数据预处理与特征提取:PyTorch深度分析与实战演练
发布时间: 2024-12-11 11:28:10 阅读量: 7 订阅数: 11 

onvifV2.0的文档, 中文版本
# 1. 数据预处理与特征提取的重要性
在机器学习和深度学习的实践中,数据预处理与特征提取是至关重要的步骤,它们直接影响到模型的性能和最终结果。数据预处理是整理和清洗原始数据的过程,目的是提高数据质量,为模型训练创造良好的数据基础。而特征提取则是从预处理后的数据中提取重要信息,转化成模型可以理解和利用的格式。
良好的数据预处理可以确保数据的准确性和一致性,消除异常值,以及处理缺失值,而有效的特征提取能够将原始数据中的有用信息凸显出来,帮助模型捕捉到数据的潜在模式和规律。这些步骤在一定程度上决定了模型能否成功学习数据的分布,并进行准确预测。
因此,本章将深入探讨数据预处理与特征提取的重要性,为后续章节中PyTorch框架的具体应用打下坚实的理论基础。
# 2. PyTorch框架基础
## 2.1 PyTorch安装与环境配置
### 2.1.1 PyTorch安装步骤
在深度学习的世界里,PyTorch是一个非常流行的开源机器学习库。它广泛应用于计算机视觉和自然语言处理等领域。在进行安装PyTorch之前,需要确保系统的环境符合要求,比如Python版本需要是Python 3.6或更高版本。
下面将介绍如何在Linux、Windows和MacOS操作系统上安装PyTorch。
**对于Linux用户:**
可以使用pip或者conda进行安装。以下是使用conda的命令,该命令会安装CPU版本的PyTorch,如果需要GPU版本,只需添加`pytorch torchvision torchaudio`后缀。
```bash
conda install pytorch torchvision torchaudio -c pytorch
```
**对于Windows用户:**
同样可以使用conda或pip。以下是使用pip的命令,建议通过虚拟环境进行安装,以免影响系统已有Python设置。同样地,添加`-f https://download.pytorch.org/whl/torch_stable.html`可以安装特定版本的PyTorch。
```bash
pip install torch torchvision torchaudio
```
**对于MacOS用户:**
对于MacOS用户,可以使用以下命令通过pip安装PyTorch。
```bash
pip3 install torch torchvision
```
在进行安装时,如果遇到权限问题,可以使用`sudo`命令,比如在Linux或MacOS上:
```bash
sudo pip3 install torch torchvision
```
安装完成后,可以通过Python执行以下命令来验证安装是否成功,并获取PyTorch的版本号。
```python
import torch
print(torch.__version__)
```
### 2.1.2 环境检查与配置要点
安装完成后,进行环境检查是十分必要的。这将确保PyTorch安装正确,并且可以正确地与硬件(如GPU)进行通信。以下是几个重要的环境检查步骤。
**检查PyTorch是否安装成功:**
执行上面提供的Python代码来验证PyTorch是否已正确安装。
**检查CUDA版本(如果是GPU版本):**
如果安装的是GPU版本,可以通过以下代码检查CUDA的版本。
```python
print(torch.cuda.is_available())
```
**验证GPU是否被正确使用:**
可以创建一个简单的张量,并尝试将其移动到GPU上,以检查是否能够正确进行操作。
```python
if torch.cuda.is_available():
device = torch.device("cuda")
x = torch.ones(5, device=device)
y = x + 2
print(y)
else:
print("CUDA is not available.")
```
**配置Jupyter Notebook:**
如果你计划使用Jupyter Notebook,可以通过以下命令来安装并验证。
```bash
pip install ipykernel
python -m ipykernel install --user --name=myenv --display-name="Python (myenv)"
```
然后在Jupyter中创建一个新的笔记本,并选择内核名称为"Myenv"。
进行这些检查是为了确保安装过程没有问题,并且PyTorch可以充分利用硬件资源。如果在检查过程中遇到问题,应该首先检查是否有网络问题导致安装中断,或者是操作系统不兼容的问题。
## 2.2 PyTorch基础操作
### 2.2.1 张量的基本操作
张量是PyTorch中最基本的数据结构,可以理解为一个多维数组,用于存储数值数据。PyTorch张量的操作非常直观,以下是一些基础操作的介绍。
**创建张量:**
可以通过`torch.tensor()`创建一个张量,也可以从numpy数组创建。
```python
import torch
# 从Python list创建
a = torch.tensor([1, 2, 3])
print(a)
# 从numpy数组创建
import numpy as np
b = torch.tensor(np.array([1, 2, 3]))
print(b)
```
**张量的数据类型:**
PyTorch支持多种数据类型,包括`torch.float32`, `torch.int64`, `torch.uint8`等。
```python
c = torch.tensor([1, 2, 3], dtype=torch.float32)
print(c)
```
**张量的基本操作:**
包括形状改变、索引、切片、拼接等。
```python
# 改变张量形状
d = torch.randn(2, 3)
d = d.view(3, 2)
print(d)
# 张量索引和切片
e = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(e[0, 1]) # 输出索引为[0, 1]的元素
print(e[:, 1]) # 输出第二列的所有元素
# 张量拼接
f = torch.cat((e, e), 0) # 沿着第一个轴拼接
print(f)
```
**数学运算:**
PyTorch支持丰富的数学运算,包括加减乘除、矩阵乘法等。
```python
# 逐元素运算
g = torch.randn(3, 3)
h = torch.randn(3, 3)
print(g + h)
print(torch.add(g, h))
# 矩阵乘法
i = torch.matmul(g, h.t()) # g与h的转置进行矩阵乘法
print(i)
```
**设备指定:**
你可以将张量指定到CPU或GPU上。
```python
if torch.cuda.is_available():
device = torch.device("cuda")
d = torch.ones(5, device=device)
print(d)
```
### 2.2.2 自动求导机制与优化器
自动求导机制是深度学习中非常重要的一个功能。PyTorch使用`torch.autograd`模块来实现自动求导。
**定义可求导的张量:**
使用`requires_grad=True`创建张量时,我们可以跟踪对张量的所有操作。
```python
x = torch.ones(2, 2, requires_grad=True)
print(x)
```
**进行操作并求导:**
对定义为可求导的张量进行操作后,通过调用`.backward()`可以自动计算梯度。
```python
y = (x + 2) * (x + 5)
y.backward()
print(x.grad) # 输出梯度
```
**优化器:**
优化器用于更新神经网络中的参数,以最小化损失函数。PyTorch提供了多种优化器,例如SGD和Adam。
```python
# 使用优化器
optimizer = torch.optim.SGD([x], lr=0.01)
optimizer.step() # 更新参数
print(x) # 输出更新后的x值
```
## 2.3 PyTorch中的数据加载与转换
### 2.3.1 Dataset与DataLoader的使用
为了高效地从硬盘加载数据到内存,PyTorch提供了`Dataset`类和`DataLoader`类。`Dataset`负责封装数据,而`DataLoader`负责管理数据的批处理、洗牌和多线程加载。
**自定义一个Dataset类:**
```python
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, data, target):
self.data = data
self.target = target
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.target[idx]
```
**使用DataLoader:**
```python
from torch.utils.data import DataLoader
# 假设有一个数据集和目标值
data = torch.randn(100, 2)
target = torch.randn(100)
custom_dataset = CustomDataset(data, target)
# 创建DataLoader
data_loader = DataLoader(dataset=custom_dataset, batch_size=10, shuffle=True)
# 遍历数据
for data, target in data_loader:
print(data.shape, target.shape)
# 在此处可以添加模型训练或验证代码
```
### 2.3.2 数据增强技术与方法
数据增强是一种增加数据集多样性的方式,常用于提升模型的泛化能力。
**使用`transforms`模块:**
PyTorch提供了一个`transforms`模块,可以方便地进行图像变换,从而实现数据增强。
```python
import torchvision.transforms as transforms
# 定义一系列变换操作
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.Resize((256, 256)),
transforms.ToTensor(),
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了使用 PyTorch 进行特征提取的方方面面。从入门秘籍到专家级指南,再到自定义模块和实战演练,它提供了全面的教程和见解。专栏还涵盖了数据预处理、卷积层特征提取、迁移学习、注意力机制等关键主题,并通过 ResNet 案例研究和 PyTorch 实战提供了实际应用。通过遵循这些技巧和最佳实践,读者可以掌握特征提取的艺术,并构建强大的深度学习模型。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
YOLOv8深度解读:如何实现高精度实时检测的终极指南

# 1. YOLOv8概述与核心原理
在计算机视觉领域,YOLOv8作为最新一代实时对象检测系统,继承了YOLO(You Only Look Once)系列模型的高效性与实用性。YOLOv8不仅在速度上保持了前代的快速响应,同时在检测精度上有了质的飞跃,使其在工
VSCode设置深度剖析:一文掌握用户与工作区设置的精髓
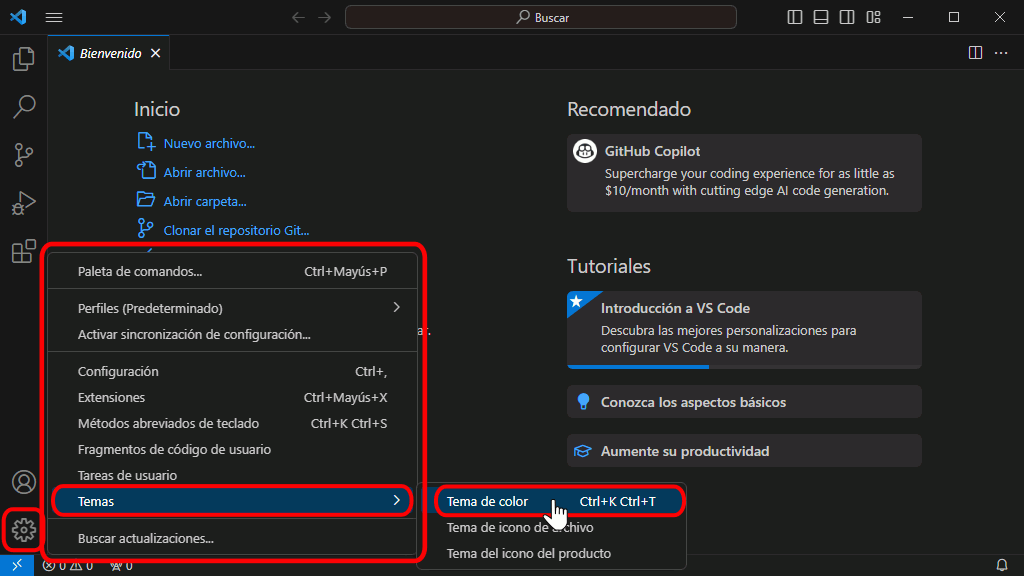
# 1. VSCode简介与设置概览
## 概述
Visual Studio Code,简称VSCode,是一个由微软开发的开源代码编辑器,支持多种编程语言,因其高性能、轻量级和丰富的扩展插件而广受欢迎。在现代软件开发中,VSCode的高效设置对提升工作效率至关重要。
## 核心功能
VSCode的核心功能包括代码高亮、智能补全、版本控制集成、调试工具和
Linux命令对比:locate与find,如何选择最佳搜索策略?

# 1. Linux文件搜索概述
Linux系统中的文件搜索工具是提升工作效率的关键组件。在众多命令中,`locate`和`find`是被广泛使用的两个命令,它们各有特色,适用场景也各有不同。本章将对Linux文件搜索进行概述,包括搜索工具的发展、常见的搜索方法以及它们在
【YOLOv8终极指南】:新一代目标检测技术的全面解析与实战演练
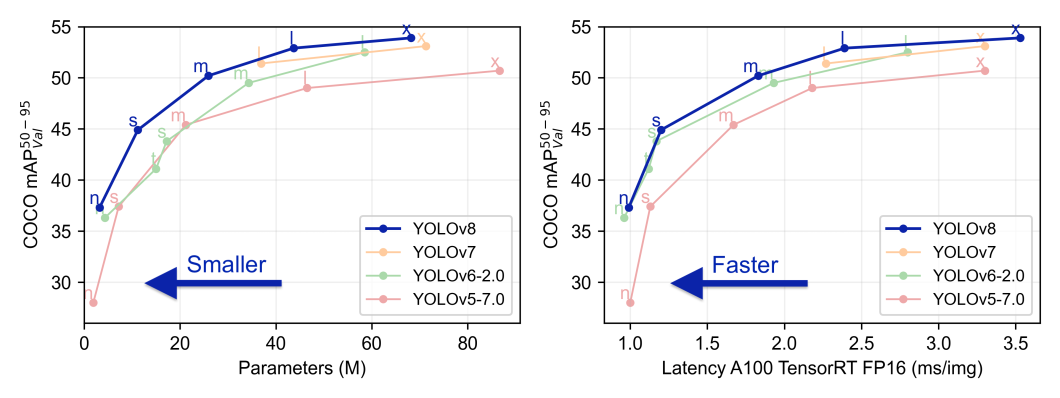
# 1. YOLOv8目标检测技术概述
YOLOv8,作为You Only Look Once系列的最新成员,代表了目标检测领域的一次重大进步。它继承了YOLO系列的实时性和准确性,并在模型设计和算法优化方面实现了跨越性的升级。在本章节中,我们将对YOLOv8进行基础性介绍,包括它的技术特性、应用场景以及它在工业界和研究界中的重要性。
## 1.1 YO
【PyTorch进阶技术】:自定义损失函数与优化策略详解
# 1. PyTorch框架基础
## 简介
PyTorch是一个广泛应用于深度学习领域的开源机器学习库,它以其灵活性和易用性著称。本章将介绍PyTorch的核心概念,为读者构建深度学习模型打下坚实的基础。我们将从PyTorch张量操作、自动梯度计算以及构建神经网络模块开始,逐步深入理解其工作机制。
## PyTorch张量操作
PyTorch中的基本数据结构是张量(Tensor),它类似于多维数组。张
Ubuntu进程管理终极指南:掌握命令、监控与优化
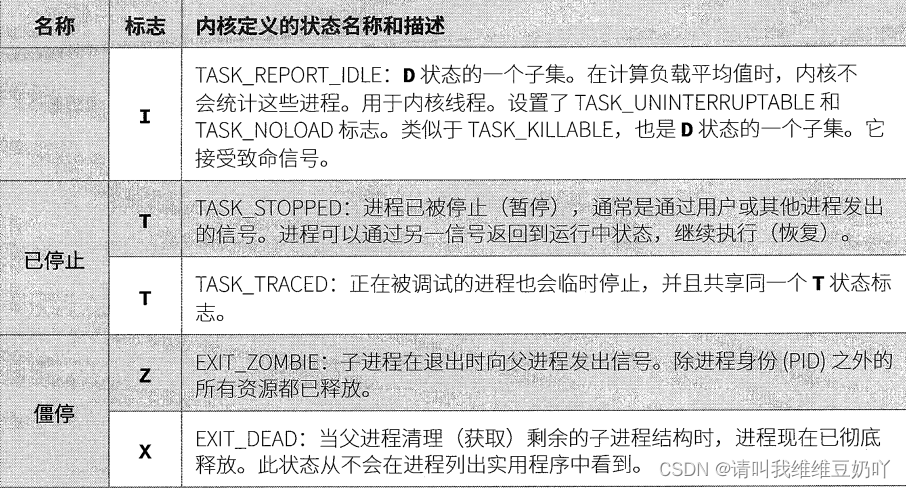
# 1. Ubuntu进程管理基础
在Linux系统中,进程是运行中的程序实例,管理进程是系统管理员必须掌握的关键技能之一。Ubuntu作为广泛使用的Linux发行版,在进程管理方面提供了丰富的工具和方法。本章将为读者介绍Ubuntu中进程管理的基本概念,包括进程的创建、运行、终止以及如何在系统资源有限的情况下合理分配和调度进程。随后,将深入探讨进程查看与管理工具,以及如何通过这些工具实现高效地进程控制和
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )