SQL语句重构的艺术:简化复杂查询的技巧,让代码更加优雅高效
发布时间: 2024-12-07 04:19:46 阅读量: 11 订阅数: 15 

sql.rar_SQL语句_hawk_sql优化
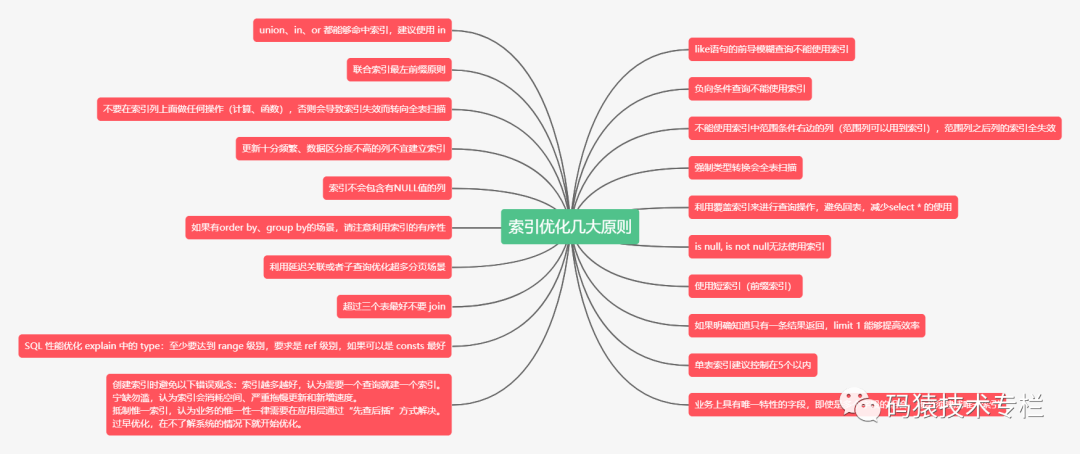
# 1. SQL语句重构的基础概念
SQL(Structured Query Language)是一种用于管理关系型数据库系统的标准编程语言。随着数据量的增长和技术的发展,我们经常需要重构旧的SQL语句来提升性能、增强可维护性或适应新的业务需求。**SQL语句重构** 是指在不改变SQL语句对外表现逻辑的情况下,对SQL语句的内部结构进行优化和调整,以提高性能、提高代码可读性和降低维护成本。
在本章中,我们将首先介绍SQL语句重构的基本概念,然后逐步深入探讨SQL语句的核心组成、重构原则、模块化和复用的技巧。我们将逐步展开讨论,以便读者可以按照由浅入深的方式理解SQL重构的完整过程。接下来,我们将进入核心内容的学习,为读者揭示SQL语句重构的逻辑和方法。
# 2. SQL语句的核心组成和重构原则
## 2.1 SQL语句的逻辑结构解析
### 2.1.1 SELECT子句的基本使用
SQL语句中的`SELECT`子句用于指定要从数据库中检索的数据。这一子句是构成SQL查询的基础,并能够使用各种函数和计算对返回的数据进行格式化。
**基本使用示例:**
```sql
SELECT column1, column2
FROM table_name;
```
在上述的SQL语句中,我们从`table_name`表中选择了`column1`和`column2`两个字段。这是最基本的查询形式,但`SELECT`子句可做得更多。
**进阶使用:**
1. **列选择和计算:** `SELECT`允许你进行基本的数学运算,如加、减、乘、除。
```sql
SELECT column1, column2 * 2
FROM table_name;
```
2. **字符串操作:** 可以使用SQL内置的字符串函数进行操作,如连接、替换等。
```sql
SELECT column1, CONCAT(column2, ' suffix')
FROM table_name;
```
3. **聚合函数:** `SELECT`可以使用聚合函数来对数据进行汇总,例如`COUNT`, `SUM`, `AVG`, `MAX`, `MIN`。
```sql
SELECT COUNT(column1) AS count
FROM table_name;
```
**参数说明:**
- `CONCAT`函数用于将两个字符串连接成一个新的字符串。
- `COUNT`函数计算某列的记录数,也可以在`COUNT(*)`中使用,计算表中的总行数。
### 2.1.2 WHERE子句的条件限制技巧
`WHERE`子句用于指定筛选记录的条件。它是在执行查询时限制返回结果的关键部分。
**基本使用示例:**
```sql
SELECT column1, column2
FROM table_name
WHERE column1 = 'value';
```
**条件限制技巧:**
1. **逻辑运算符:** 使用`AND`和`OR`结合多个条件。
```sql
SELECT column1, column2
FROM table_name
WHERE column1 = 'value' AND column2 > 10;
```
2. **模式匹配:** SQL提供了模式匹配运算符,如`LIKE`、`NOT LIKE`,用于模糊匹配。
```sql
SELECT column1, column2
FROM table_name
WHERE column2 LIKE 'A%';
```
3. **范围匹配:** 使用`BETWEEN`来找出列值在两个值之间的所有记录。
```sql
SELECT column1, column2
FROM table_name
WHERE column2 BETWEEN 10 AND 20;
```
**参数说明:**
- `LIKE`运算符用于在`WHERE`子句中搜索列中的指定模式,百分号`%`代表任意数量的字符。
### 2.1.3 GROUP BY与HAVING子句的组合使用
`GROUP BY`子句用于结合聚合函数,根据一个或多个列对结果集进行分组。而`HAVING`子句允许对`GROUP BY`形成的分组进行条件限制。
**基本使用示例:**
```sql
SELECT column1, COUNT(*)
FROM table_name
GROUP BY column1
HAVING COUNT(*) > 5;
```
在这个示例中,我们按照`column1`对数据进行分组,并计算每个分组的记录数。`HAVING`子句确保只返回那些记录数大于5的分组。
**组合使用的技巧:**
1. **多列分组:** 可以按照多个列进行分组,从而对数据进行更精细的聚合。
```sql
SELECT column1, column2, COUNT(*)
FROM table_name
GROUP BY column1, column2
HAVING COUNT(*) > 5;
```
2. **排序和限制结果集:** 分组后可以使用`ORDER BY`对结果集进行排序,或者使用`LIMIT`限制返回的行数。
```sql
SELECT column1, COUNT(*)
FROM table_name
GROUP BY column1
HAVING COUNT(*) > 5
ORDER BY COUNT(*) DESC
LIMIT 10;
```
**参数说明:**
- `GROUP BY`子句可以对多个列进行分组,提供一个列名列表。
- `HAVING`子句类似于`WHERE`,但它是在分组后的结果集上应用条件,通常与聚合函数一起使用。
在接下来的章节中,我们将深入探讨SQL语句重构的核心原则,并进一步分析性能优化和SQL语句的模块化和复用策略。
# 3. SQL语句优化技巧和实践案例
## 3.1 SQL优化工具的介绍和使用
优化数据库性能是提升应用响应速度和降低资源消耗的关键步骤。了解并掌握SQL优化工具是每个数据库管理员(DBA)和开发人员的必备技能。
### 3.1.1 索引优化的策略和技巧
索引是数据库查询优化的重要手段,它能够显著提升数据检索的速度。以下是索引优化的一些策略和技巧:
- **使用合适的索引类型:** 根据查询模式选择B-Trees、哈希表或全文索引。例如,对于范围查询,B-Tree索引最为合适。
- **创建复合索引:** 当一个表中存在多个字段的联合查询时,可以通过复合索引来优化查询性能。注意索引字段的顺序应与查询条件中的字段顺序一致。
- **避免过多索引:** 索引能够优化查询,但也增加了插入和更新操作的成本。因此,应定期评估

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MySQL 查询语句优化的技巧,旨在帮助数据库管理员和开发人员提升数据库性能。文章涵盖了从基础技巧到高级策略的广泛主题,包括避免全表扫描、利用查询缓存、重构 SQL 语句、选择最佳连接类型、分析慢查询日志、设计高效索引、比较子查询和 JOIN 的性能、解决真实世界的性能难题、实施分库分表策略、优化大数据量查询、评估优化效果、处理 NULL 值以及利用索引合并。通过这些技巧,读者可以优化 MySQL 查询语句,显著提高数据库响应速度和整体性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
西门子Insight软件:新手必读的7大操作要点与界面解读
参考资源链接:[西门子Insight软件用户账户管理操作手册](https://wenku.csdn.net/doc/6412b78abe7fbd1778d4aa90?spm=1055.2635.3001.10343)
# 1. 西门子Insight软件概述
## 1.1 软件简介
西门子Insight软件是一款面向工业设备和生产线的先进监控与数据分析解决方案。它将实时数据可视化和
【BODAS通信协议详解】:3大关键点,精通控制器与外部设备交互

参考资源链接:[BODAS控制器编程指南:从安装到下载的详细步骤](https://wenku.csdn.net/doc/6ygi1w6m14?spm=1055.2635.3001.10343)
# 1. BODAS通信协议概述
BODAS通信协议,作为工业自动化领域内的一项重要技术标准,确保了不同设备之间的高效、准确通信。在深入探究其内部工作机制之前,我们需要对其基本概念有所了解。本章主要介绍了BODAS协议
【CAD软件兼容性宝典】:确保许可管理器与OS完美结合

参考资源链接:[CAD提示“许可管理器不起作用或未正确安装。现在将关闭AutoCAD”的解决办法.pdf](https://wenku.csdn.net/doc/644b8a65ea0840391e559a08?spm=1055.2635.3001.10343)
# 1. CAD软件兼容性的重要性
CAD(计算机辅助
【Innovus命令行快速指南】:掌握这些技巧,让你从新手变大师
参考资源链接:[Innovus P&R 操作指南与流程详解](https://wenku.csdn.net/doc/6412b744be7fbd1778d49af2?spm=1055.2635.3001.10343)
# 1. Innovus命令行基础介绍
Innovus是Cadence公司推出的一款用于芯片设计的集成电路设计软件,其强大的命令行工具支持从设计、仿真到验证
深度剖析:巡检管理系统单机版A1.0的八大核心功能

参考资源链接:[巡检管理系统单机版A1.0+安装与使用指南](https://wenku.csdn.net/doc/6471c33c543f844488eb0879?spm=1055.2635.3001.10343)
# 1. 巡检管理系统单机版A1.0概览
巡检管理系统单机版A1.0是一个创新的IT解决方案,旨在实现资产的自动化管理,简化巡检流程,提升维护工作的效率和质量。本章节将提供一个整体性的概览,包括系统的基本功能、
STC89C52指令集精讲:助你迅速成为编程高手的50条指令详解
参考资源链接:[STC89C52单片机中文手册:概览与关键特性](https://wenku.csdn.net/doc/70t0hhwt48?spm=1055.2635.3001.10343)
# 1. STC89C52单片机简介及指令集概述
STC89C52单片机是基于经典的8051架构,广泛应用于嵌入式系统的开发中。它拥有8位处理器核心,其指令集简洁高效,针对实时控制应用进行了优化。本章将对STC89C52单片机进
【LabVIEW错误代码防不胜防】:开发者的10大陷阱与解决方案
参考资源链接:[LabVIEW错误代码大全:快速查错与定位](https://wenku.csdn.net/doc/7am571f3vk?spm=1055.2635.3001.10343)
# 1. LabVIEW错误代码的由来和影响
当我们进行LabVIEW开发时,错误代码是不可避免的。错误代码通常由不正确的程序执行引起,它们提供了解决问题的线索。了解错误代码的由来和
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )