【Python自然语言处理终极指南】:零基础入门到高级实战技巧,打造文本分析利器
发布时间: 2024-12-07 06:23:28 阅读量: 51 订阅数: 16 

# 1. 自然语言处理基础和Python概述
## 1.1 自然语言处理简介
自然语言处理(NLP)是人工智能和语言学领域的一个分支,旨在使计算机能够理解、解释和生成人类语言。NLP涉及到语言学、计算机科学和数学等多领域知识,其目标是让机器能够处理和分析大量的自然语言数据。
## 1.2 Python在NLP中的地位
Python作为一种高级编程语言,在自然语言处理中扮演着至关重要的角色。其简洁的语法和强大的库支持,如NLTK、spaCy等,使得Python成为NLP领域开发者最喜欢的语言之一。Python的易用性和灵活性,使得复杂的数据处理任务变得简单。
## 1.3 Python的优势
Python之所以在NLP领域受到推崇,是因为其拥有以下优势:
- **易学易用**:Python拥有简洁清晰的语法,对初学者十分友好。
- **丰富的库**:Python有强大的标准库和第三方库支持,特别是在NLP领域,如NLTK、spaCy、gensim等。
- **社区支持**:Python有着庞大的开发者社区,为遇到问题的开发者提供了丰富的学习和解决问题的资源。
```python
# 示例:Python打印“Hello, World!”的代码
print("Hello, World!")
```
通过以上代码块,我们可以看到Python的简洁性。在学习自然语言处理时,掌握Python的基本语法和库使用是入门的第一步。随着学习的深入,将逐渐接触到NLP的各种高级应用和实践技巧。
# 2. Python自然语言处理工具安装与配置
自然语言处理(NLP)是计算机科学、人工智能和语言学领域中一个活跃的研究领域。它致力于分析、理解和生成人类语言,无论是口头还是书面形式。Python作为一门在数据科学和机器学习领域广受欢迎的语言,同样在自然语言处理方面表现出色。这得益于它拥有大量功能强大的库和工具。
### 2.1 Python环境的搭建
#### 2.1.1 安装Python解释器和包管理工具
为了开始进行自然语言处理,首先需要一个适合的Python环境。Python解释器是Python语言的运行时组件,而包管理工具则是用于安装、更新和管理Python包的工具。最常用的Python包管理工具是`pip`。
安装Python解释器的推荐方法是下载并安装Python的官方安装程序,它将自动安装`pip`。确保在安装过程中勾选了“Add Python to PATH”选项,这样可以在命令行中直接运行Python和`pip`。
下面是在Windows系统中安装Python的简单命令示例:
```bash
# 下载Python安装程序并运行
python-3.9.0-amd64.exe /quiet InstallAllUsers=1 PrependPath=1 Include_test=0
```
安装完成后,可以在命令行中使用以下命令检查Python版本和`pip`版本,确保安装成功:
```bash
# 检查Python版本
python --version
# 检查pip版本
pip --version
```
#### 2.1.2 配置Python开发环境
Python开发环境的配置不仅包括安装Python解释器,还应当包括一些为提高开发效率的工具和插件。常见的集成开发环境(IDE)如PyCharm或VS Code,都提供了便捷的Python开发环境,并内置了代码调试、语法高亮、代码补全等便利功能。
在VS Code中配置Python环境的步骤如下:
1. 下载并安装VS Code。
2. 通过快捷键`Ctrl+Shift+P`打开命令面板,输入并安装`Python`扩展。
3. 重启VS Code后,打开一个新的Python文件,VS Code将自动检测到解释器,并提示你安装推荐的包。
4. 根据需要安装其他插件,如`Jupyter`扩展,用于编写交互式代码。
### 2.2 核心NLP库的安装与配置
#### 2.2.1 安装NLTK、spaCy等NLP库
在NLP领域,NLTK(Natural Language Toolkit)和spaCy是最流行的两个Python库。它们提供了处理文本的工具,如分词、标注、解析等,并且拥有丰富的语言数据集和预训练模型。
安装NLTK和spaCy的命令如下:
```bash
# 安装NLTK
pip install nltk
# 安装spaCy
pip install spacy
```
安装完成后,可以通过以下Python代码下载NLTK和spaCy的预处理模型和数据集:
```python
import nltk
import spacy
# NLTK数据集下载
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('stopwords')
nltk.download('wordnet')
# spaCy预训练模型下载
!python -m spacy download en_core_web_sm
```
#### 2.2.2 环境依赖和库版本选择
在处理NLP任务时,不同库可能有不同的版本,而版本间的兼容性对于代码的稳定性至关重要。因此,在安装和配置库时,应当注意环境依赖和版本兼容性。
例如,NLTK的某些库版本可能与Python 3.8以上版本不完全兼容,因此建议始终查看官方文档,确认最佳实践。
```bash
# 查看可用版本
pip install spacy --upgrade
pip show nltk
```
选择正确的库版本不仅可以确保代码能够正常运行,还可以避免性能问题和安全漏洞。同时,检查并安装所有依赖项也是保证NLP系统稳定运行的关键。
### 2.3 理解自然语言处理的数据类型
#### 2.3.1 文本数据的基本处理
文本数据在自然语言处理中的处理通常包括清洗、规范化、编码等多个步骤。基本处理的目的是将原始文本转换成适合分析的格式。
基本文本处理的Python代码示例如下:
```python
import re
# 示例文本
text = "Python3.9 is powerful, but it's not good for everyone."
# 去除标点符号
cleaned_text = re.sub(r'[^\w\s]', '', text)
print(cleaned_text)
```
#### 2.3.2 文本编码和预处理流程
文本编码通常指将文本中的字符转换成计算机可以处理的数字形式。常见的编码方式有ASCII、UTF-8等。预处理流程则可能包括去除停用词、词干提取、词形还原等步骤。
以下是一个简单的文本编码和预处理流程的Python代码:
```python
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
# 英文停用词列表
stop_words = set(stopwords.words('english'))
lemmatizer = WordNetLemmatizer()
def preprocess(text):
# 分词
words = nltk.word_tokenize(text)
# 转换为小写
words = [word.lower() for word in words]
# 去除停用词
words = [word for word in words if word not in stop_words]
# 词形还原
lemmatized_words = [lemmatizer.lemmatize(word) for word in words]
return lemmatized_words
preprocessed_text = preprocess(cleaned_text)
print(preprocessed_text)
```
通过本章节的介绍,我们了解了Python环境的搭建方法、核心NLP库的安装以及如何对文本数据进行基本处理和预处理。接下来的章节将深入探讨文本预处理和分析的具体技巧和方法。
# 3. 文本预处理和分析
## 3.1 文本清洗与规范化
### 3.1.1 去除噪声和无关字符
在处理自然语言文本时,噪声和无关字符的去除是首要步骤。这些噪声包括非文字的标点符号、网页格式标记、特殊符号等。它们可能会干扰对文本的后续分析。在Python中,我们可以利用正则表达式库`re`来处理这些任务。
下面是一个简单的代码示例,展示了如何使用正则表达式去除文本中的噪声字符。
```python
import re
def remove_noise(text):
# 定义需要移除的噪声字符集合
noise = r'[^\w\s]'
return re.sub(noise, '', text)
# 示例文本
text = "这是一段包含#特殊符号和_下划线的文本,以及...省略号。"
# 去噪操作
clean_text = remove_noise(text)
print(clean_text)
```
在上述代码中,`re.sub`函数用于替换所有匹配正则表达式的部分。这里,`[^\w\s]`表示匹配任何非单词字符(如标点符号等)和非空白字符。`re.sub(noise, '', text)`将所有匹配到的噪声字符替换为空字符串,即删除它们。
### 3.1.2 分词和词性标注
文本清洗之后,接下来的步骤是分词(Tokenization)和词性标注(POS Tagging)。分词是将文本分割成单独的词语,而词性标注则是为每个词语赋予一个词性标记,如名词、动词等。
这里,我们可以使用NLTK库来完成这项工作。首先,需要下载NLTK中的Punkt tokenizer模型,该模型可以自动识别文本中的句子和词汇边界。
```python
import nltk
# 下载NLTK的Punkt tokenizer模型
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk import pos_tag
# 示例文本
text = "Natural language processing (NLP) is a field of computer science, artificial intelligence, and linguistics concerned with the interactions between computers and human (natural) languages."
# 分词
tokens = word_tokenize(text)
print(tokens)
# 词性标注
tagged_tokens = pos_tag(tokens)
print(tagged_tokens)
```
在这个例子中,`word_tokenize`函数将文本分割成单词标记,而`pos_tag`函数则对这些标记进行词性标注。输出的`tagged_tokens`是一个包含单词和对应词性标记的元组列表,例如('Natural', 'JJ')表示单词'Natural'是一个形容词(Adjective)。
## 3.2 基于统计的文本分析
### 3.2.1 词频统计和频率分布
文本分析的一个基础方法是统计词频,即计算一个词在文本中出现的次数。这可以通过Python的字典来实现。下面是一个简单的词频统计函数的实现:
```python
from collections import Counter
def calculate_word_frequency(tokens):
return Counter(tokens)
# 使用之前分词得到的tokens列表
word_freq = calculate_word_frequency(tokens)
print(word_freq)
```
`Counter`类非常适合用于统计频率。它会返回一个字典,其中键是单词,值是该单词出现的次数。这有助于我们了解文本中最常见的单词,从而可以进一步进行词频分布分析。
为了展示词频分布,我们可以绘制一个词频直方图。虽然无法在纯Markdown中展示图形,但是这里提供一个假设的代码示例,展示如何使用matplotlib来实现。
```python
import matplotlib.pyplot as plt
# 假设word_freq已经通过之前的函数计算得到
words, frequencies = zip(*word_freq.items())
# 绘制词频分布直方图
plt.figure(figsize=(10, 5))
plt.bar(words, frequencies)
plt.xlabel('Words')
plt.ylabel('Frequency')
plt.xticks(rotation=90)
plt.show()
```
通过绘制直方图,我们可以直观地看到哪些词是文本中出现频率最高的。
### 3.2.2 共现分析和关联规则挖掘
在自然语言处理中,共现分析(Co-occurrence Analysis)是了解词语之间关系的一种常用方法。这涉及到分析词语在文本中同时出现的频率。关联规则挖掘(Association Rule Mining)用于找出文本数据集中项之间的有趣关系,这在文本分析中,可以用于寻找词对之间的关联性。
接下来的代码段将使用一个简化的词共现矩阵来演示如何实现这一分析。
```python
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
# 示例文本数据集
texts = [
"Natural language processing is fascinating",
"Language processing uses algorithms",
"Algorithms analyze natural language data",
]
# 将文本转换为词向量矩阵
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
word_matrix = X.toarray()
# 生成共现矩阵
co_occurrence_matrix = np.dot(word_matrix.T, word_matrix)
print(co_occurrence_matrix)
# 这里只展示了一个小的文本数据集,实际应用中需要一个较大的数据集。
```
在这个代码段中,`CountVectorizer`用于将文本转换为词频矩阵,然后计算词的共现矩阵。这个共现矩阵可以用来进一步分析词汇之间的关系。
在实际应用中,我们可以使用共现矩阵来寻找高度相关的词汇对。例如,我们可以通过观察矩阵中的值来找出经常一起出现的词汇。这有助于我们理解文本中的主题和概念之间的联系。
## 3.3 语言模型和文本生成
### 3.3.1 构建基础语言模型
语言模型是NLP的一个核心概念,它用于估计一个句子的自然度或概率。基础语言模型包括N元语法(n-gram)模型,其中n-gram是文本中连续的n个项(如单词或字符)的序列。
下面展示了如何利用n-gram模型来构建一个简单的语言模型。
```python
from nltk.util import ngrams
from nltk import FreqDist
# 给定分词后的句子列表
sentences = [
'Natural language processing is fascinating',
'Language processing uses algorithms',
'Algorithms analyze natural language data'
]
# 创建bigrams(2-grams)
bigrams = ngrams(sentences, 2)
# 计算bigrams频率
bigram_freq = FreqDist(bigrams)
print(bigram_freq)
```
上述代码使用`ngrams`函数创建bigrams,并使用`FreqDist`来计算每个bigram的出现频率。该语言模型可以用于生成新句子或评估句子的流畅度。
### 3.3.2 文本生成的实践应用
基于已有的语言模型,可以实现简单的文本生成。下面的示例展示了如何使用n-gram模型来生成文本。
```python
# 生成文本函数
def generate_text(model, prompt):
generated = [prompt]
while len(generated[-1]) < 15:
word = model.most_common(1)[0][0][1]
next_word = generated[-1][-2:] + ' ' + word
generated.append(next_word)
return ' '.join(generated[1:])
# 以“自然语言”作为提示词
generated_text = generate_text(bigram_freq, "自然语言")
print(generated_text)
```
在这个例子中,我们使用`most_common`方法来查找最有可能的下一个词,并将其添加到生成的文本中。这个过程会持续到达到预设的长度限制。需要注意的是,生成的文本可能在语法或语义上并不总是有意义,但这是一个基础的文本生成实践应用。
以上代码和分析仅展示了文本生成的一个非常简单的例子,真正的文本生成任务,特别是需要高度语法和语义准确性的场合,一般会采用更为复杂的深度学习模型,如循环神经网络(RNN)或变换器模型(Transformer)。
通过本章节的介绍,我们了解了如何进行文本的预处理和基本分析,以及构建基础语言模型来生成文本。这些技能构成了自然语言处理领域的基础。在下一章节中,我们将探索更高级的NLP技巧,例如深度学习的应用、实体识别、情感分析等,来进一步提高我们的文本处理能力。
# 4. 高级自然语言处理技巧
### 4.1 深度学习在NLP中的应用
#### 4.1.1 理解神经网络和自然语言处理
深度学习在自然语言处理(NLP)领域中扮演着至关重要的角色,其核心思想是利用多层的神经网络来学习数据表示。这些表示能够捕捉到数据中的复杂结构和抽象概念,使得机器可以理解和生成人类语言。
神经网络通过其隐藏层,可以逐渐抽象输入数据,形成复杂的非线性映射。在NLP中,这种能力允许模型学习到单词、短语乃至句子中的深层语义。
使用深度学习处理自然语言通常涉及以下步骤:
- **数据预处理:** 将文本数据转换成模型可以理解的形式,如词嵌入(word embeddings)。
- **模型设计:** 选择合适的网络架构,例如循环神经网络(RNN)、长短期记忆网络(LSTM)或Transformer。
- **训练过程:** 使用大量文本数据来训练模型,不断优化模型参数以最小化预测误差。
- **评估与调优:** 对模型性能进行评估,并根据需要调整模型结构或参数。
#### 4.1.2 使用TensorFlow和PyTorch构建NLP模型
TensorFlow和PyTorch是目前最流行的两个深度学习框架,它们在NLP领域有着广泛的应用。这两个框架都提供了丰富的API和工具,使得构建NLP模型变得简单高效。
##### TensorFlow
TensorFlow是由Google开发的一个开源的机器学习库。它适用于从实验研究到大规模生产部署的各个阶段。TensorFlow使用数据流图来表示计算任务,使得它在分布式计算和优化方面表现出色。
```python
import tensorflow as tf
# 创建一个简单的TensorFlow模型
x = tf.constant([[1.0, 2.0], [3.0, 4.0]])
y = tf.constant([[5.0, 6.0], [7.0, 8.0]])
# 将两个常量相加
result = tf.add(x, y)
# 运行计算图,获取结果
with tf.Session() as sess:
print(sess.run(result))
```
在构建NLP模型时,我们可以使用TensorFlow中的高级API,如`tf.keras`来简化模型定义和训练流程。
##### PyTorch
PyTorch是由Facebook的人工智能研究团队开发的一个开源机器学习库。PyTorch强调动态计算图的灵活性,使得它在研究领域尤为受欢迎。
```python
import torch
# 创建一个简单的PyTorch模型
x = torch.tensor([[1.0, 2.0], [3.0, 4.0]], requires_grad=True)
y = torch.tensor([[5.0, 6.0], [7.0, 8.0]], requires_grad=True)
# 将两个张量相加
result = x + y
# 进行反向传播
result.sum().backward()
# 打印梯度
print(x.grad)
```
PyTorch的易用性和灵活性让其成为很多深度学习研究者的首选。通过使用PyTorch,可以更直观地构建复杂的神经网络架构,同时进行高效的计算和自动梯度计算。
在深度学习的NLP应用中,无论是使用TensorFlow还是PyTorch,关键是掌握如何构建和训练有效的模型。这包括选择合适的网络结构、调整超参数、正则化策略、优化算法等。深度学习的NLP模型已经在诸如语言翻译、情感分析、问答系统等多个领域取得了突破性的进展。
### 4.2 实体识别和关系抽取
#### 4.2.1 实体识别的原理与技术
实体识别(Named Entity Recognition, NER)是NLP中的一个基础任务,旨在从文本中识别出具有特定意义的实体,例如人名、地名、机构名和其他专有名词。
在技术实现上,实体识别通常采用序列标注的方法。这意味着我们需要给句子中的每个词标注上它所属的实体类型,如“B-PER”(开始的人名),“I-PER”(中间的人名)等。
##### 使用BiLSTM-CRF模型进行NER
近年来,基于BiLSTM(双向长短期记忆网络)结合条件随机场(CRF)的模型,在NER任务上表现尤为出色。CRF层负责序列标注的约束,比如保证同一个实体的标签是连贯的。
```python
import torch
import torch.nn as nn
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim):
super(BiLSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.tag_to_ix = tag_to_ix
self.tagset_size = len(tag_to_ix)
self.word_embeds = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2,
num_layers=1, bidirectional=True)
# Maps the output of the LSTM into tag space.
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)
# CRF layer
self.crf = CRF(self.tagset_size)
def forward(self, sentence):
# Get the emission scores from the BiLSTM
embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)
lstm_out, _ = self.lstm(embeds)
lstm_out = lstm_out.view(len(sentence), self.hidden_dim)
lstm_feats = self.hidden2tag(lstm_out)
# Find the best path, given the features.
score, tag_seq = self.crf(lstm_feats)
return score, tag_seq
# 示例:构建模型并进行前向传播
model = BiLSTM_CRF(len(vocab), tag_to_ix, embedding_dim=32, hidden_dim=64)
scores, tag_sequence = model(sentence)
```
NER模型的训练通常涉及大量带有实体标签的标注数据。模型通过监督学习的方式,学习如何识别和分类文本中的实体。
#### 4.2.2 关系抽取方法及应用
关系抽取(Relation Extraction, RE)是从非结构化的文本中识别实体之间的语义关系,例如确定两个人物间是否存在“工作于”、“毕业于”等关系。
关系抽取方法通常分为两种:基于模式的方法和基于监督学习的方法。
- **基于模式的方法**依赖于预定义的规则或模式来抽取关系,这种方法在特定领域内能够快速取得不错的效果。
- **基于监督学习的方法**则需要大量的标注数据,并通过机器学习模型来预测实体间的关系类型。深度学习模型由于能够捕捉到复杂的数据特征,因此在RE任务上越来越受欢迎。
```python
# 假设我们已经得到了实体和它们的类型
entities = [(0, 'PER', 'Alice'), (1, 'ORG', 'Google')]
relations = [(0, 1, 'WORKS_FOR')]
# 训练模型识别关系
# 这里的模型可以是任何适合关系抽取的深度学习模型
model = train RelationExtractionModel(entities, relations)
```
在实际应用中,关系抽取用于增强知识图谱、构建复杂的问答系统,甚至用于信息检索和推荐系统中。关系抽取可以将孤立的实体链接起来,形成结构化信息,为各种NLP应用提供丰富的语义背景。
### 4.3 情感分析和文本分类
#### 4.3.1 情感分析的技术和实现
情感分析(Sentiment Analysis)是自然语言处理中的另一项重要技术。它旨在通过分析文本(如评论、推文等)来确定作者的情感倾向,通常分为正面、负面和中立。
深度学习方法,特别是卷积神经网络(CNN)和循环神经网络(RNN),在情感分析任务上表现出了极佳的性能。
```python
import torch.nn as nn
class SentimentCNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim, dropout):
super(SentimentCNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.convs = nn.ModuleList([
nn.Conv2d(in_channels=1,
out_channels=n_filters,
kernel_size=(fs, embedding_dim))
for fs in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
# text = [sent len, batch size]
text = text.permute(1, 0)
# text = [batch size, sent len]
embedded = self.embedding(text)
# embedded = [batch size, sent len, emb dim]
embedded = embedded.unsqueeze(1)
# embedded = [batch size, 1, sent len, emb dim]
conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs]
# conv_n = [batch size, n_filters, sent len - filter_sizes[n] + 1]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
# pooled_n = [batch size, n_filters]
cat = self.dropout(torch.cat(pooled, dim=1))
# cat = [batch size, n_filters * len(filter_sizes)]
return self.fc(cat)
# 创建模型实例并进行前向传播
model = SentimentCNN(vocab_size, embedding_dim=100, n_filters=100, filter_sizes=[3,4,5], output_dim=1, dropout=0.5)
output = model(text)
```
情感分析的实现依赖于大量标注数据,这些数据帮助模型区分不同的情感倾向。训练好的模型可以应用于社交媒体监控、市场研究、产品反馈分析等多个领域,从而辅助决策制定。
#### 4.3.2 构建有效的文本分类系统
文本分类是NLP中的一个基本任务,目的是将文本划分到一个或多个预定义的类别中。除了情感分析外,文本分类还可以用于新闻文章的分类、垃圾邮件检测、主题识别等。
在构建有效的文本分类系统时,考虑以下步骤:
- **数据预处理:** 清洗数据、去除停用词、进行词干提取或词形还原、文本向量化。
- **特征提取:** 使用词袋模型、TF-IDF或词嵌入等方法。
- **模型选择与训练:** 选择合适的机器学习或深度学习模型,并进行训练。
- **模型评估与优化:** 评估模型的性能,使用交叉验证、超参数调整等技术来优化模型。
```python
# 使用sklearn构建一个简单的文本分类器
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
# 创建一个TF-IDF向量化器和朴素贝叶斯分类器的管道
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
# 假设x_train是训练文本数据,y_train是对应的标签
model.fit(x_train, y_train)
# 使用训练好的模型进行预测
predictions = model.predict(x_test)
```
文本分类系统的质量直接影响着NLP应用的性能。一个有效的文本分类系统可以快速准确地对大量文本数据进行分类,满足各种应用场景的需要。
# 5. 自然语言处理项目实战
## 5.1 构建聊天机器人
聊天机器人是NLP的一个典型应用,它可以模仿人类的交流方式,通过自然语言处理和理解用户的指令或问题,并做出响应。构建聊天机器人需要了解其基础架构,这通常包括输入处理、对话管理、知识库和响应生成等部分。
### 5.1.1 了解聊天机器人架构
在深入聊天机器人的技术细节前,首先要了解其基本的架构。一个标准的聊天机器人框架包括以下几个核心组件:
- **输入处理**:首先,需要对用户的输入进行处理。这通常意味着将其转化为某种可以被程序理解的格式。例如,将口语转化为文本,或对用户输入的文本进行分词。
- **意图识别**:通过分析用户输入的语句,聊天机器人需要识别用户的意图。例如,用户说“我想预订一个酒店”,聊天机器人需要识别出用户的意图是“预订”。
- **实体抽取**:识别出用户的意图后,下一步是抽取相关实体。在上面的例子中,需要抽取的实体可能包括“酒店”和“预订”的详细信息,如日期、地点等。
- **对话管理**:对话管理组件负责跟踪对话的状态,并决定如何回答用户。它需要决定什么时候请求更多信息,以及如何在对话过程中维持连贯性。
- **响应生成**:根据对话管理的决策,响应生成模块负责生成用户理解的自然语言回复。这个回复可以是一个预先设定的模板,也可以是通过一些复杂的语言模型生成的。
### 5.1.2 实现一个基本的聊天机器人
为了实现一个基础的聊天机器人,我们可以使用Python和一些流行的NLP库。以下是一个简单的聊天机器人实现的步骤:
1. **设置开发环境**:确保安装了Python环境和必要的NLP库,如`nltk`、`spaCy`、`chatterbot`等。
2. **导入库和定义变量**:
```python
from chatterbot import ChatBot
from chatterbot.trainers import ChatterBotCorpusTrainer
chatbot = ChatBot('ExampleBot') # 创建一个聊天机器人实例
```
3. **训练聊天机器人**:
```python
trainer = ChatterBotCorpusTrainer(chatbot) # 使用基于语料库的训练器
trainer.train('chatterbot.corpus.english') # 训练机器人使用英文语料库
```
4. **创建对话管理循环**:
```python
while True:
try:
user_input = input("You: ") # 获取用户输入
if user_input.lower() == 'quit': # 如果用户输入'quit',则退出程序
break
bot_response = chatbot.get_response(user_input) # 获取机器人的回复
print(f"Bot: {bot_response}")
except (KeyboardInterrupt, EOFError, SystemExit):
break
```
这是一个非常基础的聊天机器人,它使用了`chatterbot`库来提供预先训练好的对话能力。用户可以与机器人进行简单的对话,直到输入'quit'退出。对于更复杂的需求,可能需要自定义训练数据,或者实现更高级的意图识别和实体抽取逻辑。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 在自然语言处理 (NLP) 领域的广泛应用。从社交媒体情感分析到主题建模、自然语言生成、机器翻译、知识图谱构建、语音识别和文本聚类,该专栏提供了深入的教程和实践指南,帮助读者掌握 NLP 的关键技术。专栏还涵盖了大规模文本处理技术,包括文本清洗和预处理,以确保数据质量和效率。通过这些文章,读者将了解 Python 在 NLP 中的强大功能,并获得在现实世界项目中应用这些技术的实际技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
精通VW 80808-2 OCR错误诊断:快速解决问题的7种方法

参考资源链接:[Volkswagen标准VW 80808-2(OCR)2017:电子元件与装配技术详细指南](https://wenku.csdn.net/doc/3y3gykjr27?spm=1055.2635.3001.10343)
# 1. VW 80808-2 OCR错误诊断概述
在数字化时代,光学字符识别(
LIFBASE性能调优秘笈:9个步骤提升系统响应速度
参考资源链接:[LIFBASE帮助文件](https://wenku.csdn.net/doc/646da1b5543f844488d79f20?spm=1055.2635.3001.10343)
# 1. LIFBASE系统性能调优概述
在IT领域,随着技术的发展和业务需求的增长,系统性能调优逐渐成为保障业务连续性和用户满意度的关键环节。LIFBASE系统作为
【XILINX 7代XADC进阶手册】:深度剖析数据采集系统设计的7个关键点

参考资源链接:[Xilinx 7系列FPGA XADC模块详解与应用](https://wenku.csdn.net/doc/6412
OV426功耗管理指南:打造绿色计算的终极武器
参考资源链接:[OV426传感器详解:医疗影像前端解决方案](https://wenku.csdn.net/doc/61pvjv8si4?spm=1055.2635.3001.10343)
# 1. OV426功耗管理概述
在当今数字化时代,信息技术设备的普及导致了能源消耗的剧增。随着对节能减排的全球性重视,如何有效地管理电子设备的功耗成为了IT行业关注的焦点之一。特别是对于高性能计算设备和嵌入式系统,合理的功耗管理不仅能够降低能源消耗,还能延长设备的使用寿命,提高系统的稳定性和响应速度。OV426作为一款先进的处理器,其功耗管理能力直接影响到整个系统的性能与效率。接下来的章节中,我们将深入
深入探讨:银行储蓄系统中的交易并发控制
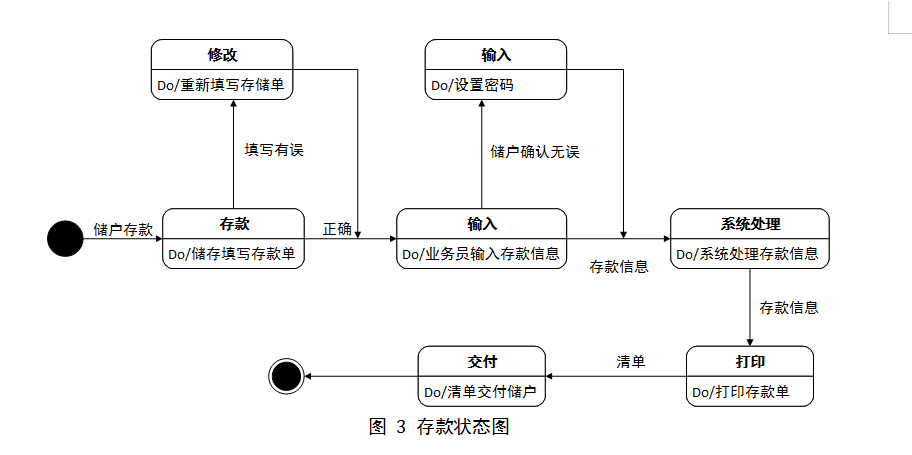
参考资源链接:[银行储蓄系统设计与实现:高效精准的银行业务管理](https://wenku.csdn.net/doc/75uujt5r53?spm=1055.2635.3001.10343)
# 1. 银行储蓄系统的并发问题概述
## 1.1 并发访问的必要性
在现代银行业务中,储蓄系统的并发处理是提高交易效率和用户体验的关键。随着在线交易量的增加,系统需要同时处理来自不同客户和分支机构的请求。并发访问确保了系统能够快速响应,但同时也带来了数
【HyperMesh材料属性至边界条件】:打造精准仿真模型的全路径指南

参考资源链接:[Hypermesh基础操作指南:重力与外力加载](https://wenku.csdn.net/doc/mm2ex8rjsv?spm=105
【热管理高手进阶】:Android平台下高通与MTK热功耗深入分析及优化
参考资源链接:[Android高通与MTK平台热管理详解:定制Thermal与架构解析](https://wenku.csdn.net/doc/6412b72dbe7fbd1778d495e3?spm=1055.2635.3001.10343)
# 1. Android热管理基础与挑战
在当今的移动设备领域,Andr
【DS-K1T673误识率克星】:揭秘误差分析及改善策略

参考资源链接:[海康威视DS-K1T673系列人脸识别终端用户指南](https://wenku.csdn.net/doc/5swruw1zpd?spm=1055.2635.3001.10343)
# 1. 误差分析与改善策略的重要性
## 1.1 误差在IT领域的普遍性
在IT行业,数据和系统准确性至关重要。误差,无论是人为的还是技术上的,都可能导致重大的问题,如系统故障、数据失真和决策
【PADS Layout专家速成】:7步掌握覆铜技术,优化电路板设计
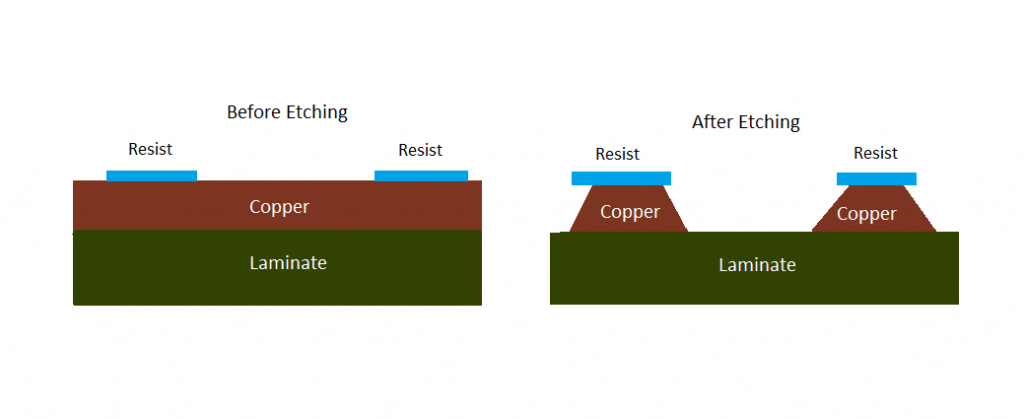
参考资源链接:[PADS LAYOUT 覆铜操作详解:从边框到填充](https://wenku.csdn.net/doc/69kdntug90?spm=1055.2635.3001.10343)
# 1. 覆铜技术概述
在现代电子设计制造中,覆铜技术是构建电路板核心的一环,它不仅涉及基础的电气连接,还包括了信号完整性、热管理以及结构稳定性等多方面考量
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )