VW 80808-2 OCR性能优化:提升文档解析效率的策略与案例分析
发布时间: 2024-12-15 01:36:51 阅读量: 1 订阅数: 3 

VW 80808-2 EN.pdf

参考资源链接:[Volkswagen标准VW 80808-2(OCR)2017:电子元件与装配技术详细指南](https://wenku.csdn.net/doc/3y3gykjr27?spm=1055.2635.3001.10343)
# 1. OCR技术与文档解析概述
OCR技术,即光学字符识别(Optical Character Recognition),它通过扫描等技术手段将印刷或手写文档中的文字转换成可编辑、可搜索的数字文本。文档解析则是指对文档内容进行结构化提取和理解的过程。
## 1.1 OCR技术的历史与演变
OCR技术的发展历史悠久,其应用可追溯到20世纪初。早期的OCR系统主要用于简单的字符识别,随着计算能力的提升和算法的改进,现代OCR技术已经能够处理多种格式的文档,并支持复杂的语言和版面解析。
## 1.2 OCR技术的应用领域
OCR技术广泛应用于银行、保险、医疗保健以及政府机构等领域,主要用于文档自动录入、存档管理和信息检索等场景。随着移动互联网的发展,手机应用中的文字识别也变得越发重要。
## 1.3 文档解析技术的重要性
文档解析不仅涉及文字识别,还包括对文档中表格、图片、图形等非文本元素的提取和理解,是现代信息处理不可或缺的一部分。随着大数据和人工智能技术的融合,文档解析技术的重要性正逐渐提升。
在接下来的章节中,我们将深入探讨VW 80808-2 OCR引擎的工作原理和性能指标,并提供提升性能的策略,最后通过案例分析其实际应用效果。
# 2. VW 80808-2 OCR引擎分析
### 2.1 VW 80808-2 OCR引擎工作原理
#### 2.1.1 文档图像预处理
在OCR(Optical Character Recognition,光学字符识别)技术的应用过程中,文档图像预处理是第一步,也是至关重要的一步。VW 80808-2 OCR引擎在这一环节上采用了多种图像处理技术以提高识别的准确性和效率。
预处理步骤通常包括:
- **二值化(Binarization)**: 将彩色或灰度图像转换为黑白两色,以简化后续处理过程。
- **去噪(Denoising)**: 使用滤波算法减少图像中的噪声,如高斯滤波、中值滤波等。
- **倾斜校正(Skew Correction)**: 对倾斜的文档进行校正,确保文字行与扫描线平行。
- **版面分割(Layout Segmentation)**: 把文档分割成单个区域,便于后续的识别操作。
以下是预处理流程的伪代码,展示了如何对图像进行二值化处理:
```python
import cv2
def binarize_image(image):
# Converting image to grayscale
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Applying Otsu's thresholding to get binary image
_, binary_image = cv2.threshold(gray_image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
return binary_image
# Example image path
image_path = 'path_to_image.jpg'
image = cv2.imread(image_path)
# Binarize the image
binary_image = binarize_image(image)
```
二值化处理后的图像更容易被后续的字符识别算法处理。
#### 2.1.2 文本区域定位
文本区域定位是OCR引擎的核心步骤之一,目标是准确找到图像中包含文本的区域。VW 80808-2引擎采用基于规则和机器学习的算法来识别和定位文本区域。
文本区域定位的算法通常包含以下步骤:
- **连通组件分析(Connected Component Analysis, CCA)**: 寻找图像中的连通组件,这些组件通常对应于文本字符。
- **文本行检测(Text Line Detection)**: 确定文本行的位置和方向。
- **区域重排序(Region Reordering)**: 对于文本块进行排序,以符合阅读顺序。
在Python代码中,可以使用OpenCV库来实现文本区域的定位:
```python
def detect_text_regions(image):
# Apply thresholding to obtain binary image
_, binary_image = cv2.threshold(image, 128, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# Find contours of the binary image
contours, _ = cv2.findContours(binary_image, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# Filter contours based on certain criteria such as size or aspect ratio
text_regions = []
for contour in contours:
# Calculate the bounding box of the contour
x, y, w, h = cv2.boundingRect(contour)
# Filter based on criteria
if width_to_height_ratio_is_valid(w, h):
text_regions.append((x, y, w, h))
return text_regions
# Detect text regions
text_regions = detect_text_regions(binary_image)
```
文本区域的准确定位对于OCR的准确率至关重要。
#### 2.1.3 字符识别与后处理
字符识别过程需要将预处理后图像中的文本区域中的字符转换为计算机编码。VW 80808-2 OCR引擎使用深度学习模型来识别字符,并采用后处理技术来提高识别的准确性。
后处理步骤包括:
- **字符分割**: 分离文本行中的单个字符。
- **分类器匹配**: 使用机器学习模型对分割后的字符进行分类识别。
- **置信度评估**: 对识别结果进行置信度评分,判断识别的可靠性。
后处理流程可以使用Python的示例代码来展示:
```python
import numpy as np
from someOCRlibrary import predict_character
def recognize_characters(text_regions, binary_image):
recognized_text = ""
for region in text_regions:
x, y, w, h = region
# Extract character ROI from the binary image
char_image = binary_image[y:y+h, x:x+w]
# Character recognition using OCR engine
char_prediction, confidence = predict_character(char_image)
# If confidence is high, add the character to the recognized text
if confidence > SOME_THRESHOLD:
recognized_text += char_prediction
return recognized_text
# Recognize characters in each region
final_text = recognize_characters(text_regions, binary_image)
```
经过后处理后,得到的文本准确性更高,更接近原版文档的内容。
### 2.2 VW 80808-2 OCR性能指标
#### 2.2.1 准确度
OCR系统的准确度通常以识别准确率来衡量,准确率越高代表OCR系统的性能越好。准确度的计算可以使用如下公式:
```
准确率 = (正确识别的字符数 / 总字符数) * 100%
```
为了测试VW 80808-2 OCR引擎的准确度,可以进行如下测试:
1. 准备一系列包含各种字体、大小、格式的测试文档。
2. 使用OCR引擎进行识别,并与原始文档对比。
3. 计算识别结果的准确率,并分析不同文档格式对准确率的影响。
准确度的优化包括但不限于:
- **训练数据优化**: 使用更多样化的数据训练模型。
- **模型改进**: 提升识别模型的准确率和泛化能力。
- **错误分析**: 对识别错误进行详细分析,针对性改进。
#### 2.2.2 速度与效率
OCR系统的速度和效率通常取决于文档图像的大小、复杂度以及识别算法的优化程度。速度可以通过识别一张图像所需的时间来衡量。
为了提升速度,VW 80808-2 OCR引擎可能采取以下措施:
- **算法优化**: 精简算法流程,减少不必要的计算。
- **硬件加速**: 使用GPU进行并行计算。
- **批量处理**: 对多张图像同时进行处理。
在实际应用中,可以记录不同情况下的处理时间,并进行对比:
```python
import t
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
性能与安全并重:SQL Server 2016安装后优化与最佳实践

参考资源链接:[解决SQL Server 2016安装报错:需Oracle JRE7更新51(64位)](https://wenku.csdn.net/doc/6412b678be7fbd1778d46d71?spm=1055.2635.3001.10343)
# 1. SQL Server 2016概览与基础设置
##
MATLAB_Simulink 101:界面操作与功能速成全攻略
参考资源链接:[Simulink学习笔记:信号与电气线路的连接方法](https://wenku.csdn.net/doc/2ohgsorm55?spm=1055.2635.3001.10343)
# 1. MATLAB与Simulink概述
MATLAB与Simulink是MathWorks公司推出的用于数值计算、数据分析、算法开发和系统仿真的软件平台。它们共同为工程师和科研人员提供了从概念设
【System.img解包手册】:Windows用户必学的解包技巧与风险防范
参考资源链接:[Windows下轻松操作system.img:解包、修改与打包工具教程](https://wenku.csdn.net/doc/1fudqh8421?spm=1055.2635.3001.10343)
# 1. System.img文件概述与解包的重要性
## 1.1 System.img文件概述
在Android操作系统中,`System.img`是一个非常重要的镜像文件,它包含了
Origin脚本编写新手指南:自动化分析流程的10大实践技巧
参考资源链接:[Origin入门:数据求导详解及环境定制教程](https://wenku.csdn.net/doc/45o4pqn57q?spm=1055.2635.3001.10343)
# 1. Origin软件和脚本自动化基础
Origin是一个广泛用于科学数据分析和图形制作的专业软件,通过其内置的脚本语言,可以实现高度自动化和定制化的数据处理与分析。Origi
【定制化出入口管理】:海康威视PMS系统自定义设置完全攻略
参考资源链接:[海康威视出入口管理系统用户手册V3.2.0](https://wenku.csdn.net/doc/6401abb4cce7214c316e9327?spm=1055.2635.3001.10343)
# 1. 海康威视PMS系统概述
海康威视PMS系统(Perimeter Management System)是
【VMD进阶攻略】:分子建模与可视化技巧深度揭秘
参考资源链接:[VMD 1.8.3中文教程:从入门到高级应用](https://wenku.csdn.net/doc/84ybcs0675?spm=1055.2635.3001.10343)
# 1. VMD软件介绍与基础操作
## 1.1 VMD软件概述
VMD(Visual Molecular Dynamics)是一款专门为生物分子系统的可视化和分析设计的软件工具。它由伊利诺伊大学的生物分子设计研究所开发,广泛应
SICK DT35传感器故障快修手册:立解生产现场难题

参考资源链接:[SICK中距离传感器DT35的中文操作说明书](https://wenku.csdn.net/doc/6412b733be7fbd1778d49722?spm=1055.2635.3001.10343)
# 1. SICK DT35传感器故障诊
IEC62061合规性全攻略:检查清单与验证流程详解

参考资源链接:[IEC62061标准解读(中文)](https://wenku.csdn.net/doc/6412b591be7fbd1778d439e8?spm=1055.2635.3001.10343)
# 1. IEC62061标准概述
## 1.1 IEC62061标准的起源与应用
IEC62061标准是国际电工委员会(IEC)制定的一套关于安全相关电子控制系统的设计
MATPOWER高级仿真技术:动态仿真与控制策略的全面分析

参考资源链接:[MATPOWER中文指南:电力系统仿真与优化](https://wenku.csdn.net/doc/2fdsqb2j8i?spm=1055.2635.3001.10343)
# 1. MATPOWER简介及安装配置
## 1.1 MATPOWER的起
故障诊断不再难:三菱Q系列PLC MODBUS通信错误全面分析与处理
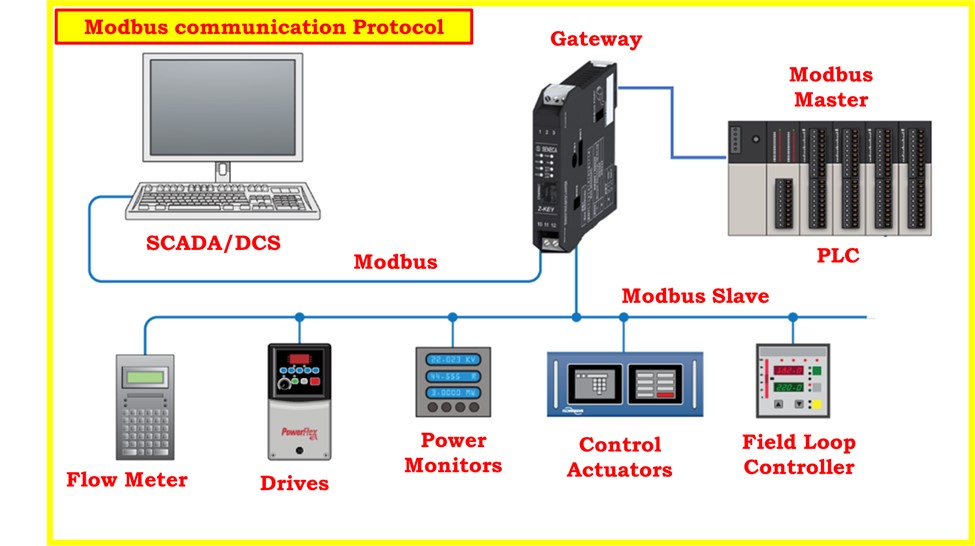
参考资源链接:[三菱Q01使用QJ71C24N MODBUS RTU通信实例详解](https://wenku.csdn.net/doc/6412b4dfbe7fbd1778d411fb?spm=1055.2635.3001.10343)
# 1. 三菱Q系列PLC与MODBUS通信概述
在现代工业自动化领域,PLC(可编程逻辑控制器)扮演着至关重要的角色。三菱Q系列PLC作为其中的佼佼者,其在自动化控制方面的灵活性和高效性赢得了广大工程师的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )