【数据科学工作流】:Anaconda模板最佳实践,构建可复现的数据科学工作流
发布时间: 2024-12-09 16:21:11 阅读量: 8 订阅数: 17 

利用python进行的数据分析项目,报告+代码的总结与积累
# 1. 数据科学工作流的基本概念
在当今数据驱动的世界中,数据科学工作流程是实现有效数据处理、分析和决策的关键。工作流程不仅涉及数据的收集和清洗,还包括模型的构建、验证和部署。一个高效的流程需要能够确保数据分析的可复现性、可扩展性和自动化。
## 数据科学工作流的组成
工作流程通常由以下步骤组成:
- 数据的探索与预处理,包括数据清洗和转换。
- 使用统计和机器学习算法进行数据分析和模式识别。
- 对分析结果进行评估和解释。
- 将模型应用于生产环境或决策过程中。
## 工作流程的重要性
良好的数据科学工作流程能够:
- 提升分析效率,因为重复的任务可以被自动化。
- 保证分析质量,通过版本控制和测试来确保结果的准确性。
- 增强团队协作,通过统一的流程和工具使团队成员能够高效沟通和协作。
在后续章节中,我们将更深入地探讨如何构建和优化数据科学工作流程,包括环境搭建、数据处理、版本控制和自动化等方面。让我们开始搭建您的数据科学工作流之旅吧!
# 2. Anaconda环境的搭建与管理
## 2.1 Anaconda概述
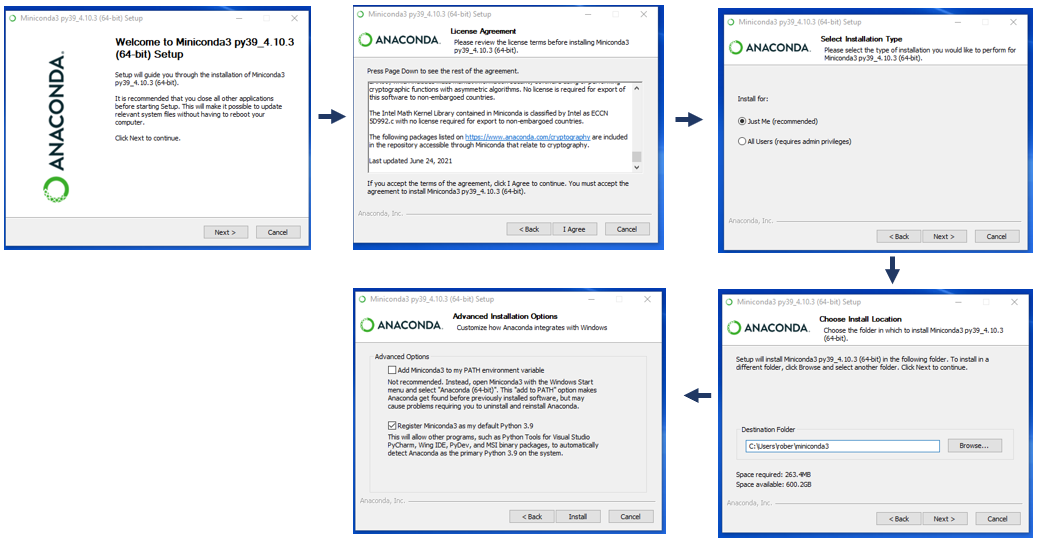
### 2.1.1 Anaconda的安装与配置
Anaconda是一个非常流行的Python发行版本,专为数据科学而设计。它包括了大量常用的科学计算包和库,使得数据科学家能够更加便捷地进行数据分析、数据处理、数据可视化以及机器学习等工作。Anaconda的安装过程十分简单,适合不同操作系统。在Linux、Windows和Mac OS X上,用户可以下载Anaconda的图形界面安装程序,并遵循几个简单的步骤即可完成安装。
安装完成后,推荐用户先配置一下环境变量,确保在任何终端中都能够直接调用conda命令。例如,在Windows系统中,可以将`C:\Users\YourUsername\Anaconda3`和`C:\Users\YourUsername\Anaconda3\Scripts`这两个路径添加到系统的PATH环境变量中。同时,也可以考虑设置CONDA_PREFIX和CONDA_DEFAULT_ENV环境变量,以优化Anaconda的使用体验。
### 2.1.2 管理Anaconda环境
Anaconda的一个核心优势在于其强大的环境管理功能,允许用户在不同的项目间切换而不会相互影响。使用conda可以创建隔离的Python环境,每个环境拥有自己独立的Python版本和安装的包。
创建一个新的环境非常简单,只需使用以下命令:
```bash
conda create -n myenv python=3.8
```
这个命令创建了一个名为`myenv`的环境,并安装了Python 3.8。环境创建完成后,使用以下命令激活新环境:
```bash
conda activate myenv
```
要查看当前所有环境,可以使用:
```bash
conda info --envs
```
删除环境使用:
```bash
conda remove --name myenv --all
```
这些操作可以方便用户在不同项目间进行环境切换,保证项目依赖的清晰和独立。
## 2.2 环境虚拟化与包管理
### 2.2.1 Conda环境的创建与激活
Conda环境管理器是Anaconda套件的核心组件之一,它可以帮助用户创建隔离的环境,这样可以针对不同的项目使用不同版本的依赖包。创建Conda环境需要指定环境名称以及希望安装的Python版本,如下所示:
```bash
conda create -n my_project_env python=3.7
```
这条命令会创建一个名为`my_project_env`的新环境,里面安装了Python 3.7版本。激活环境的命令依操作系统的不同而有所区别,在Windows中是:
```bash
conda activate my_project_env
```
而在Unix或MacOS系统中,是:
```bash
source activate my_project_env
```
通过这种方式,我们可以确保在项目`my_project`中使用特定的Python版本以及依赖库,而不影响系统中其他项目的环境。
### 2.2.2 包的安装、更新与删除
在创建了Conda环境后,我们常常需要在环境中安装更多的包。Conda提供了一个非常直观的命令来完成这一步骤:
```bash
conda install numpy pandas
```
Conda会自动处理包之间的依赖关系,并尝试安装指定的版本。如果需要升级包,可以使用`conda update`命令:
```bash
conda update numpy pandas
```
如果想升级所有包到最新版本,可以省略具体的包名:
```bash
conda update --all
```
删除包时,Conda同样提供了便捷的命令:
```bash
conda remove numpy pandas
```
Conda在管理包方面非常灵活,它不仅支持指定版本的安装,还能够兼容从其他来源(如PyPI)安装的包。在进行包的管理和维护时,使用Conda可以极大地简化数据科学工作流程。
## 2.3 版本控制与依赖管理
### 2.3.1 锁定依赖版本的重要性
在进行数据科学项目时,锁定依赖包的版本至关重要。这是因为包的版本更新可能会导致项目的运行环境发生变化,从而影响项目的可复现性和稳定性。为了确保项目在不同环境中的一致性,使用依赖管理工具锁定特定版本的包是最佳实践。
Conda提供了一种简单的方法来创建一个包含所有依赖的环境文件(通常命名为`environment.yml`),确保每次重建环境时都使用相同版本的包。创建环境文件的命令如下:
```bash
conda env export > environment.yml
```
这个命令会输出当前激活环境的所有包及其版本信息到`environment.yml`文件中。在需要在新环境中重现相同环境时,可以使用以下命令:
```bash
conda env create -f environment.yml
```
这个命令会根据`environment.yml`文件中的描述,创建一个与原始环境相同的环境。
### 2.3.2 使用Conda环境文件进行版本控制
正如我们在上一节所讨论的,使用Conda环境文件可以有效管理项目依赖。但是,随着项目的开发,我们可能需要更新依赖包的版本,这时候就需要版本控制系统来帮助我们跟踪这些变化。
Git是一个广泛使用的版本控制系统,它可以帮助我们记录和管理环境文件的变化。在每次更新依赖后,我们不仅要在本地保存`environment.yml`文件,还应该提交这个文件到Git仓库中。通过以下命令可以将文件添加到暂存区,并进行提交:
```bash
git add environment.yml
git commit -m "Update dependencies to latest versions"
```
这样,我们就可以利用Git来跟踪环境文件的变更历史,方便团队成员之间的协作,同时也确保了环境的一致性。
```mermaid
graph LR
A[开始] --> B[安装Anaconda]
B --> C[创建Conda环境]
C --> D[管理依赖包]
D --> E[导出环境文件]
E --> F[版本控制]
F --> G[结束]
```
本章节中我们详细介绍了Anaconda的基础知识,包括安装、环境创建和包管理,以及依赖管理的重要性和方法。希望读者能够通过本文档加深对Anaconda工作流的理解,并能够更加高效地进行数据分析和科学计算工作。
# 3. 数据处理与分析工具
在当今这个信息爆炸的时代,数据处理与分析工具对于数据科学家和分析师来说至关重要。他们需要高效且功能强大的工具来进行数据清洗、处理、分析和可视化,以便能够从海量的数据中提取有价值的信息。本章节将深入探讨这些工具,并展示如何通过它们进行高效的数据科学工作。
## 3.1 Jupyter Notebook的使用
Jupyter Notebook是一个开源的Web应用程序,允许用户创建和共享包含实时代码、方程、可视化和文本的文档。它已经成为数据科学家进行探索性数据分析、演示和教学的首选工具。
### 3.1.1 Jupyter Notebook的安装与启动
要安装Jupyter Notebook,推荐使用Anaconda环境,因为它自带了Jupyter Notebook及其依赖包。如果你已经安装了Anaconda,那么可以通过conda命令快速安装Jupyter Notebook:
```bash
conda install jupyter notebook
```
安装完成后,可以通过以下命令启动Jupyter Notebook服务:
```bash
jupyter notebook
```
启动后,浏览器将自动打开Jupyter的主界面,你可以在此创建新的笔记本(Notebook)文件。
### 3.1.2 交互式数据科学笔记本的优势
Jupyter Notebook的一个核心优势在于其交互性。笔记本格式允许用户以“单元格”为单位编写和执行代码,并实时查看输出结果。这使得数据科学工作流程变得透明和可重现。
- **灵活的编程环境:** 用户可以使用不同的编程语言(如Python、R等)在一个笔记本中执行和测试代码。
- **即时文档化:** Notebook内的Markdown单元格可以用来记录分析过程、解释代码逻辑或添加文档说明。
- **结果展示:** Notebook支持多种数据可视化工具的集成,能够直接在单元格中展示图表和图形。
通过Jupyter Notebook,用户能够更容易地进行探索性数据分析、分享研究发现,并在团队之间协作。
## 3.2 Pandas与NumPy入门
Pandas和NumPy是数据科学中常用的两个Python库,它们为数据处理和分析提供了强大的功能。
### 3.2.1 Pandas数据结构与操作
Pandas提供了两个主要的数据结构:Series和DataFrame。Series是一维数组,可以存储任何数据类型;DataFrame是二维标签数据结构,可以看作是一个表格或“数字版的E

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Anaconda项目模板专栏是一份全面的指南,涵盖了使用Anaconda进行项目管理和开发的各个方面。它提供了从创建项目模板到使用Git进行版本控制的逐步指导。专栏还介绍了Anaconda环境管理的最佳实践,以及优化开发和部署流程的技巧。此外,它还探讨了Anaconda模板在大数据项目中的应用,以及提高性能的内存管理和加速技术。通过本专栏,读者可以掌握Anaconda的强大功能,从而简化项目管理、提高开发效率并优化机器学习项目框架。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【北斗GPS模块全面解析】:正点原子ATK-1218-BD的实战应用与秘籍

参考资源链接:[正点原子ATK-1218-BD GPS北斗模块用户手册:接口与协议详解](https://wenku.csdn.net/doc/5o9cagtmgh?spm=1055.2635.3001.10343)
# 1. 北斗GPS模块简介
## 1.1 北斗和GPS技术概述
北斗系统(BDS)和全球定位系统(GPS)是两个主要的全球卫星导航系统。它们
NJ指令基准手册性能优化:4个关键技巧,助你提升系统性能

参考资源链接:[NJ系列指令基准手册:FA设备自动化控制指南](https://wenku.csdn.net/doc/64603f33543f8444888d9058?spm=1055.2635.3001.10343)
# 1. NJ指令基准手册概述与性能分析
在IT行业,基准测试是评估系统性能的重要手段。本章节将概述NJ指令基准手册的使用方法,并进行性能分析。NJ指令基准手册为
【Linux文件类型与结构:专家解读】
参考资源链接:[解决Linux:./xxx:无法执行二进制文件报错](https://wenku.csdn.net/doc/64522fd1ea0840391e739077?spm=1055.2635.3001.10343)
# 1. Linux文件类型概述
在Linux的世界里,文件类型不仅体现了文件的属性,也指导着用户如何与之交互。本章将带您入门Linux中的各种文件类型,帮助您轻
非线性优化的秘密武器:SQP算法深入解析
参考资源链接:[SQP算法详解:成功解决非线性约束优化的关键方法](https://wenku.csdn.net/doc/1bivue5eeo?spm=1055.2635.3001.10343)
# 1. SQP算法概述
**1.1 SQP算法简介**
序列二次规划(Sequential Quadratic Programming,简称SQP)算法是一种在工程和计算科学领域广泛应用的高效优化方法。它主要用来求解大规模非线性优化问题,特别适用于有约束条件的优化问题。
**1.2 SQP算法的优势**
SQP算法的优势在于其对问题的约束条件进行直接处理,并利用二次规划的子问题近似原始问题的
边界条件之谜:深入理解Evans PDE解法中的关键

参考资源链接:[Solution to Evans pde.pdf](https://wenku.csdn.net/doc/6401ac02cce7214c316ea4c5?spm=1055.2635.3001.10343)
# 1. 偏微分方程(PDE)基础
偏微分方程(Partial Differential Equations,简称 PDE)是数学中用于描述多变量函数的变
快影与剪映功能特色深度分析:技术、市场还是炒作?

参考资源链接:[快影与剪映:创作工具竞品深度解析](https://wenku.csdn.net/doc/1qj765mr85?spm=1055.2635.3001.10343)
# 1. 视频编辑软件市场概览
随着数字化时代的快速发展,视频编辑软件已经成为内容创作者、营销人员和多媒体爱好者不可或缺的工具。在这一章节中,我们将首先对当前视频编辑软件市场的现状进行简要概述,包括市场的主要参与者、流行的视频编辑工具以及行业的发展趋势。
揭秘JEDEC JEP122H 2016版:存储器设备应急恢复的全攻略

参考资源链接:[【最新版可复制文字】 JEDEC JEP122H 2016.pdf](https://wenku.csdn.net/doc/hk9wuz001r?spm=1055.2635.3001.10343)
# 1. JEDEC JEP122H 2016版
【NRF52810蓝牙SoC终极指南】:精通硬件设计到安全性的17个关键技巧

参考资源链接:[nRF52810低功耗蓝牙芯片技术规格详解](https://wenku.csdn.net/doc/645c391cfcc53913682c0f4c?spm=1055.2635.3001.10343)
# 1. NRF52810蓝牙SoC概述
## 简介
NRF52810是Nordi
【Orin系统快速调试】:高效定位与问题解决技巧

参考资源链接:[英伟达Jetson AGX Orin系列手册与性能详解](https://wenku.csdn.net/doc/2sn46a60ug?spm=1055.2635.3001.10343)
# 1. Orin系统的概览与调试基础
在当今快速发展的技术领域中,Orin系统因其高效和先进的特性,在工业
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )