【深度学习工作站搭建】:Anaconda环境配置与优化指南
发布时间: 2024-12-09 14:58:32 阅读量: 8 订阅数: 13 
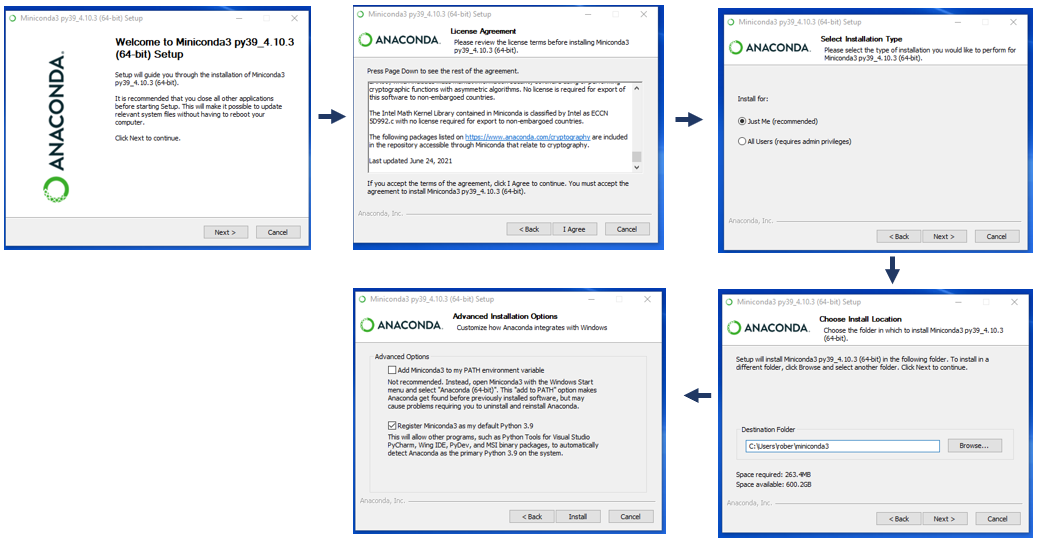
# 1. 深度学习工作站的基础知识
## 1.1 什么是深度学习工作站
深度学习工作站,通常指的是配备高性能硬件和专用软件,用于深度学习、机器学习和人工智能研究的计算机系统。这类工作站通常需要强大的处理器、大量内存和高速存储系统,以及能够支持并行计算的GPU。
## 1.2 深度学习工作站的重要性
在AI领域,数据和模型的复杂度不断提升,需要更多计算资源去处理和分析。深度学习工作站可以提供高效的计算能力,缩短模型训练的时间,加快科研进展和商业应用的落地。
## 1.3 工作站的典型配置
深度学习工作站典型配置包括多核心CPU、大容量高速RAM、NVMe固态硬盘、高性能GPU(如NVIDIA的Tesla或RTX系列),以及可能的高速网络连接。系统软件层面上,需要安装操作系统,如Linux或Windows Server,以及深度学习和数据分析所需的软件库和框架。
# 2. Anaconda环境配置
在深度学习和数据科学领域,Anaconda是一个流行的开源发行版,它集成了大量的科学计算包和依赖管理工具。它简化了Python环境的配置和管理,极大地提高了开发效率。本章节将详细介绍Anaconda的基本使用方法,创建和管理虚拟环境,以及环境的优化和维护。
## 2.1 Anaconda环境介绍
### 2.1.1 Anaconda简介
Anaconda是一个为Python科学计算而生的开源发行版,由Python和Conda(一个包和环境管理器)组成。Anaconda简化了包管理和环境隔离的过程,使得用户可以轻松地安装、管理和更新超过7500个科学计算相关的开源包。
Anaconda社区提供了大量的预配置环境,包括科学计算、数据分析、机器学习和深度学习等多种场景。此外,Anaconda还提供了Anaconda Navigator,这是一个图形用户界面工具,用户可以通过它来管理包和环境,以及启动Jupyter Notebook和其他应用程序。
### 2.1.2 Anaconda的安装与基本使用
**安装Anaconda:**
要安装Anaconda,首先需要从[Anaconda官网](https://www.anaconda.com/products/individual)下载适合您操作系统的安装包。下载完成后,根据您的操作系统执行相应的安装步骤。安装过程中,可以选择安装路径、是否添加Anaconda到系统环境变量等。
安装完成后,可以在终端中运行`conda list`命令来验证安装。如果显示了Conda及其管理的包列表,那么安装过程成功。
**基本使用:**
- 创建环境:`conda create --name myenv python=3.8`,这将在Anaconda中创建一个名为`myenv`的新环境,使用Python 3.8版本。
- 激活环境:`conda activate myenv`,使用此命令可以激活上面创建的环境。
- 安装包:`conda install numpy`,在当前激活的环境中安装Numpy包。
- 离开环境:`conda deactivate`,退出当前激活的环境。
## 2.2 Anaconda环境配置
### 2.2.1 创建虚拟环境
虚拟环境是独立的Python环境,可以让不同项目使用不同版本的包而互不干扰。Anaconda通过`conda create`命令来创建新的虚拟环境。
在创建环境时,可以指定环境名称、Python版本及其他包:
```bash
conda create --name myenv python=3.8 numpy scipy
```
这个命令会创建一个名为`myenv`的新环境,里面安装了Python 3.8和Numpy、Scipy包。
### 2.2.2 管理包和环境
管理包:
- 安装包:`conda install package-name`。
- 更新包:`conda update package-name`。
- 卸载包:`conda remove package-name`。
管理环境:
- 查看所有环境:`conda info --envs` 或 `conda env list`。
- 复制环境:`conda create --name newenv --clone oldenv`。
- 删除环境:`conda env remove --name myenv`。
## 2.3 Anaconda环境优化
### 2.3.1 环境的备份和迁移
备份环境可以帮助用户在不同的机器之间迁移或备份工作环境。Anaconda允许用户通过导出和导入环境配置文件来进行环境的备份和迁移。
导出环境配置文件:
```bash
conda env export > environment.yaml
```
此命令会将当前激活的环境配置导出到`environment.yaml`文件中。包含环境名称、Python版本、包列表等信息。
导入环境配置文件:
```bash
conda env create -f environment.yaml
```
这条命令将会根据`environment.yaml`文件创建一个新的环境。
### 2.3.2 环境的清理和更新
随着时间的推移,环境中可能会积累一些不再需要的包或者旧版本的包,可以通过以下命令进行清理:
清理不再需要的包:
```bash
conda clean --packages
```
清理缓存的包文件:
```bash
conda clean --tarballs
```
更新环境中的所有包:
```bash
conda update --all
```
执行以上命令可以优化Anaconda环境,使其保持高效和最新状态。
# 3. 深度学习框架安装与配置
## 3.1 深度学习框架的选择与安装
### 3.1.1 TensorFlow的安装
TensorFlow是Google开发的开源机器学习框架,广泛应用于图像识别、自然语言处理等众多深度学习任务。它的安装过程相对简单,但需要注意选择合适的版本以匹配系统环境和硬件配置。
安装TensorFlow的推荐方式是使用`pip`命令,这是一个Python的包管理工具。在安装之前,需要确保系统已经安装了Python和pip。以下是在标准环境下安装TensorFlow的步骤:
```bash
pip install tensorflow
```
若需要GPU支持的TensorFlow版本(通常称为`tensorflow-gpu`),首先需要确保NVIDIA的CUDA和cuDNN库已经安装好。随后使用以下命令安装:
```bash
pip install tensorflow-gpu
```
在安装过程中,如果遇到版本不兼容或者依赖性问题,可以通过指定版本号来安装特定版本的TensorFlow:
```bash
pip install tensorflow==1.15
```
安装完成之后,可以在Python环境中测试TensorFlow是否安装成功:
```python
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.compat.v1.Session()
print(sess.run(hello))
```
以上代码会输出`Hello, TensorFlow!`,表示安装成功。
### 3.1.2 PyTorch的安装
PyTorch是一个开源的机器学习库,以其动态计算图的特性而闻名,非常适合于研究和实验。它是基于Lua的Torch项目在Python中的重新实现,由Facebook的AI研究院主导开发。
安装PyTorch一般推荐使用`conda`(Anaconda的包管理器),因为它能够更简单地管理依赖关系和环境。在安装之前,需要确保已经安装了Anaconda环境。安装PyTorch的命令如下:
```bash
conda install pytorch torchvision torchaudio -c pytorch
```
上面的命令将安装最新版本的PyTorch。如果需要安装特定版本,可以指定版本号:
```bash
conda install pytorch==1.7 torchvision==0.8 -c pytorch
```
安装过程中,`conda`会自动处理好所有依赖关系。安装完成后,通过以下Python代码测试PyTorch是否安装成功:
```python
import torch
print(torch.__version__)
```
如果成功,它将打印出安装的PyTorch版本。
## 3.2 深度学习框架配置
### 3.2.1 GPU加速配置
深度学习模型训练通常需要大量计算资源,使用GPU可以显著提高训练速度。在安装好支持GPU的深度学习框架后,需要进行一系列配置才能让框架正确利用GPU资源。
以TensorFlow为例,首先确认CUDA和cuDNN已正确安装。然后,创建一个TensorFlow会话时,可以通过设置`device`参数来指定使用CPU还是GPU。通常情况下,TensorFlow能够自动检测并利用可用的GPU资源,无需额外设置。
```python
import tensorflow as tf
# 创建一个显卡配置的上下文
device_name = '/gpu:0'
with tf.device(device_name):
my_constant = tf.constant([[1.0, 2.0], [3.0, 4.0]])
my_matrix = tf.matmul(my_constant, [[1.0, 1.0], [0.0, 1.0]])
sess = tf.compat.v1.Session(config=tf.compat.v1.ConfigProto(log_device_placement=True))
print(sess.run(my_matrix))
```
这段代码的输出会包含设备分配信息,显示出GPU被使用的情况。
对于PyTorch来说,支持GPU非常简单。只要在数据张量和模型的设备设置中指定使用GPU:
```python
import torch
# 确保设备可用
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x = torch.randn(10, 5).to(device)
print(x.device)
```
如果系统有可用的GPU,`x`就会在GPU上被创建,`x.device`将显示相应的GPU设备。
### 3.2.2 并行计算配置
并行计算允许在多个GPU上同时运行计算任务,这可以进一步提高深度学习模型的训练速度。在TensorFlow中,可以通过`tf.distribute.Strategy`来设置多GPU训练。
以下是一个使用多GPU进行训练的简单示例:
```python
import tensorflow as tf
# 定义一个简单的模型函数
def create_model():
return tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(256, 256, 3)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
# 设置策略,使用所有可用的GPU
strategy = tf.distribute.MirroredStrategy()
# 在策略范围内构建模型
with strategy.scope():
model = create_model()
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
# 执行模型训练
model.fit(train_data, epochs=10)
```
这段代码使用了`tf.distribute.MirroredStrategy()`,它会自动镜像模型到每个可用的GPU上,并将梯度平均以实现并行计算。类似的并行计算配置也可以在PyTorch中实现,通过设置`torch.nn.DataParallel`或者使用`torch.distributed`模块来实现多GPU训练。
通过以上步骤,深度学习框架的安装与配置将能顺利进行,为后续的深度学习实践打下坚实基础。在下一章节中,我们将探讨深度学习工作站的性能优化策略,进一步提升工作站的运行效率。
# 4. 深度学习工作站性能优化
## 4.1 硬件性能优化
### 4.1.1 GPU选择与配置
在构建深度学习工作站时,选择合适的GPU是至关重要的一步。GPU(图形处理单元)专为处理大规模并行计算任务而设计,是深度学习训练的核心硬件之一。选择时主要考虑以下因素:
- **计算能力**:GPU的计算能力由CUDA核心数、Tensor核心数等决定。NVIDIA的GPU通常以CUDA核心的总数来衡量其性能。例如,RTX系列中的RTX 2080 Ti拥有4352个CUDA核心,而较新的RTX 3090则有10496个CUDA核心。
- **显存容量**:显存(VRAM)用于存储模型参数、激活函数值等。大显存容量可以支持更大规模的模型训练,避免显存溢出导致的训练中断。
- **内存带宽**:高内存带宽可以保证数据快速传输到GPU,减少数据传输时间,提高训练效率。
在GPU配置方面,确保驱动程序更新到最新版本是必须的步骤。通过NVIDIA的官方网站下载对应型号的最新驱动程序,并在操作系统中安装。此外,利用NVIDIA提供的工具如`nvidia-smi`可以监控GPU的运行状态,包括温度、功耗、显存使用情况等。
```bash
nvidia-smi
```
运行上述命令后,可以获得以下信息:
- GPU的名称和型号
- 总的和空闲的显存(包括MB和%)
- GPU利用率
- GPU温度
- 功率限制和消耗的功率
### 4.1.2 内存和存储的优化
内存和存储的优化对于深度学习工作站的性能同样重要。内存大小直接关系到能够同时处理数据集的大小,而快速的存储系统可以大幅缩短数据读写时间,提高训练速度。
- **内存升级**:根据深度学习模型的需求升级系统内存。一般而言,16GB到32GB内存能够满足大多数中小型模型的需求,但对于大型模型或多个模型同时训练,则可能需要更多内存。
- **固态硬盘(SSD)**:SSD相比传统硬盘(HDD)有更好的读写速度,可以显著减少数据加载时间。为深度学习工作站配置至少一块SSD是提高效率的关键步骤。
对于深度学习任务,可以考虑使用RAID技术,将多个硬盘组合起来提供更高的读写速度或更大的存储空间。另外,优化文件系统如使用XFS或Btrfs,可进一步提升存储性能。
在安装和配置方面,可以使用以下命令来检查SSD的健康状况和性能:
```bash
sudo fio --filename=/dev/sda --direct=1 --readwrite=read --ioengine=libaio --bs=4k --iodepth=64 --size=4G --numjobs=1 --runtime=1000 --group_reporting
```
上述命令使用`fio`工具对`/dev/sda`设备进行测试,读取4KB块大小的随机数据,测试时间持续1000秒,以评估SSD的读取性能。
## 4.2 软件性能优化
### 4.2.1 深度学习框架的优化
优化深度学习框架(如TensorFlow、PyTorch)可以提高训练效率和模型性能。优化措施包括:
- **模型并行化**:对于超大型模型,单个GPU可能无法处理,这时可以利用模型并行化将模型的不同部分分布在多个GPU上。
- **混合精度训练**:利用半精度浮点数(FP16)加快计算速度,同时通过动态调整缩放因子(如在PyTorch中使用`torch.cuda.amp`)来维持训练精度。
- **优化模型结构**:使用高效的网络架构和操作来减少模型复杂度和参数数量。
在代码层面上,可以使用以下PyTorch代码片段来实现混合精度训练:
```python
import torch
from torch.cuda.amp import autocast
# 假设model和inputs已经定义
model.train()
for batch in data_loader:
inputs = inputs.to(device="cuda", dtype=torch.float16)
with autocast():
outputs = model(inputs)
loss = loss_function(outputs, targets)
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
```
这段代码中,`autocast`用于自动管理FP32和FP16之间的转换,而`scaler.scale(loss).backward()`和`scaler.step(optimizer)`确保在适当的时候使用FP32进行梯度累积和权重更新。
### 4.2.2 操作系统的优化
操作系统层面上的优化可以包括:
- **内核升级**:确保操作系统使用最新的内核版本,以获得最新的性能改进和bug修复。
- **资源管理器调整**:例如,通过配置cgroups限制应用程序的资源使用,确保系统稳定运行。
- **磁盘调度策略调整**:使用适合的磁盘调度器(如CFQ、Deadline、NOOP等)可以提升文件系统的I/O性能。
操作系统优化往往需要深入系统底层,可以使用以下命令来查看内核版本:
```bash
uname -a
```
同时,可以修改`/etc/sysctl.conf`文件来调整内核参数,并使用`sysctl -p`来应用新的配置。例如,调整文件描述符的数量限制,以适应深度学习任务的需要:
```bash
# /etc/sysctl.conf 中的配置项
fs.file-max = 65536
# 应用新的配置
sudo sysctl -p
```
这些步骤是优化操作系统性能、确保深度学习工作站高效运行的关键。通过精心调整硬件和软件层面,可以显著提升深度学习任务的执行速度和整体效率。
# 5. 深度学习工作实践
## 5.1 深度学习项目的搭建
在深度学习领域,项目的搭建是一个复杂且逐步细化的过程。项目搭建的正确性和有效性将直接决定后续工作的顺利进行。本章节将详细介绍如何创建和管理深度学习项目,以及如何准备和处理数据集。
### 5.1.1 项目的创建与管理
创建一个全新的深度学习项目是构建模型的第一步。一个良好的项目结构可以极大提升后续研究和开发的效率。以下是一些创建和管理项目的步骤:
#### 1. 初始化项目结构
一个典型的深度学习项目结构包括数据、模型、脚本、日志、配置文件等多个部分。在项目的根目录下创建如下结构:
```plaintext
project-root/
|-- data/
|-- models/
|-- scripts/
|-- logs/
|-- configs/
|-- requirements.txt
```
#### 2. 使用版本控制系统
对于任何项目,使用版本控制系统是非常重要的。Git是目前最流行的选择。你需要创建一个`.gitignore`文件,列出不需要版本控制的文件和目录。
```plaintext
# .gitignore
data/
logs/
```
然后,初始化你的Git仓库,并开始你的第一个提交。
```bash
git init
git add .
git commit -m "Initial project commit"
```
#### 3. 管理依赖
使用`requirements.txt`文件来管理项目依赖。你可以通过执行`pip freeze > requirements.txt`来创建这个文件。
```plaintext
# requirements.txt
numpy==1.19.5
pandas==1.2.3
tensorflow==2.4.1
```
#### 4. 脚本编写和执行
在`scripts/`目录中组织你的Python脚本。每个脚本都应该有明确的目的,例如数据预处理、模型训练、评估和预测等。
```python
# scripts/train_model.py
import tensorflow as tf
def build_model():
# 构建模型架构
pass
if __name__ == "__main__":
model = build_model()
# 训练模型
```
执行脚本时,确保使用虚拟环境中的Python解释器。
### 5.1.2 数据集的准备与处理
#### 1. 数据集的选择
选择合适的数据集对于训练有效的深度学习模型至关重要。数据集的选择应该基于项目的需求和模型的目标。可以从公开的数据库中获取数据集,如ImageNet、COCO或Kaggle。
#### 2. 数据集的预处理
原始数据通常需要预处理才能用于训练。预处理包括归一化、归一化、裁剪、旋转、数据增强等。
```python
import tensorflow as tf
def preprocess_image(image):
image = tf.image.resize(image, [224, 224])
image /= 255.0
return image
```
#### 3. 数据集的划分
将数据集划分为训练集、验证集和测试集是必要的。这样可以在训练过程中监控模型的性能,并在最后对模型进行评估。
```python
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
images, labels, test_size=0.2, random_state=42
)
```
## 5.2 深度学习模型的训练与优化
模型的训练和优化是深度学习的核心步骤。在这一部分,我们将详细探讨如何训练模型,以及如何进行模型的优化。
### 5.2.1 模型的训练
模型训练的流程通常包括定义模型架构、选择损失函数和优化器,以及设置训练过程中的参数如批大小和迭代次数。
#### 1. 定义模型架构
```python
# 使用TensorFlow定义一个简单的卷积神经网络模型
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(224, 224, 3)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(num_classes, activation='softmax')
])
```
#### 2. 编译模型
```python
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
```
#### 3. 训练模型
```python
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test))
```
### 5.2.2 模型的优化
模型优化的目的是提高模型的准确性或者减少过拟合现象。以下是一些常见的优化方法:
#### 1. 调整模型架构
可以尝试增加或减少层数,或者调整每层的单元数来观察模型性能的变化。
#### 2. 使用正则化
应用L1、L2正则化或Dropout层来减少过拟合。
```python
model.add(tf.keras.layers.Dropout(0.5))
```
#### 3. 超参数调整
通过网格搜索(Grid Search)、随机搜索(Random Search)或贝叶斯优化等方法来寻找最优的超参数。
```python
from sklearn.model_selection import GridSearchCV
parameters = {'batch_size': [32, 64], 'epochs': [10, 20]}
grid_search = GridSearchCV(estimator=model, param_grid=parameters, n_jobs=-1, cv=3)
grid_search = grid_search.fit(X_train, y_train)
```
#### 4. 使用预训练模型
预训练的模型通常是在大型数据集上训练得到的,使用预训练模型作为起点并对其进行微调,可以加快模型训练速度并提高准确性。
```python
base_model = tf.keras.applications.VGG16(include_top=False, input_shape=(224, 224, 3))
model = tf.keras.models.Sequential([
base_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(num_classes, activation='softmax')
])
```
深度学习模型的训练和优化是一个不断尝试和调整的过程。在实践中,你将需要根据具体问题调整和优化模型,以达到最佳性能。
# 6. 深度学习工作站的安全与维护
随着深度学习工作站处理的数据价值和计算能力的增加,其安全性与稳定性变得至关重要。在本章节中,我们将探讨如何制定合理的系统安全策略,以及如何进行日常的系统维护和故障处理。
## 6.1 系统安全策略
在深度学习工作站的安全策略中,我们需要着重考虑数据保护、网络防护和权限控制几个方面,以确保系统不会受到非法入侵或数据泄露。
### 6.1.1 防火墙配置
防火墙是工作站的第一道防线,它可以控制进出网络的数据流量。在配置防火墙时,我们可以通过以下步骤来增强工作站的安全性:
1. **启用防火墙服务**:确保防火墙服务已经在操作系统上启动并运行。
2. **配置规则**:根据实际需要配置入站和出站规则,允许合法的连接,阻止潜在的恶意连接。
3. **定期更新规则**:随着工作环境和需求的变化,定期更新防火墙规则以应对新的安全威胁。
下面是一个配置防火墙规则的示例命令,以Linux系统为例:
```bash
sudo iptables -A INPUT -p tcp --dport 80 -j ACCEPT # 允许访问HTTP服务
sudo iptables -A OUTPUT -p tcp --sport 80 -j ACCEPT # 允许出站连接HTTP服务
sudo iptables -P INPUT DROP # 默认阻止所有入站连接
sudo iptables -P OUTPUT ACCEPT # 默认允许所有出站连接
```
### 6.1.2 权限管理
合理配置用户权限可以减少工作站被未授权访问的风险。可以按照以下原则进行权限管理:
1. **最小权限原则**:为用户账户分配完成工作所必需的最小权限。
2. **访问控制**:对于敏感文件和目录,设置适当的访问权限,如数据集或模型参数文件。
3. **身份验证**:使用密码策略和多因素认证加强账户安全性。
以下是在Linux系统中创建用户和设置权限的示例步骤:
```bash
sudo useradd -m newuser # 创建新用户
sudo passwd newuser # 设置新用户密码
sudo chown newuser:groupname /path/to/directory # 更改目录所有者
sudo chmod 700 /path/to/directory # 设置目录权限为700
```
## 6.2 系统维护与故障处理
深度学习工作站的维护包括系统备份、更新以及故障诊断与处理,以保证工作站的持续稳定运行。
### 6.2.1 系统备份与恢复
为防止意外情况导致数据丢失或系统崩溃,定期备份系统和关键数据是必要的。备份可以是全系统备份,也可以是关键文件和目录的备份。以下是使用rsync进行目录备份的示例命令:
```bash
rsync -avz /path/to/source /path/to/destination
```
在需要的时候,可以通过以下命令恢复备份:
```bash
rsync -avz --delete /path/to/destination /path/to/source
```
### 6.2.2 故障诊断与处理
当工作站出现问题时,能够快速定位和解决问题至关重要。常见的故障诊断方法包括查看系统日志、使用监控工具和运行诊断命令。下面是一个查看系统日志的示例:
```bash
tail -f /var/log/syslog # 实时查看系统日志
```
对于硬件故障,可以使用以下命令来检查硬盘状态:
```bash
smartctl -a /dev/sda # 查看第一个SATA硬盘的详细信息
```
通过以上步骤和方法,可以系统性地加强深度学习工作站的安全性,并制定一套完善的维护计划来应对可能出现的各类问题。这将有助于保持工作站的稳定运行,并为深度学习项目提供坚实的基础保障。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Anaconda在深度学习中的应用》专栏深入探讨了Anaconda在深度学习领域的广泛应用,涵盖了从性能提升到项目管理的各个方面。专栏文章包括:
* **深度学习性能瓶颈突破:**Anaconda与GPU加速技术解析
* **深度学习管道构建:**从零开始的Anaconda应用指南
* **深度学习框架兼容性:**Anaconda兼容性完全手册
* **分布式深度学习集群:**Anaconda在大规模计算中的应用策略
* **机器学习项目管理:**Anaconda在项目流程中的关键角色
* **深度学习模型压缩:**Anaconda环境下的轻量化策略指南
* **深度学习数据增强:**Anaconda高效数据增强实用技巧
* **深度学习实验记录:**Anaconda环境中的Notebook高效记录方法
通过这些文章,读者将了解Anaconda如何帮助深度学习从业者克服性能瓶颈、构建高效管道、管理复杂项目以及优化模型和数据。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【图像分析软件深度剖析】:Image-Pro Plus 6.0 高级功能全面解读

参考资源链接:[Image-Pro Plus 6.0 中文
【智慧竞赛必备】:四人抢答器设计全面指南与优化秘籍
参考资源链接:[四人智力竞赛抢答器设计与实现](https://wenku.csdn.net/doc/6401ad39cce7214c316eebee?spm=1055.2635.3001.10343)
# 1. 四人抢答器设计概述
## 1.1 设计背景
在日常的学术研讨、知识竞赛以及各种娱乐节目中,我们经常能看到抢答器的身影。随着技术的发展和应用场景的多样化,对抢答器的性能和功能提出了更高的要求。一个高效、准确
高通Camera Chi-CDK Feature2性能与兼容性秘籍:跨平台与调优全攻略

参考资源链接:[高通相机Feature2框架深度解析](https://wenku.csdn.net/doc/31b2334rc3?spm=1055.2635.3001.10343)
# 1. Camera Chi-CDK Feature2概述
## 1.1 Camera Chi-CDK Feature2
验证规则的最佳实践:精通系统稳定性

参考资源链接:[2014年Mentor Graphics Calibre SVRF标准验证规则手册](https://wenku.csdn.net/doc/70kc3iyyux?spm=1055.2635.3001.10343)
# 1. 系统稳定性的基础理论
系统稳定性是指在一定时间内,系统保持其功能正常运行的能力。它是一个复杂的话题,涉及多个方面,包括硬
深入解析Android WebView文件下载:性能优化与安全性提升指南

参考资源链接:[Android WebView文件下载实现教程](https://wenku.csdn.net/doc/3ttcm35729?spm=1055.2635.3001.10343)
# 1. Android WebView文件下载基础
## 1.1 WebView概述
在移动应用开发中,WebView是一个重要的组件,它
【交互设计的艺术】:优雅地引导用户订阅小程序消息
参考资源链接:[小程序订阅消息拒绝后:如何引导用户重新开启及获取状态](https://wenku.csdn.net/doc/6451c400ea0840391e738237?spm=1055.2635.3001.10343)
# 1. 交互设计在小程序中的重要性
随着互联网技术的不断进步,小程序作为移动互联网领域的新宠,其用户界面(UI)和用户体验(UX)的重要性日益凸显。交互设计作为用户体验的核心
【S19文件错误排查】:高效排除常见错误,提升调试效率
参考资源链接:[S19文件格式完全解析:从ASCII到MCU编程](https://wenku.csdn.net/doc/12oc20s736?spm=1055.2635.3001.10343)
# 1. S19文件错误排查概述
S19文件错误排查是嵌入式开发中常见的工作流程之一,尤其在微控制器程序开发中占有重要的地位。本
【PLC编程语言对比】:梯形图与指令列表的优劣深度分析
参考资源链接:[PLC毕业设计题目大全:300+精选课题](https://wenku.csdn.net/doc/3mjqawkmq0?spm=1055.2635.3001.10343)
# 1. PLC编程语言概述
## 1.1 PLC编程语言的发展简史
可编程逻辑控制器(PLC)自20世纪60年代问世以来,便成为了工业自动化领域不可或缺的设备。PLC编程语言也随着技术的不断进步,从最初的继电器逻辑图,发展到如今包括梯形图、指令列表(IL)、功能块
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )