【企业级应用案例】:Anaconda模板在企业级项目中的应用与最佳实践
发布时间: 2024-12-09 15:12:54 阅读量: 11 订阅数: 17 

玉米病叶识别数据集,可识别褐斑,玉米锈病,玉米黑粉病,霜霉病,灰叶斑点,叶枯病等,使用voc对4924张照片进行标注

# 1. Anaconda模板概述
## 1.1 Anaconda的定义与功能
Anaconda是一个强大的Python发行版,专为数据科学、机器学习、和大规模数据处理而设计。它提供了Conda包管理器,用于安装、运行和升级包和依赖关系,同时简化了环境管理。Anaconda支持多版本Python并行运行,允许用户在不同项目间切换,而不会相互影响。
## 1.2 模板的重要性
在数据科学和机器学习项目中,环境配置复杂,依赖关系众多,模板可以快速搭建标准化工作环境。Anaconda模板预置了常见数据处理库和工具,大幅降低了新项目的启动难度,并提高了工作效率。
## 1.3 环境管理的挑战
数据科学项目常因环境配置错误导致重复问题,例如包版本不兼容、路径错误等。Anaconda模板通过隔离环境,确保了项目依赖的独立性和一致性,从而避免了这些问题的发生。
接下来章节将深入探讨Anaconda环境的配置与管理,以及如何在实际的数据科学和机器学习项目中有效利用这些模板,进而提升开发效率和模型质量。
# 2. Anaconda环境配置与管理
## 2.1 Anaconda基础环境搭建
### 2.1.1 安装Anaconda和conda工具
Anaconda是一个强大的Python发行版,它包含了丰富的科学计算相关的库。Anaconda的安装相对简单,但正确配置环境是利用其进行数据科学和机器学习项目的基础。首先,从Anaconda官网下载适合操作系统的安装包。安装过程中的关键点是确保添加Anaconda到系统的PATH环境变量中,这样conda命令就可以在任何命令行界面中使用。
安装后,打开命令行工具,输入以下命令来验证安装是否成功:
```bash
conda --version
```
如果系统能够返回conda的版本号,则表示安装成功。接下来,更新conda到最新版本:
```bash
conda update -n base -c defaults conda
```
执行上述命令后,conda会检查更新并提示用户是否继续。确认更新能够确保你使用的是最新版本的conda及其相关工具。
### 2.1.2 创建和管理conda环境
conda环境是隔离的Python执行环境,它允许用户为不同的项目安装不同版本的库。创建新环境使用以下命令:
```bash
conda create -n myenv python=3.8
```
这里`myenv`是环境的名称,`python=3.8`指定了Python版本。创建环境后,可以使用`activate`命令激活它:
```bash
conda activate myenv
```
激活环境后,所有安装的包都仅限于该环境,不会影响到系统中的其他Python项目。使用`conda list`命令可以查看当前环境中安装的包。若要退出环境,只需执行:
```bash
conda deactivate
```
创建环境只是第一步,管理环境同样重要。为了更好地控制环境,可以创建一个环境文件`environment.yml`,它描述了环境中应安装的包及其版本:
```yaml
name: myenv
channels:
-defaults
dependencies:
- python=3.8
- numpy
- pandas
```
使用`conda env export > environment.yml`命令可以导出现有环境的配置,之后可以通过`conda env create -f environment.yml`重新创建相同的环境。这样可以确保环境的一致性和可移植性,是合作开发和代码部署的常用方法。
## 2.2 Anaconda环境的版本控制与隔离
### 2.2.1 环境的备份和恢复
在长期项目中,可能会遇到需要备份整个conda环境的情况。这可以通过以下命令完成:
```bash
conda env export -n myenv > myenv_backup.yml
```
这个命令会将名为`myenv`的环境的所有依赖关系导出到`myenv_backup.yml`文件中。当需要在另一台机器或新的环境中恢复环境时,可以使用如下命令:
```bash
conda env create -f myenv_backup.yml
```
此方法的优点是简单易行,但缺点是可能会导出额外的包,特别是当使用的是默认的conda频道时。
### 2.2.2 环境的复制和迁移
除了备份和恢复外,有时候需要将环境从一个位置复制到另一个位置。可以使用`conda pack`工具来实现这一点:
```bash
conda install -c conda-forge conda-pack
conda-pack -n myenv -o myenv.tar.gz
```
上述命令会创建一个名为`myenv.tar.gz`的压缩包,里面包含了环境中的所有文件。然后,可以通过以下方式在新位置解压并激活环境:
```bash
mkdir -p new_env_location
tar -xzf myenv.tar.gz -C new_env_location
cd new_env_location/bin
./activate
```
这种方法保留了环境的完整性,适用于环境的迁移和分发。
## 2.3 高级环境管理技巧
### 2.3.1 环境变量和路径配置
在进行复杂的项目开发时,可能需要手动配置环境变量或修改系统路径。环境变量`PATH`是操作系统用来决定执行命令的搜索路径。在conda环境中,可以通过修改环境配置文件`activate.d`和`deactivate.d`脚本来改变环境变量。
例如,要向PATH添加一个自定义路径,可以创建一个`activate.d`脚本:
```bash
mkdir -p $CONDA_PREFIX/etc/conda/activate.d
echo 'export PATH="$PATH:/path/to/custom/bin"' > $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh
```
`deactivate.d`脚本的创建方式类似,这样可以在激活和停用环境时自动修改环境变量。
### 2.3.2 遇到的问题及解决方案
在使用conda环境管理时,可能会遇到各种问题,如包依赖冲突、权限问题等。对于依赖冲突,可以使用`conda list --revisions`来查看环境的历史变更,并使用`conda install --revision`来回退到稳定状态。如果遇到权限问题,可以尝试使用`--user`选项来安装包到用户目录,从而避免系统级别的写入权限问题。对于包安装不成功的情况,`conda search`可以查看某个包是否有可用的构建版本,并尝试使用不同版本或频道来解决问题。
# 3. Anaconda模板在数据科学项目中的应用
## 3.1 数据科学项目的准备工作
### 3.1.1 数据探索与预处理
数据科学项目的首要步骤是数据探索与预处理。这涉及到数据的收集、清洗和初步分析,以确保数据的质量和适用性。在这一过程中,Anaconda模板提供了诸多便利。
在数据探索阶段,使用Anaconda模板,数据科学家可以快速安装并使用如Pandas、NumPy等数据分析工具包。Pandas库提供了DataFrame这一数据结构,方便地对数据集进行读取、清洗和初步分析。NumPy则为数值计算提供了强大的支持,尤其是在处理大型数据集时。
以下是一个使用Pandas进行数据预处理的代码示例:
```python
import pandas as pd
# 加载数据集
df = pd.read_csv('data.csv')
# 查看数据集的前几行,了解数据结构
print(df.head())
# 数据清洗:删除缺失值
df.dropna(inplace=True)
# 数据预处理:类型转换
df['date'] = pd.to_datetime(df['date'])
# 数据探索性分析:统计分析
print(df.describe())
```
在上述代码中,首先导入了Pandas库,并加载了一个名为`data.csv`的数据文件。然后展示了数据集的前几行以供分析,并清理了数据集中的缺失值。最后进行了数据类型转换,并执行了简单的统计分析来获取数据的概览。
### 3.1.2 选择合适的Python包和库
在数据预处理完成后,下一步是选择合适的Python包和库进行数据分析和模型开发。Anaconda模板已经预装了大多数常用的科学计算包,如SciPy、Matplotlib等。此外,通过Anaconda的包管理器conda,可以方便地安装和管理额外需要的包。
以下是使用conda安装新包的示例代码:
```bash
conda install numpy matplotlib
```
这个命令会通过conda包管理器安装NumPy和Matplotlib这两个库。值得一提的是,conda会自动处理依赖关系和版本兼容性问题。
## 3.2 使用Anaconda模板进行模型开发
### 3.2.1 模型开发的流程
在选择了适当的工具后,数据科学家可以开始模型开发流程。这个流程通常包括定义问题、选择算法、训练模型和评估模型性能。Anaconda模板通过其丰富的科学计算包集合,允许用户无缝地在各个阶段之间切换。
在定义问题阶段,明确业务目标和目标变量是至关重要的。接下来,数据科学家会挑选合适的算法。例如,进行分类问题时可能会选择scikit-learn库中的决策树、支持向量机或随机森林等算法。
模型训练和验证阶段,Anaconda模板同样提供了方便的数据操作和模型评估工具。scikit-learn库中的`train_test_split`和`cross_val_score`函数可以用于分割数据集和交叉验证。
```python
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.ensemble import RandomForestClassifier
# 假设X为特征数据,y为标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 创建随机森林分类器实例
clf = RandomForestClassifier()
# 使用交叉验证评估模型
scores = cross_val_score(clf, X_train, y_train, cv=5)
print("Cross-validation scores:", scores)
```
在这段代码中,首先从scikit-learn中导入了`train_test

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Anaconda项目模板专栏是一份全面的指南,涵盖了使用Anaconda进行项目管理和开发的各个方面。它提供了从创建项目模板到使用Git进行版本控制的逐步指导。专栏还介绍了Anaconda环境管理的最佳实践,以及优化开发和部署流程的技巧。此外,它还探讨了Anaconda模板在大数据项目中的应用,以及提高性能的内存管理和加速技术。通过本专栏,读者可以掌握Anaconda的强大功能,从而简化项目管理、提高开发效率并优化机器学习项目框架。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
性能与安全并重:SQL Server 2016安装后优化与最佳实践

参考资源链接:[解决SQL Server 2016安装报错:需Oracle JRE7更新51(64位)](https://wenku.csdn.net/doc/6412b678be7fbd1778d46d71?spm=1055.2635.3001.10343)
# 1. SQL Server 2016概览与基础设置
##
MATLAB_Simulink 101:界面操作与功能速成全攻略
参考资源链接:[Simulink学习笔记:信号与电气线路的连接方法](https://wenku.csdn.net/doc/2ohgsorm55?spm=1055.2635.3001.10343)
# 1. MATLAB与Simulink概述
MATLAB与Simulink是MathWorks公司推出的用于数值计算、数据分析、算法开发和系统仿真的软件平台。它们共同为工程师和科研人员提供了从概念设
【System.img解包手册】:Windows用户必学的解包技巧与风险防范
参考资源链接:[Windows下轻松操作system.img:解包、修改与打包工具教程](https://wenku.csdn.net/doc/1fudqh8421?spm=1055.2635.3001.10343)
# 1. System.img文件概述与解包的重要性
## 1.1 System.img文件概述
在Android操作系统中,`System.img`是一个非常重要的镜像文件,它包含了
Origin脚本编写新手指南:自动化分析流程的10大实践技巧
参考资源链接:[Origin入门:数据求导详解及环境定制教程](https://wenku.csdn.net/doc/45o4pqn57q?spm=1055.2635.3001.10343)
# 1. Origin软件和脚本自动化基础
Origin是一个广泛用于科学数据分析和图形制作的专业软件,通过其内置的脚本语言,可以实现高度自动化和定制化的数据处理与分析。Origi
【定制化出入口管理】:海康威视PMS系统自定义设置完全攻略
参考资源链接:[海康威视出入口管理系统用户手册V3.2.0](https://wenku.csdn.net/doc/6401abb4cce7214c316e9327?spm=1055.2635.3001.10343)
# 1. 海康威视PMS系统概述
海康威视PMS系统(Perimeter Management System)是
【VMD进阶攻略】:分子建模与可视化技巧深度揭秘
参考资源链接:[VMD 1.8.3中文教程:从入门到高级应用](https://wenku.csdn.net/doc/84ybcs0675?spm=1055.2635.3001.10343)
# 1. VMD软件介绍与基础操作
## 1.1 VMD软件概述
VMD(Visual Molecular Dynamics)是一款专门为生物分子系统的可视化和分析设计的软件工具。它由伊利诺伊大学的生物分子设计研究所开发,广泛应
SICK DT35传感器故障快修手册:立解生产现场难题

参考资源链接:[SICK中距离传感器DT35的中文操作说明书](https://wenku.csdn.net/doc/6412b733be7fbd1778d49722?spm=1055.2635.3001.10343)
# 1. SICK DT35传感器故障诊
IEC62061合规性全攻略:检查清单与验证流程详解

参考资源链接:[IEC62061标准解读(中文)](https://wenku.csdn.net/doc/6412b591be7fbd1778d439e8?spm=1055.2635.3001.10343)
# 1. IEC62061标准概述
## 1.1 IEC62061标准的起源与应用
IEC62061标准是国际电工委员会(IEC)制定的一套关于安全相关电子控制系统的设计
MATPOWER高级仿真技术:动态仿真与控制策略的全面分析

参考资源链接:[MATPOWER中文指南:电力系统仿真与优化](https://wenku.csdn.net/doc/2fdsqb2j8i?spm=1055.2635.3001.10343)
# 1. MATPOWER简介及安装配置
## 1.1 MATPOWER的起
故障诊断不再难:三菱Q系列PLC MODBUS通信错误全面分析与处理
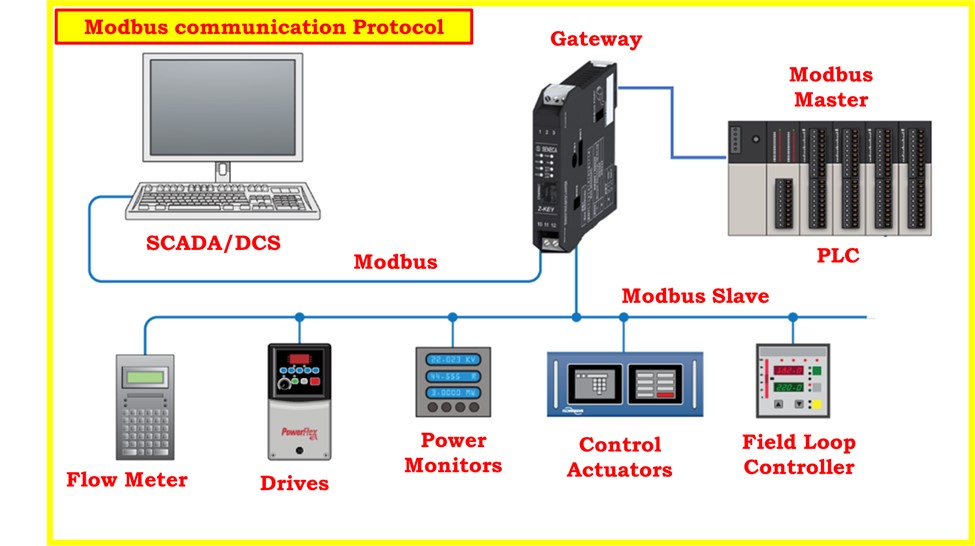
参考资源链接:[三菱Q01使用QJ71C24N MODBUS RTU通信实例详解](https://wenku.csdn.net/doc/6412b4dfbe7fbd1778d411fb?spm=1055.2635.3001.10343)
# 1. 三菱Q系列PLC与MODBUS通信概述
在现代工业自动化领域,PLC(可编程逻辑控制器)扮演着至关重要的角色。三菱Q系列PLC作为其中的佼佼者,其在自动化控制方面的灵活性和高效性赢得了广大工程师的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )