建一个复合索引:
```sql
CREATE INDEX idx_last_name_email ON employees (last_name, email);
```
在查询时,如果按照`last_name`和`email`的顺序进行过滤,MySQL将能够有效地利用复合索引。
```sql
EXPLAIN SELECT * FROM employees WHERE last_name = 'Doe' AND email = 'john.doe@example.com';
```
在使用索引时,还需注意维护索引的更新,定期分析表的性能,及时调整索引策略。通过这种方法,数据库操作的效率和性能将得到显著提升。
# 3. Elasticsearch搜索引擎原理
## 3.1 Elasticsearch基础架构
### 3.1.1 Elasticsearch分布式特性
Elasticsearch是一个分布式、全文本搜索引擎,它使用了简单的RESTful API进行通信,并且能够以JSON格式存储和检索数据。Elasticsearch的分布式特性是其核心优势之一,它能够让数据在多个节点上进行分片存储,实现了高可用性和水平扩展能力。
在分布式架构中,Elasticsearch通过多个节点组成的集群来保证服务的高可用性和数据的冗余。当一个节点发生故障时,Elasticsearch可以自动进行故障转移,保证服务不会中断。数据分片和复制机制是Elasticsearch分布式特性中的关键组成部分,它们共同保障了数据的可靠性。
此外,Elasticsearch集群通过动态发现机制可以轻松地添加或移除节点,无需进行复杂的配置。这一特性使得Elasticsearch非常适合处理大规模数据集,并在云计算环境中提供弹性扩展能力。
### 3.1.2 核心组件和工作原理
Elasticsearch集群由多个节点组成,每个节点可以承担不同的角色,如主节点(Master-eligible nodes)、数据节点(Data nodes)和协调节点(Client nodes)。每个节点都有自己的职责,它们相互协作共同提供搜索服务。
核心组件包括索引(Index)、分片(Shards)和复制(Replicas)。索引是一个包含相似文档的集合,而分片是索引的逻辑分隔,它将大索引划分为小块,从而实现分布式存储。复制则是为了数据安全和搜索性能而将分片进行复制,每个主分片都有一个或多个副本分片。
搜索操作时,Elasticsearch通过协调节点接收客户端的查询请求,然后在多个分片上并行执行搜索,最后将结果汇总返回给客户端。这个过程是Elasticsearch能够提供快速搜索的关键。
## 3.2 Elasticsearch的数据模型与查询语言
### 3.2.1 文档、索引和映射的概念
Elasticsearch的数据模型以文档为中心,文档是JSON格式的数据,可以包含各种类型的数据字段。每个文档都有一个唯一的ID,并且属于一个索引。索引可以看作是文档的集合,是Elasticsearch中存储、管理和搜索数据的基本单位。
映射(Mapping)则是定义了索引中文档的结构和文档中字段的数据类型,它决定了如何处理索引中的数据,例如是否对某个字段进行分词、索引等。正确设置映射对于数据搜索的效率和准确性至关重要。
### 3.2.2 查询 DSL 的深入理解
Elasticsearch使用查询DSL(Domain Specific Language)进行查询操作。查询DSL是一个灵活的查询语言,它允许用户执行多种类型的查询,包括精确查询、全文搜索、范围查询等。查询结果会返回匹配查询条件的文档列表。
在查询语句中,可以使用bool查询(Boolean Query)来组合多个查询条件,实现复杂的查询需求。此外,Elasticsearch还支持过滤器(Filter),它用于缓存结果,提高查询效率。
例如,一个全文搜索查询的DSL可能如下所示:
```json
GET /_search
{
"query": {
"match": {
"content": {
"query": "search engine",
"operator": "and"
}
}
}
}
```
这个查询表示在content字段中寻找包含“search engine”的文档。查询语句中的`operator`属性指定必须同时包含“search”和“engine”两个词。
## 3.3 Elasticsearch的集群管理和监控
### 3.3.1 集群状态监控与维护
集群状态监控是Elasticsearch日常运维中非常重要的一个环节。通过集群状态API

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MySQL 与 Elasticsearch 集成的高级技术。从数据同步机制到架构设计,从索引策略优化到故障诊断,文章全面解析了集成中的关键问题。此外,还重点关注了数据一致性、实时洞察、负载优化和多租户架构,提供了切实可行的解决方案。通过深入剖析集成过程中的挑战和机遇,专栏为读者提供了在实际应用中有效集成 MySQL 和 Elasticsearch 所需的知识和技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【图像分析软件深度剖析】:Image-Pro Plus 6.0 高级功能全面解读

参考资源链接:[Image-Pro Plus 6.0 中文
【智慧竞赛必备】:四人抢答器设计全面指南与优化秘籍
参考资源链接:[四人智力竞赛抢答器设计与实现](https://wenku.csdn.net/doc/6401ad39cce7214c316eebee?spm=1055.2635.3001.10343)
# 1. 四人抢答器设计概述
## 1.1 设计背景
在日常的学术研讨、知识竞赛以及各种娱乐节目中,我们经常能看到抢答器的身影。随着技术的发展和应用场景的多样化,对抢答器的性能和功能提出了更高的要求。一个高效、准确
高通Camera Chi-CDK Feature2性能与兼容性秘籍:跨平台与调优全攻略

参考资源链接:[高通相机Feature2框架深度解析](https://wenku.csdn.net/doc/31b2334rc3?spm=1055.2635.3001.10343)
# 1. Camera Chi-CDK Feature2概述
## 1.1 Camera Chi-CDK Feature2
验证规则的最佳实践:精通系统稳定性

参考资源链接:[2014年Mentor Graphics Calibre SVRF标准验证规则手册](https://wenku.csdn.net/doc/70kc3iyyux?spm=1055.2635.3001.10343)
# 1. 系统稳定性的基础理论
系统稳定性是指在一定时间内,系统保持其功能正常运行的能力。它是一个复杂的话题,涉及多个方面,包括硬
深入解析Android WebView文件下载:性能优化与安全性提升指南

参考资源链接:[Android WebView文件下载实现教程](https://wenku.csdn.net/doc/3ttcm35729?spm=1055.2635.3001.10343)
# 1. Android WebView文件下载基础
## 1.1 WebView概述
在移动应用开发中,WebView是一个重要的组件,它
【交互设计的艺术】:优雅地引导用户订阅小程序消息
参考资源链接:[小程序订阅消息拒绝后:如何引导用户重新开启及获取状态](https://wenku.csdn.net/doc/6451c400ea0840391e738237?spm=1055.2635.3001.10343)
# 1. 交互设计在小程序中的重要性
随着互联网技术的不断进步,小程序作为移动互联网领域的新宠,其用户界面(UI)和用户体验(UX)的重要性日益凸显。交互设计作为用户体验的核心
【S19文件错误排查】:高效排除常见错误,提升调试效率
参考资源链接:[S19文件格式完全解析:从ASCII到MCU编程](https://wenku.csdn.net/doc/12oc20s736?spm=1055.2635.3001.10343)
# 1. S19文件错误排查概述
S19文件错误排查是嵌入式开发中常见的工作流程之一,尤其在微控制器程序开发中占有重要的地位。本
【PLC编程语言对比】:梯形图与指令列表的优劣深度分析
参考资源链接:[PLC毕业设计题目大全:300+精选课题](https://wenku.csdn.net/doc/3mjqawkmq0?spm=1055.2635.3001.10343)
# 1. PLC编程语言概述
## 1.1 PLC编程语言的发展简史
可编程逻辑控制器(PLC)自20世纪60年代问世以来,便成为了工业自动化领域不可或缺的设备。PLC编程语言也随着技术的不断进步,从最初的继电器逻辑图,发展到如今包括梯形图、指令列表(IL)、功能块
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )