人工智能与大数据革命:数据驱动智能的未来展望
发布时间: 2024-12-13 16:11:09 阅读量: 5 订阅数: 9 

大数据人工智能的展望.pptx

参考资源链接:[人工智能发展史:定义、起源与里程碑事件](https://wenku.csdn.net/doc/pj3v0axqkp?spm=1055.2635.3001.10343)
# 1. 人工智能与大数据革命概述
## 1.1 概念与融合
人工智能(AI)和大数据是当今技术革新的两个热点,它们相互依赖、共同发展,共同推动了第四次工业革命的进程。AI技术能够处理和分析大量数据,而大数据的涌现又为AI提供了学习和演化的基础。我们可以将这种现象理解为“数据驱动的智能化”。
## 1.2 革命性影响
人工智能与大数据的结合,正在改变我们的工作、学习和生活方式。它们影响着各行各业,从医疗诊断到金融服务,从交通管理到零售推荐,智能化的解决方案正在帮助企业和组织提高效率、降低成本,并创造新的商业价值。
## 1.3 持续进化
这一章节将简要介绍AI和大数据如何相互作用,并为读者梳理它们的发展脉络。随着技术的不断进步,未来无论是AI技术本身还是其在大数据领域的应用都将继续深化,引发更为广泛和深远的社会变革。
# 2. 人工智能的理论基础
人工智能(Artificial Intelligence, AI)是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。自20世纪50年代诞生以来,AI已经历了多次寒冬和春天,如今,随着技术的飞速发展,AI再次站到了科技舞台的中心。
## 2.1 人工智能的历史和发展
### 2.1.1 人工智能的起源与早期发展
人工智能这一术语最早在1956年的达特茅斯会议(Dartmouth Conference)上被提出。这次会议聚集了当时计算机科学的先驱们,包括约翰·麦卡锡(John McCarthy)、马文·明斯基(Marvin Minsky)、纳撒尼尔·罗切斯特(Nathaniel Rochester)和克劳德·香农(Claude Shannon)等。他们对如何让机器模拟人类智能的各个方面进行了深入的探讨和交流。
在早期发展阶段,人工智能研究者们主要依赖于逻辑推理、搜索算法和形式化知识表示等方法。1966年,MIT的约瑟夫·维森鲍姆(Joseph Weizenbaum)开发了一个名为ELIZA的程序,这是一个模拟人类对话的自然语言处理系统。尽管ELIZA程序在今天看来非常简单,但它展示了人与机器之间进行交流的可能性,激发了公众对AI的广泛兴趣。
### 2.1.2 当代人工智能的突破与挑战
21世纪初,随着计算能力的提升、数据量的剧增以及算法的进步,人工智能迎来了新的春天。2012年,深度学习技术在ImageNet图像识别挑战赛中的出色表现标志着深度学习时代的开启。此后,人工智能在语音识别、图像处理、自然语言处理等领域取得了突破性进展。
然而,AI的发展也面临着挑战。数据隐私和安全问题成为公众和决策者的关注焦点,算法偏见和失控的自动化系统可能导致伦理和法律问题。AI技术在医疗、金融等敏感领域广泛应用的同时,也需要严谨的评估机制来保障技术的安全性和可靠性。
## 2.2 机器学习与深度学习
### 2.2.1 机器学习的基本原理
机器学习是人工智能的一个分支,它让计算机系统无需经过明确编程就能从数据中学习并做出决策或预测。机器学习的核心在于“学习”,即通过训练模型从历史数据中识别模式,从而对新数据做出准确的预测或决策。
机器学习的过程通常包括以下步骤:
1. 数据收集:获取包含信息的数据集。
2. 数据预处理:清洗数据,处理缺失值,进行特征工程等。
3. 模型选择:根据问题选择合适的机器学习算法。
4. 模型训练:使用训练数据集对模型进行训练。
5. 模型评估:使用验证集或测试集评估模型性能。
6. 模型部署:将训练好的模型部署到生产环境中。
### 2.2.2 深度学习的关键技术和算法
深度学习是机器学习中的一种,使用具有多个处理层的神经网络来学习数据的层次结构。深度学习模型,尤其是卷积神经网络(CNN)和循环神经网络(RNN),已经成为计算机视觉和自然语言处理等领域的关键技术。
关键的深度学习技术包括:
- 卷积神经网络(CNN):擅长图像和视频分析。
- 循环神经网络(RNN):适合处理序列数据,如文本和时间序列。
- 自编码器(Autoencoder):用于无监督学习,通过编码和解码过程学习数据的有效表示。
- 对抗生成网络(GAN):生成高度逼真的合成数据。
### 2.2.3 应用案例分析
机器学习和深度学习的应用覆盖了医疗、金融、安防等多个行业。以深度学习在医疗领域的应用为例,Google Health的深度学习模型能够预测患者心脏病发作的风险。通过分析患者的电子健康记录,该模型对患者的未来健康状况进行预测,从而帮助医生制定预防措施。
## 2.3 自然语言处理与计算机视觉
### 2.3.1 自然语言处理的核心概念
自然语言处理(Natural Language Processing, NLP)是机器学习和人工智能领域的一个子领域,它让计算机能够理解、解释和生成人类语言。NLP的核心目标是使计算机能够与人类进行自然交流,理解语言的含义和语境。
NLP的关键技术包括:
- 词性标注(Part-of-Speech Tagging):自动识别文本中每个单词的词性。
- 命名实体识别(Named Entity Recognition, NER):自动识别文本中的人名、地名、组织名等。
- 依存句法分析(Dependency Parsing):分析句子中单词之间的语法关系。
- 情感分析(Sentiment Analysis):分析文本所表达的情绪倾向。
### 2.3.2 计算机视觉的应用与技术进展
计算机视觉(Computer Vision, CV)研究如何使计算机“看见”并理解数字图像和视频中的内容。计算机视觉领域的研究为自动驾驶汽车、人脸识别、图像搜索等应用的发展奠定了基础。
计算机视觉的关键技术包括:
- 图像分类(Image Classification):识别和分类图像中的对象。
- 物体检测(Object Detection):在图像中识别并定位多个物体。
- 语义分割(Semantic Segmentation):将图像中的每个像素分配给一个特定的类别。
- 人脸识别(Face Recognition):从图像中识别人脸并进行匹配。
以上内容为第二章人工智能的理论基础的详细解读,后续内容将围绕大数据技术的理论与实践进行展开,探索数据驱动的智能应用,并展望未来AI与大数据的发展趋势及其带来的伦理、社会和经济影响。
# 3. 大数据技术的理论与实践
随着信息技术的快速发展,大数据技术已经成为推动现代社会进步的关键因素之一。从商业决策到科学研究,从城市管理到个人生活,大数据的应用无处不在。本章将深入探讨大数据的概念和特征,着重分析大数据存储与管理技术,以及大数据分析与挖掘的实践方法。
## 3.1 大数据的概念和特征
### 3.1.1 大数据定义及其五V特性
大数据(Big Data)是指那些传统数据处理软件无法有效处理的海量、复杂和多样化的数据集。这些数据集的规模庞大到传统数据库管理系统难以应对,因此需要采用新的数据处理工具和技术。大数据的特征通常被概括为五个方面:体量(Volume)、速度(Velocity)、多样性(Variety)、真实性(Veracity)和价值密度(Value)。
#### 体量(Volume)
体量指的是数据的大小。随着互联网技术的普及,每天都会产生数以亿计的交易记录、日志文件和社交媒体动态。例如,Facebook每天上传的照片超过3.5亿张,而Google每天处理的搜索查询高达数亿次。
#### 速度(Velocity)
速度是指数据产生的速度和处理的速度。在很多情况下,数据需要实时或者近实时的分析和处理,如金融市场交易、在线购物推荐系统等。
#### 多样性(Variety)
数据的多样性体现在数据来源和数据类型上。数据可以是结构化的(如数据库中的表格数据),也可以是非结构化的(如视频、音频、文本等)。
#### 真实性(Veracity)
真实性指的是数据的质量。在大数据的背景下,数据来源广泛,因此数据的准确性和可靠性往往存在很大差异。
#### 价值密度(Value)
尽管大数据体量巨大,但其中高价值信息的比例相对较低。因此,如何从大数据中提炼出有价值的信息是一个挑战。
### 3.1.2 大数据的生态系统和关键技术
大数据生态系统是由一系列相关技术组成,它们相互协作以实现数据的获取、存储、处理、分析和可视化。关键的技术包括数据采集、存储、管理和分析工具,如Hadoop、Spark、NoSQL数据库以及各种数据挖掘算法。
#### 数据采集
数据采集是大数据处理的第一步,常用的工具包括Flume、Kafka和Sqoop。例如,Flume是一个分布式、可靠且可用的服务,用于有效地聚合、汇集和移动大量日志数据。
#### 存储技术
存储技术中的Hadoop分布式文件系统(HDFS)提供了一个可靠、可扩展的数据存储解决方案,适用于大数据的存储需求。
#### 数据处理
大数据处理分为批处理和流处理两种方式。Apache Hadoop适合于批处理,而Apache Storm和Apache Spark则更擅长于流处理和实时分析

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 PPT 课件的形式,深入探讨了人工智能发展的历史。从图灵测试的诞生到深度学习的崛起,专栏涵盖了人工智能领域的重大里程碑和关键事件。专栏还探讨了人工智能在医疗、物联网、农业和大数据等领域的应用,揭示了人工智能如何塑造着我们的世界。通过深入分析早期项目、黄金时代和现代突破,专栏提供了对人工智能历史和未来发展趋势的全面理解。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据管理革命】:构建深度学习的高效、可扩展数据管道
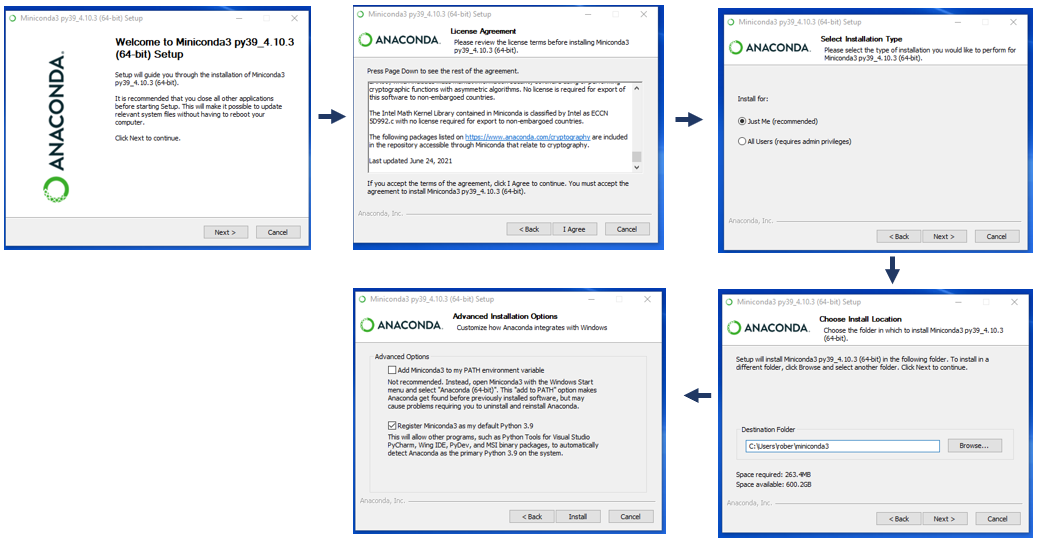
参考资源链接:[DBCLOUD Lab环境配置:从Anaconda安装到终端连接](https://wenku.csdn.net/doc/7sj58h50z2?spm=1055.2635.3001.10343)
# 1. 深度学习数据管道的概念和重要性
数据管道在深度学习项目中扮演着至关重要的角色。数据管道可以理解为一系列流程,它们将数据从源头提取
【Web组件封装】:打造跨平台的高性能只读Checkbox组件
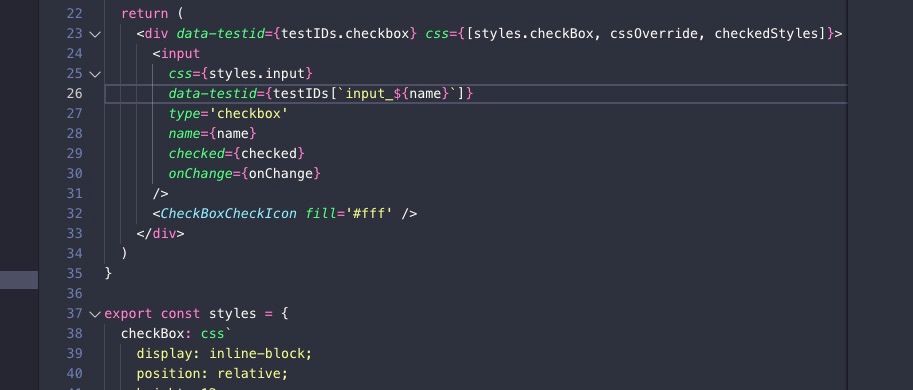
参考资源链接:[设置checkbox为只读(readOnly)的两种方式](https://wenku.csdn.net/doc/645203ebea0840391e738d60?spm=1055.2635.3001.10343)
# 1. Web组件封装概述
随着Web应用变得越来越复杂,组件化开发已经成为构建高效、可维护的前端项目的关键手段。Web组件封装是将可重用的代码单元打包成独立的
跨系统集成秘籍:泛微OA e-cology 8 WebService接口案例深度分析

参考资源链接:[泛微OA e-cology 8 文档与工作流Webservice接口详解](https://wenku.csdn.net/doc/6412b7a5be7fbd1778d4b0a9?spm=1055.2635.3001.10
OMNIC中文数据分析基础:解读数据报告的4个必知技巧

参考资源链接:[赛默飞世尔红外光谱软件OMNIC中文详细使用手册](https://wenku.csdn.net/doc/2m0117z
【Hi3516DV300驱动开发快速入门】:构建高效驱动程序的五大步骤

参考资源链接:[海思Hi3516dv300芯片功能与应用详解](http
【Python编程基础】:小白到入门者的5大进阶技巧
参考资源链接:[《Python编程:给孩子玩的趣味指南》高清PDF电子书](https://wenku.csdn.net/doc/646dae11d12cbe7ec3eb21ff?spm=1055.2635.3001.10343)
# 1. Python编程语言概述
Python 是一种高级编程语言,以其简洁明了的语法和强大的功能库而闻名。自1991年首次发布以来,Python 不断发展,成为数据科学、人工智能、网络开发和自动化等领域的首选语言。其语言设计哲学强调代码的可读性和简洁的语法(尤其是使用空格缩进划分代码块,而非大括号或关键字)。Python 支持多种编程范式,包括面向对象、命令式
【OpenGL与VTK融合】:打造高性能可视化应用的专业指南
参考资源链接:[VTK初学者指南:详细教程与实战项目](https://
【PDMS性能提升攻略】:12.0版本的系统响应与设计效率优化手册

参考资源链接:[PDMS 12.1基础教程:入门到3D模型操作](https://wenku.csdn.net/doc/386px5k6cw?spm=1055.2635.3001.10343)
# 1. PDMS系统概述及性能指标
## 系统概述
PDMS(Product Data Management System,产品数
ControlDesk在敏捷开发中的黄金法则:如何提升团队协作效率
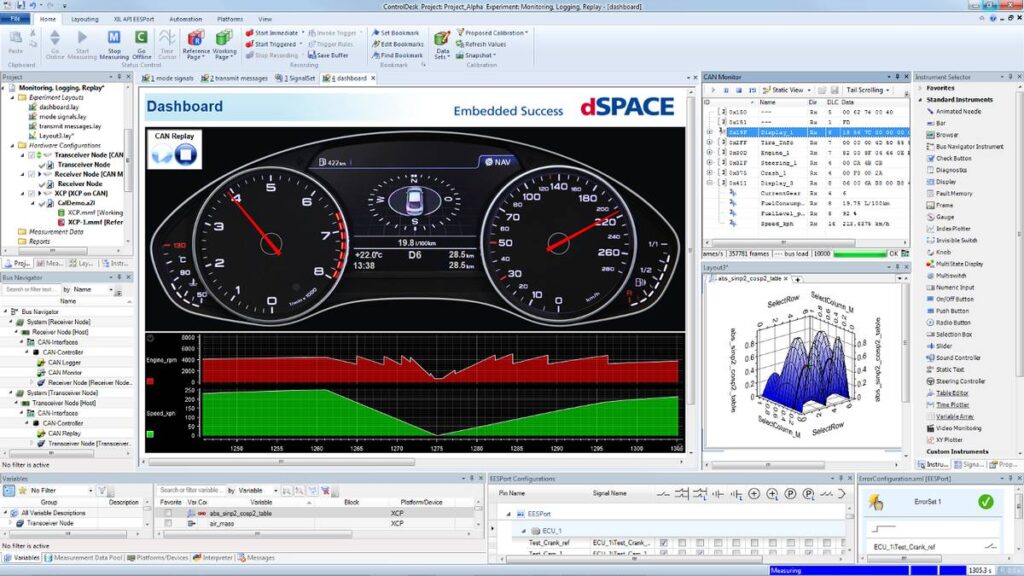
参考资源链接:[DSpace ControlDesk操作指南](https://wenku.csdn.net/doc/32y1v4mhv5?spm=1055.2635.3001.10343)
# 1. 敏捷开发与团队协作效率
## 概述
敏捷开发作为当今IT行业推崇的开发模式,强调快速响应变化和持续交付价值。它与传统开发方法相比,更注重团队协作和灵活性,从而在快速迭代和市场适应性上表现卓越
【硬盘盒固件更新进阶技巧】:深入探索JSM578的优化之道

参考资源链接:[JSM567/578硬盘盒固件升级与休眠时间调整教程](https://wenku.csdn.net/doc/3138xottoq?spm=1055.2635.3001.10343)
# 1. 硬盘盒固件更新概述
硬盘盒作为存储设备的重要组成部分,其固件更新是保障设备稳定运行与性能优化的关键步骤。固件更新不仅涉及到新功能的增加,还包括性能改
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )