Python情感分析提升课:构建混合模型,深度挖掘文本情感
发布时间: 2024-12-07 06:46:01 阅读量: 7 订阅数: 16 

基于微博评论的情感分析LDA主题分析和情感分析 完整数据代码可直接运行
# 1. Python情感分析概述
## 1.1 情感分析的定义与重要性
情感分析(Sentiment Analysis),也称为意见挖掘(Opinion Mining),是自然语言处理(NLP)领域的一个分支,旨在识别和提取文本数据中的主观信息。通过分析文本数据中的情感色彩,我们可以了解作者或公众对于某一话题或产品的态度是正面、中立还是负面。
情感分析广泛应用于市场研究、公关管理、政治分析等领域。尤其在互联网大数据时代,社交媒体、评论论坛等成为人们表达意见的重要平台,对这些海量信息进行有效的情感分析,对企业理解消费者情感、监测品牌声誉、优化产品和服务等方面具有重要意义。
## 1.2 Python在情感分析中的作用
Python由于其丰富的数据处理和机器学习库,在情感分析领域得到了广泛的应用。通过使用如NLTK、TextBlob、Scikit-learn、Keras等库,开发者能够轻松构建并训练复杂的模型,以完成从文本数据的预处理、特征提取到情感分类的全过程。
Python的易用性和灵活性为情感分析的研究和开发提供了便利。它不仅支持快速原型开发,还具备强大的社区支持和丰富的第三方资源,这让Python成为数据分析和NLP领域的首选语言。随着深度学习框架的完善,Python在情感分析中的作用愈发凸显,这也让更多的企业和研究机构倾向于采用Python作为情感分析工具。
在接下来的章节中,我们将详细探讨如何使用Python来构建情感分析的基础模型,并讨论在实践中如何优化这些模型以提高分析的准确性和效率。
# 2. 构建情感分析的基础模型
情感分析是自然语言处理(NLP)领域的一个重要分支,其核心目标是识别和提取文本数据中的主观信息。在本章中,我们将深入探讨构建基础情感分析模型的各个技术步骤。
## 2.1 文本预处理技术
文本预处理是情感分析中至关重要的一步,它直接关系到模型训练的效果和最终的情感识别精度。
### 2.1.1 分词和词性标注
在中文文本中,由于没有明显的单词边界,分词是文本预处理的第一步。分词之后,还需要进行词性标注,即识别每个词在句子中的语法功能。
```python
import jieba
sentence = "我爱北京天安门。"
words = list(jieba.cut(sentence))
print(words) # 输出分词结果
pos_tags = jieba.dt.postag(words)
print(pos_tags) # 输出词性标注结果
```
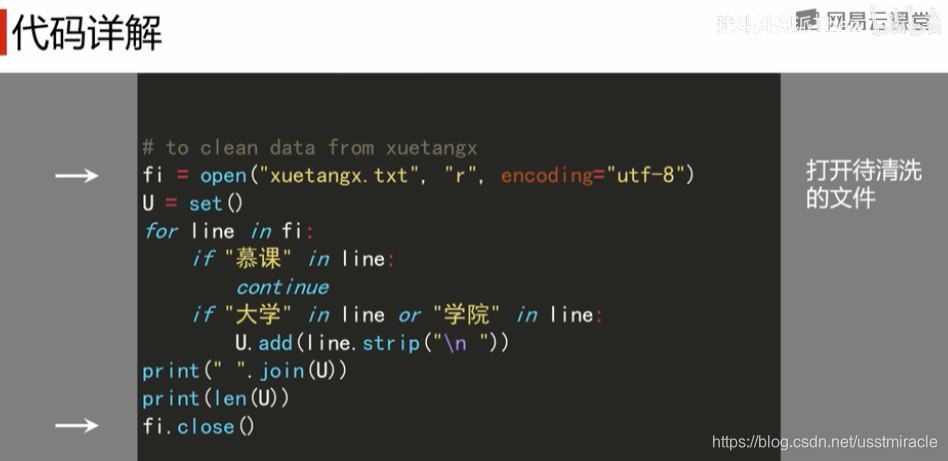
### 2.1.2 去除停用词和文本清洗
去除停用词是清理文本数据的重要步骤,停用词是指那些在文本中频繁出现但通常不承载有效信息的词,如“的”、“是”、“在”等。
```python
# 假设我们已经有了分词和词性标注的列表
filtered_words = [word for word, pos in pos_tags if pos not in ['u', 'x']]
print(filtered_words) # 输出过滤后的结果
```
## 2.2 基于机器学习的情感分析模型
在完成文本预处理之后,接下来的任务是构建一个基于机器学习的情感分析模型。
### 2.2.1 特征提取方法
文本数据需要转换为机器学习模型可以处理的数值特征。常用的特征提取方法有词袋模型(Bag of Words, BoW)、TF-IDF(Term Frequency-Inverse Document Frequency)等。
```python
from sklearn.feature_extraction.text import TfidfVectorizer
# 示例句子列表
sentences = ["我爱我的祖国", "我讨厌下雨"]
# 初始化TF-IDF向量化器
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(sentences)
feature_names = tfidf_vectorizer.get_feature_names_out()
print(feature_names) # 输出TF-IDF特征名称
print(tfidf_matrix.toarray()) # 输出TF-IDF特征矩阵
```
### 2.2.2 分类算法的选择与训练
在提取了文本特征之后,接下来就是选择合适的分类算法进行模型训练。常见的算法包括朴素贝叶斯、支持向量机(SVM)、随机森林等。
```python
from sklearn.svm import SVC
from sklearn.pipeline import make_pipeline
# 使用SVM算法进行分类
model = make_pipeline(TfidfVectorizer(), SVC(kernel='linear'))
model.fit(sentences, ["positive", "negative"])
# 对新的句子进行情感分析
new_sentences = ["我感到高兴", "我感到悲伤"]
predictions = model.predict(new_sentences)
print(predictions) # 输出预测结果
```
## 2.3 模型评估和优化
模型训练完成后,需要对其进行评估和优化,以确保它具有良好的泛化能力。
### 2.3.1 评估指标的选择
常用的评估指标有准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数等。
```python
from sklearn.metrics import classification_report
# 使用分类报告进行评估
print(classification_report(model.predict(sentences), ["positive", "negative"]))
```
### 2.3.2 模型调优策略
模型调优通常涉及调整模型参数、使用交叉验证等技术。其中,网格搜索(Grid Search)是一种常用的方法,它通过遍历预设的参数组合来找到最优模型配置。
```python
from sklearn.model_selection import GridSearchCV
# 设置SVM参数范围
parameters = {
'svc__C': [1, 10, 100],
'svc__gamma': [0.01, 0.1, 1]
}
# 使用网格搜索进行模型调优
grid_search = GridSearchCV(model, parameters, cv=3)
grid_search.fit(sentences, ["positive", "negative"])
# 输出最佳参数组合和交叉验证结果
print(grid_search.best_params_)
print(grid_search.best_score_)
```
在本章中,我们详细介绍了构

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 在自然语言处理 (NLP) 领域的广泛应用。从社交媒体情感分析到主题建模、自然语言生成、机器翻译、知识图谱构建、语音识别和文本聚类,该专栏提供了深入的教程和实践指南,帮助读者掌握 NLP 的关键技术。专栏还涵盖了大规模文本处理技术,包括文本清洗和预处理,以确保数据质量和效率。通过这些文章,读者将了解 Python 在 NLP 中的强大功能,并获得在现实世界项目中应用这些技术的实际技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入解析VW 80808-2 OCR标准:10个实用技巧助你提升解析效率

参考资源链接:[Volkswagen标准VW 80808-2(OCR)2017:电子元件与装配技术详细指南](https://wenku.csdn.net/doc/3y3gykjr27?spm=1055.2635.3001.10343)
# 1. OCR技术和VW 80808-2标准概述
## 1.1 OCR技术的简介
光学字符识别(OCR)技术通过分析图像,实现对印刷或
FENSAP-ICE高级功能详解:解锁仿真流程的终极秘籍

参考资源链接:[FENSAP-ICE教程详解:二维三维结冰模型与飞行器性能计算](https://wenku.csdn.net/doc/5z6q9s20x3?spm=1055.2635.3001.10343)
# 1. FENSAP-ICE基础和安装过程
## FENSAP-ICE简介
FENSAP-ICE 是一款专注
【LIFBASE快速入门指南】:3小时掌握系统搭建与基本操作

参考资源链接:[LIFBASE帮助文件](https://wenku.csdn.net/doc/646da1b5543f844488d79f20?spm=1055.2635.3001.10343)
# 1. LIFBASE概述及安装部署
LIFBASE作为一个全面的
银行储蓄系统中的数据一致性:如何保证分布式数据库下的ACID属性

参考资源链接:[银行储蓄系统设计与实现:高效精准的银行业务管理](https://wenku.csdn.net/doc/75uujt5r53?spm=1055.2635.3001.10343)
# 1. 数据一致性的重要性与挑战
在数字时代,数据的一致性是任何IT系统的核心要素之一。数据一致性确保了在并发处理和分布式系统中,数据的一致性状态能够被正确地维护。没有数据一致性,系统的可靠性将无
【COMe模块接口规范2.1:全面升级指南】:从基础到高级,解决常见问题
参考资源链接:[COMe模块接口规范,2.1版本](https://wenku.csdn.net/doc/8a1i84dgit?spm=1055.2635.3001.10343)
# 1. COMe模块接口规范概述
COMe(Computer on Module)模块是一种设计灵活的工业计算机模块标准,它允许用户集成标准化的计算机核心模块到自定义的载板上。在本文中,我们将概述COMe模块接口规范的基本概念,这为理解后续章节深入探讨该模块接口的硬件
FANUC机器人全解:从原理到应用的全方位深入解读

参考资源链接:[FANUC机器人点焊手册:全面指南与操作详解](https://wenku.csdn.net/doc/6412b763be7fbd1778d4a1f2?spm=1055.2635.3001.10343)
# 1. FANUC机器人的历史与核心技术
FANUC,全称富士通自动化数控公司,是全球领先的工业自动化与机器人制造商之一。它起源
【数字信号处理】:声压级计算在音频技术中的关键作用

参考资源链接:[总声压级与1/3倍频程计算方法详解](https://wenku.csdn.net/doc/2e8dqbq5wm?spm=1055.2635.3001.10343)
# 1. 声压级的基础理论与定义
## 声压级的物理基础
声压级(Sound Pressure Level,简称SPL)是描述声音强弱的一个物理量,它与声音在介质中传播时产生的压力变化有关。声压级的测量能够反映出声
OV426硬件架构与软件接口:专家级分析与最佳实践
参考资源链接:[OV426传感器详解:医疗影像前端解决方案](https://wenku.csdn.net/doc/61pvjv8si4?spm=1055.2635.3001.10343)
# 1. OV426硬件架构概述
## 1.1 OV426硬件组件概览
OV426是一款高度集成的硬件设备,其设计融合了多项先进技术,以满足各种复杂应用场景的需求。核心组件包括高性能的中央处理单元(CPU)、专用图
WinCC Audit V7.4 报表设计艺术:如何打造个性化报表并优化性能

参考资源链接:[WinCC 7.4 Audit配置详解:步骤与个性化设置](https://wenku.csdn.net/doc/2f4gwjr05v?spm=1055.2635.3001.10343)
# 1. WinCC Audit V7.4报表设计概述
在现代工业自动化中,高效的报表设计是企业决策支持系统的关键部分。WinCC Audit V7.4作为一个功能强大的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )